




MSOBadger
Members
-
Joined
-
Last visited
Everything posted by MSOBadger
-
Thanks @Frank1940 ! Deleting those three files and then resetting all of the user passwords forced a re-creation of those three files. Then, just to be safe, I deleted my stored Windows Credential and rebooted the Windows PC so that it wasn't using anything cached again. I was then able to access the shared directories on the Unraid server that were set to Public. So that's a great step in the right direction! I then flipped my share back to Private and assigned R/W access to my user account. I then went back to the PC and tried to load into that share again. At this point, it started an identical cycle as described in my original post (same steps and error). Flipping the share back to Public this time at least let me access it again (whereas it hadn't prior to deleting those three files). So right now I'm able to access my share... but only if it's set to Public. As a test, I temporarily set the share to Secure and gave my user account to R/W permission. However, while I was able to view the share after that, I still didn't have Write access.
-
Thanks for the reply @JorgeB . It is indeed Windows 11 Pro 24H2 (10.0.26100 Build 26100). The Windows PC is using a Microsoft account, so I had been accessing the Unraid shares via a user that I set up on unraid and then configured to match in Windows Credentials. This had been working as-expected until my Unraid flash drive crash. I read through the thread you linked as well as the Microsoft article it linked. Everything in both have already been tried / are currently configured as outlined in them: Deleted the Windows Credential for the server and re-created it. Windows 11's Group Policy already had "Microsoft network client: Digitally sign communications (always)" set to Disable (I did try changing it to Enable, applying it, and then toggling it back to Disable, but that didn't help either). Windows 11 Group Policy "Enable insecure guest logons" - I had set this to Enabled earlier this morning while trouble-shooting and it's still set to Enabled.
-
My Unraid USB drive failed and I had to recover via a backup from Unraid Connect. That forced me to reset my Unraid user account passwords as Unraid Connect backups don't store that data. I reset the user account passwords back to their previous passwords thinking this would avoid any potential issues. Since this, I'm having an issue on my main daily driver Windows 11 PC where I can no longer access the Unraid network shares. (Prior to this flash drive recovery, everything was working without issue.) I have no issue accessing the shares on my Macbook. Here's a step-by-step of what I'm experiencing when trying to access any of my Unraid network shares: Attempt to access Unraid share (either via typing in the IP address and path or via a link in quick access Windows "Enter Network Credentials" login screen pops up. I enter the credentials and click OK A "Select Certificate" screen pops up. There are four certificate options displayed (I'm not sure what any of them are - two are issued to "Microsoft Your Phone" and two are issued to "CrossDevice"). I've tried all four and all of them result in the same next step. Error message below pops up that indicates a permissions or multiple connections problem: Troubleshooting steps thus far (all of which resulted in the exact same sequence and error as outlined above): Tried multiple Unraid user accounts (including root) Tried multiple Unraid shares Windows Credential Manager - Deleted the saved credential for my Unraid IP address, rebooted PC, and tried again Net Use - tried running "net use * /delete" from an administrator command line to kill potential multiple connections, but returns "There are no entries in the list" Tried changing the Unraid SMB share to Public (Windows 11 still asks for a credential for login and ultimately follows the same sequence as above.) Used Windows Local Group Policy Editor to change Lanman Workstation "Enable insecure guest logons" to "Enabled" - Windows 11 still pops up the Network Credentials window and then fails as above. (The Windows 11 PC is on the same subnet as the Unraid server.) I'm fairly sure this a Windows / SMB thing since I can access the shares just fine on my Macbook, but I'm at wits' end trying to figure out how to solve it. Any help is greatly appreciated!
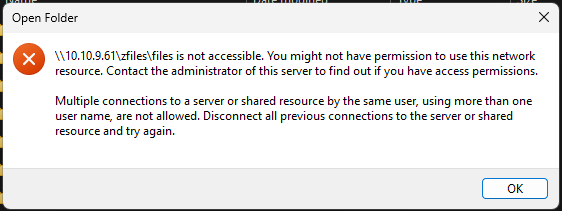
-
Thank you! This solved my issue as well. I was on the old Mover Tuning... there are actually now three different versions that show up in CA. Uninstalled the old one and was immediately able to fire Mover up again. I have about 2TB worth of moves to run, but afterwards I'll re-install the newest container release and see if Mover still works after that.
-
Thanks again @JorgeB. So far this is looking like it may have solved the problem. Logs have been holding at around 5% of max size now for the past week. I have not yet reinstalled the Connect plugin. I'll watch the logs for a bit longer to make sure the issue is resolved. If it's still all clear I'll then try reinstalling Connect and see if it comes back. I'll report back again after.
-
Thanks @JorgeB. I just uninstalled Connect and rebooted and will see how things go. I'll report back.
