




Adam Kesher
Members
-
Joined
-
Last visited
Everything posted by Adam Kesher
-
thank you for the reply. i had stopped them to try to troubleshoot, should have posted after restarting. i started it and it shows no IP address at all screenshot and updated diags below. thanks for the help zigplex2-diagnostics-20220623-2110.zip

-
hi everyone, i just moved into a new house and figured when I moved i would get out from under the double nat scenario from my ISP so i requested a static and have that up and running here. i have the same config pretty much across the board, but my ISP issues their own DNS servers (dns 1 is their IP, dns 2 is 8.8.8.8) Once I booted up all of my dockers have 0.0.0.0:portnumber for all of my services and I can't figure out what I need to do in the network settings to fix it. The server computer itself is assigned the same static IP in my router and the network name is the same as the last place, i'm not sure if this could cause a conflict. any help would be appreciated. i am stressed enough with all the move haha diags attached zigplex2-diagnostics-20220621-1935.zip

-
thanks Jorge. I did give this a try and had the same result. I've been trying to back up the appdata folder so that I can start fresh with this drive formatted or just a different drive. I'm encountering trouble trying to copy it off though. Have tried via SMB and via CLI using rsync which throws up errors so i fear i'm going to lose it. i might take your advice on switching mobos. i wish i could recover my metadata though.
-
hello i posted previously about some of these issues but now they're all kind of piling up and i'm freaking out, have no idea what to do and am afraid to proceed with something where I'll lose metadata or configurations etc. any guidance on how to go about troubleshooting this would be great plex is throwing up a "plex database is corrupt" notification. i assume this is related to my other issues, possibly a docker problem too, initially laid out here thinking of moving to either another nvme device on my mobo (there is another 1tb one on the board not in use unassigned), or to a sata3 ssd if these issues seem to be nvme issues with my mobo. last time i had the disappearing disk issue i updated my mobo's bios to the latest and this has happened again. i'm not sure what the best move is, but i'm dying to fix it. i know that's a lot. zigplex2-diagnostics-20220305-1640.zip
-
maybe i should think about moving this to a regular sata3 internal SSD? i don't know how to migrate everything without losing everything and having it act as if it was the current cache. I'm super green on this. would that be advisable considering my issues? Jorge actually helped me deal with this cache disappearing but that issue occured again recently so maybe with this mobo i shouldn't have my cache on an nvme drive... also should I not be using BTRFS for the cache file system?
-
hi everyone so i had nvme related issues where my cache drive went missing. it's back, but now docker programs are failing and in cli i tried this system~# cp /boot/bzimage /mnt/cache cp: cannot create regular file '/mnt/cache/bzimage': Read-only file system Not sure what to do. I assume it's more a docker issue now. Diags included here. Thanks in advance! zigplex2-diagnostics-20220301-2126.zip
-
I stopped the array and the cache disappeared again, but on a full shutdown and then starting back up it re-appeared and i got this it auto-mounted and was correctly assigned again. this is super confusing. when i had the issue from the previous post the 'missing devices' warning happened overnight with the machine running. no restart or shutdown. diagnostics from this boot included. zigplex2-diagnostics-20211224-1218.zip