-
Thanks for taking a look @Squid. I'm not seeing any unexplained outliers on my Docker uptimes. All of my containers restarted between 6-7 hours ago as a result of my weekly appdata backup that runs in the Tuesday-to-Wednesday overnights. The only outliers are the 5 containers that had updates that I processed about 3 hours ago. I do have two Docker Compose stacks. Would having those stacks set to Autostart: On (in addition to having their individual containers in the top Docker Containers section) set to Autostart:On cause any issues?
-
I am repeatedly having an issue where my Unraid log is filling up. My current system uptime is only 2 months and change. It looks to me like the unraid-api might be what is filling it up: Logs attached. Any help pointing me in the right direction is much appreciated! Thanks in advance! odin-diagnostics-20250101-0950.zip
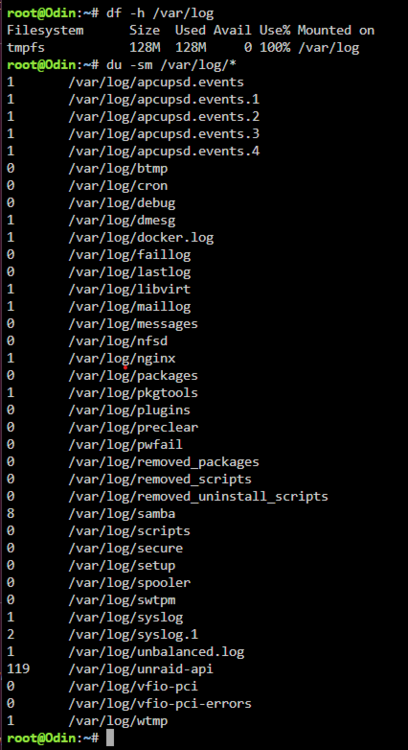
-
Same thing happened to me. Theme Engine plugin stopped working yesterday and I couldn't get anything to re-apply. Ended up removing and reinstalling the plugin after reading the above posts and that finally resolved it for me as well. (Thankfully I was just using a theme.park theme so re-configuring it after the reinstall was a two second thing.)
-
THANK you! That indeed looks to have done the trick. Mild heart attack averted.
-
A quick bit of info on my basic setup - I have one nvme pool set up to house all of my appdata and system files, a separate nvme pool for my VMs, and a third single drive setup for my generic write cache. Fix Common Problems detected that some of my appdata files were not being stored on the "nvme_docker" pool that I have setup for appdata, but rather on my separate generic cache drive (which used to be my sole cache drive/pool). In moving things around in an attempt to correct this, I think I somehow accidentally deleted the mnt/user/ directory. My Shares tab is now completely empty. I can still see all of the files when I browse to the "nvme_docker" pool in the Main tab, but the shares are gone. Is there any way to easily restore this? I have a backup of my USB from this morning (from just prior to updating to 6.12.2), is restoring to that USB backup the way to go here?
-
Thank you @JorgeB! That did the trick. Much appreciated!
-
I was updating one of my docker containers this morning and received an error in the middle of the update process. Unfortunately, I didn't record what that error said - I believe it was a connection refused error of some sort. Since closing the update window, I've been receiving an error that the "Docker Service failed to start" and all of my containers are down. At the bottom of the Dockers tab page, there are several error messages: Warning: stream_socket_client(): unable to connect to unix:///var/run/docker.sock (Connection refused) in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 682 Couldn't create socket: [111] Connection refused Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 866 Warning: stream_socket_client(): unable to connect to unix:///var/run/docker.sock (Connection refused) in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 682 Couldn't create socket: [111] Connection refused Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 932 I tried stopping and restarting the Docker service, but that hasn't resolved things. (When I change the "Enable Docker" setting to "No" and save the change, the "Status" flag in the top right corner never changes from "Running", so I'm not sure that it's ever actually trying to fully restart. The Docker tab does go away though, so maybe it is.) Perhaps something in the update process for the container I was updating corrupted my Docker file? I've attached my diagnostics logs. Any help would be greatly appreciated! vulcan-diagnostics-20220521-0636.zip
-
Excellent. Thank you again for all of the support! Much appreciated!
-
Ahh... Ok, that explains it then. I always use the rootshare when transferring files from my "downloads" share into their destination shares as it ensures all of the traffic remains local rather than going across the network from the origin server share to my device and then back to the server destination share. Thank you! Is there a better way of doing this that will keep the traffic local but respect the share settings? I'm pretty green on Linux so I generally access everything via SMB via my Windows devices.
-
The data is generally coming from the "downloads" share - manual cut/paste via a remote rootshare accessed from my laptop. I am also seeing this issue with the "movies", "wrestling" and "videos" shares (there might have been others but those are the ones I recall for sure).
-
Here are my diagnostic logs. Thank you! vulcan-diagnostics-20220411-1207.zip
-
THANK YOU! Yep, I'm sure that's it. I had that set at "Automatically split any directory as required". I assume this should instead be set to "Manual" then?
-
I'm running Unraid 6.9.2 and have been having an issue with the "Include Disk(s)" setting seemingly not properly restricting the disks that files in my shares are saving to. I have each one of my shares set to use specific disks to limit which disks get spun up for certain tasks. I've noticed however that files from these shares are ending up on disks not specified in each share's respective "Include Disk(s)" setting. For example, I have my "tv" share (which contains all of my TV episode media files) set to include disks 13 and 14. However I just found "tv" share folders with files (files relatively recently added) on disks 8, 9, and 10. So I'm using unBalance to move them all over to 13 and 14. I've found similar issues with numerous other shares. (It's not a space issue, as the specified disk groups for each share do have free space on them.) I should also note that I am not using the "Exclude Disk(s)" setting, just the Include. Has anyone else experienced this? Is there something else I need to do, settings-wise, to make this restriction work?
-
First, a huge heartfelt thank you for this awesome utility. I'm trying to clean up my share data so that each share is no longer scattered across numerous drives (so that "movies", for example, is limited to 3 drives and unraid only has to spin those drives up when movies are being accessed). I'm running into a hurdle using the Gather function however; when I get to the screen to select the Target drives to gather the share data on to, only a few drives are showing up (and they don't happen to be the drives that I want to target). I'm guessing I'm probably just missing something simple. I've disabled all of my dockers and VMs so nothing should be accessing drives. I've tried spinning up all the drives before hand as well. I have been able to work around this by slowly piecemealing the transfer by using Scatter to move share data disk-by-disk, but that's obviously a much more manual process. Any ideas? Thanks in advance!
-
THANK YOU @ghost82!! That did the trick! I was able to mount the image and get all the files backed up off of it. You are a god-send! Now to get to work on setting things back up. Thanks again!
-
Here's the output -
-
This was my problem, lol. I was pointing RealVNC to the VM's IP rather than the server host. After pointing it to the server's IP I was able to remote in and run gparted and expand the primary Windows partition. After that, I was able to boot into Windows again on the primary vdisk and the OS virtual disk now shows the full expanded size. Thanks for the help there. It looks like I'm not out of the woods yet though. With the partition resized, I went back and fired up the original instance of the VM (i.e. the one that has the second vdisk setup (i.e. my data disk for this VM), and I ended up right back in the instant-pause cycle. After some messing around, I discovered that the VM boots just fine with just the primary vdisk, but as soon as the second is added it pauses on boot. I made a copy of this vdisk2 file and tossed it on my Windows laptop and tried to mount the disk there and received a "the disk image file is corrupted" error. I've never tried mounting a vdisk that Unraid created like this before... should that work if the vdisk is working properly (meaning this vdisk2 is actually corrupted)? Or is it normal to be unable to mount a vdisk in Windows in this manner? Assuming that the vdisk is actually corrupted... is there any way to restore the data?
-
Thanks for the quick reply @ghost82! I downloaded a gparted ISO and attempted both of your suggestions above. (It took a while to backup the 200GB vdisk image first before I dove in on your suggestions.) I first tried setting up a new Win10 VM with the gparted ISO set as the OS Install ISO and the Windows vdisk from my original Win10 VM as the primary vdisk. The VM started, but I've been unable to connect to it with VNC (I've tried both Unraid's built-in noVNC web client as well as a standalone RealVNC viewer on my PC. I do see the VM's MAC address in my router log and it is pulling a valid IP address. I then tried editing my original Win10 VM so that it's OS Install ISO was set to gparted (leaving all other settings untouched) and I was unable to access that via VNC either (same results as the above attempt). Any thoughts?
-
Hello folks- I am having an issue with my Windows 10 VM - it started continually pausing on me a few days ago. After doing some researching here for others with a similar issue, it looks like the pausing happens when the drive is out of space. That indeed looks like it was the cause of my original problem, as the 70GB vdisk containing my operating system was showing as fully allocated to 70GB. So I followed a tutorial I found and started by shutting down the VM and then upping the capacity of the vdisk in Unraid's dashboard to 200GB, which should give me plenty of space. This part seems to have gone without a hitch. I restarted the VM so that I could log into Windows and perform the second step of increasing the usable drive space within Windows itself. However, here is where I'm running into an issue - I am unable to get to that step as after upping the 70GB capacity on the vdisk, and restarting the VM - the VM immediately flips into Paused status and I am unable to get into it. I've tried quitting and restarting the Windows 10 VM numerous times, I've stopped and restarted the VM system, and I've also rebooted the Unraid server itself. But still it auto-pauses immediately. I also noticed that the "allocated" space on the vdisk is no longer showing as 70GB, but rather only 15GB. The vdisk is stored on an unassigned M.2 drive with plenty of unused space (it's a 512GB drive with only 90GB used). The VM also has a second, larger, vdisk setup as an additional storage drive. That is housed on a separate M.2 drive. (I mentioning this for completeness, as I wouldn't imagine the second drive would have anything to do with this issue.) Did I nuke my VM here? Or does anyone have an idea as to how I can get back into it? Thanks! -Scott