-
thanks for this. re-assigning it worked and i was up and running just fine yesterday but today i woke up to the same Cache pool BTRFS missing device(s) warning. is there anything else I can do to prevent this from happening? when i ran the scrub yesterday there were no errors. very frustrating. all the help has been great. zigplex2-diagnostics-20211224-1116.zip
-
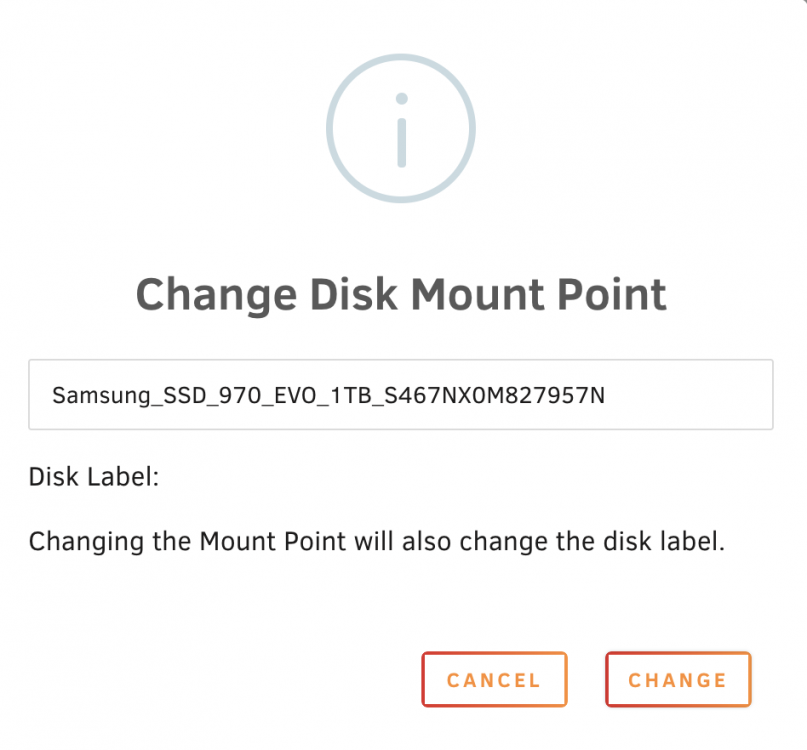
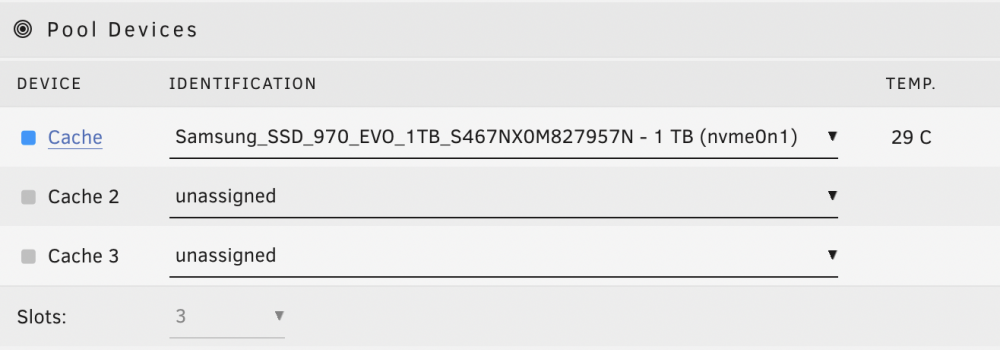
it is a single cache. when i stop the array to re-assign it this is how it appears in unassigned devices if i click that blue disk name i get this when i assign it to the cache pool, this historical devices shows up is this something i need to be worried about before starting the array with the disk put back in the cache pool (formatting or anything like that?) do I need to change the disk mount point first? or do I just assign the disk? Thanks for all your help everyone I am just paranoid.


-
ok i ran it again adn this time that same upstream timeout error popped up but this time i also got the pop up window for the scrub only says this (though it did say 'transferring data from IP' for a bit attaching diagnostics after all this zigplex2-diagnostics-20211222-1859.zip
-
so i did try this, tried the scrub and got this in the log. Changed the last digits of the local IPs...,but that XX ending IP is an old IP that this server had before I gave it a dedicated IP on my router at YY. Could this be part of the issue, or just an issue running the scrub?
-
hi everyone, So I had a weird sequence of events happen here with my cache disk. I got a cache pool btrfs missing warning for my cache disk. I then ran scrub with fix errors checked. Still showed the error. Then I stopped the array and restarted. It disappeared when I restarted the array. Then I restarted my whole unraid system and now it is showing up in unassigned devices. Hoping it can be remounted or salvaged somehow. I have diagnostics here. I screenshotted how it appears. It's the dev3 device. any help would be great. thank you zigplex2-diagnostics-20211222-1430.zip








