

Smolo
-
Posts
299 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Smolo
-
-
I'm completely at a loss, I've never had anything like this before. Theoretically it can only be the power supply(?), memory, NVME or mainboard.
I've already ordered a new power supply, but I can't really imagine what's going on anymore.
The memory shouldn't play a role at this point, should it?
-
@Jorge
I have now deleted some data but unfortunately the next scrub will show new files as corrupt? The docker file is also affected, how can I restore it or have it recreated?
To be honest, I don't really understand why btrfs and a raid 1 system and two ECC RAMs play such an important role?
:-( -
@Jorge
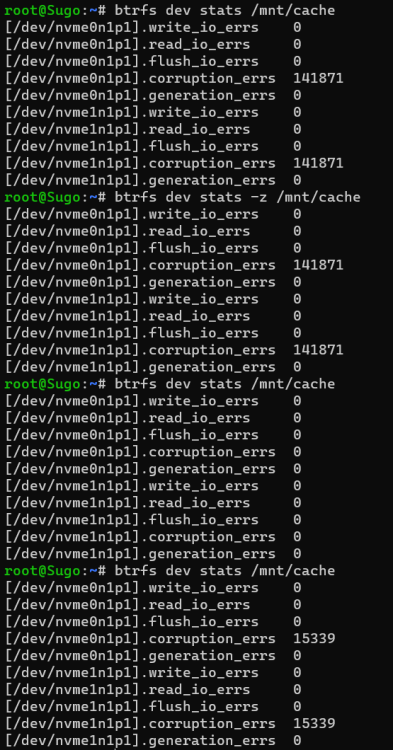
Last Stats after scrub
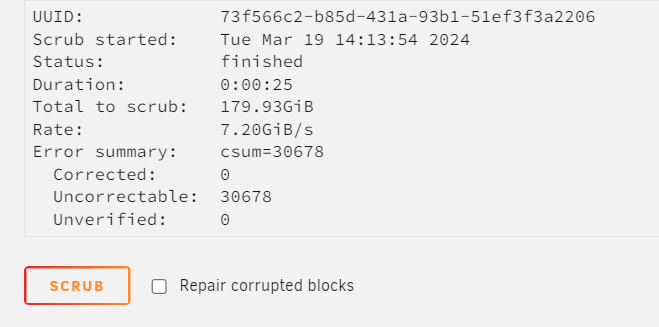
-
23 hours ago, JorgeB said:
Mar 10 17:11:54 Sugo kernel: BTRFS info (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 122, gen 0 Mar 10 17:11:54 Sugo kernel: BTRFS info (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 122, gen 0Btrfs is detecting data corruption on both pool devices, start by running memtest.
I have now run it twice without any results. The first run took over 14 hours. On the second run I reset all BIOS values beforehand without any errors.
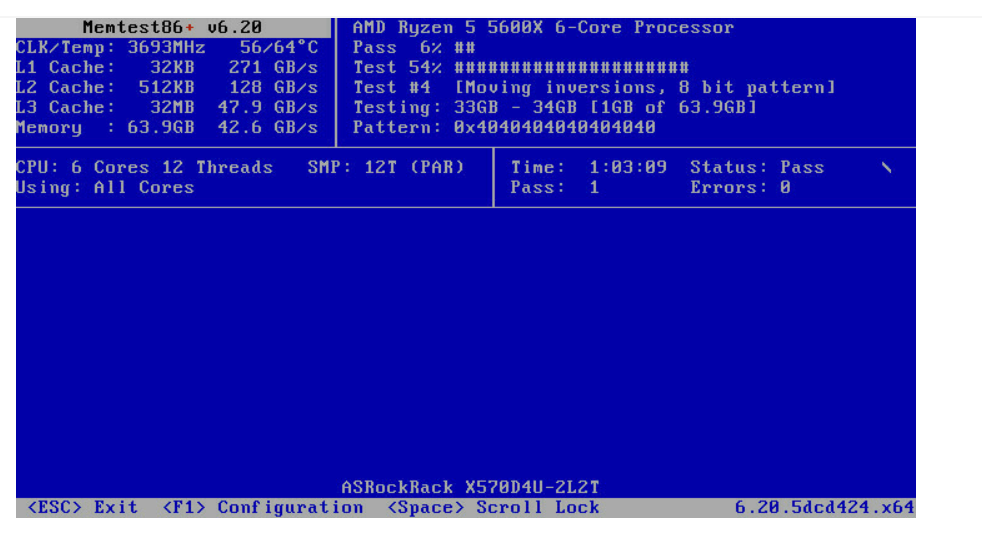
-
Here the same problem Cache Pool no longer accessible after a restart.
I was able to solve it with btrfs rescue zero-log /dev/nvme1n1p1. Unfortunately the same error came back after a few days.
I then ran btrfs resuce zero-log again and wanted to move the data to the array via the mover. Unfortunately, I have massive access errors. Can you possibly help?
Mar 18 01:03:07 Sugo kernel: btrfs_print_data_csum_error: 1494 callbacks suppressed
Mar 18 01:03:07 Sugo kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 36649273 off 0 csum 0x8941f998 expected csum 0x36d489f9 mirror 1
Mar 18 01:03:07 Sugo kernel: btrfs_dev_stat_inc_and_print: 1494 callbacks suppressed
Mar 18 01:03:07 Sugo kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 25951, gen 0
Mar 18 01:03:07 Sugo kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 36649273 off 4096 csum 0x8941f998 expected csum 0xa4cb39d0 mirror 1Translated with DeepL.com (free version)
-
Sehr ausführliche Antwort erstmal besten Dank hierfür.
Zur Hardware es handelt sich hier um eine 16TB HDD und nicht die SSD aus dem ursprünglichen Problemfall. Ich tippe mittlerweile auch auf ein Hardware Problem bin aber etwas überfragt.
- Kabel kann ich mir nicht so recht vorstellen hatte ich nie Probleme mit
- Netzteil könnte ich mir am ehesten noch vorstellen das des zu wenig Dunst hat?!
- Defektes Mainboard / Controller wäre natürlich nen Totalschaden das kann ich mir aber auch weniger vorstellen.
Hotswap wäre mal eine Idee zum deaktivieren.
Kann jemand anderes was bezüglich ATA / SATA Meldung im Log sagen und ob das in Ordnung ist?
Bezüglich Bau immer noch mitten drin statt nur dabei aber so langsam biegen wir auf die Ziellinie ein ist halt derb wenn man alles selbst macht und das Objekt bissel größer ist
")
-
Muss den Thread leider noch mal ausbuddeln.... kann damit jemand was anfangen?
Start einer Kopieraktion auf eine neue Platte die nur gemounted ist? Nach 1min kopierne = grätsche und Platte ist weg?
Dec 21 00:21:18 Sugo emhttpd: read SMART /dev/sdb Dec 21 00:24:14 Sugo kernel: ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen Dec 21 00:24:14 Sugo kernel: ata1.00: failed command: FLUSH CACHE EXT Dec 21 00:24:14 Sugo kernel: ata1.00: cmd ea/00:00:00:00:00/00:00:00:00:00/a0 tag 7 Dec 21 00:24:14 Sugo kernel: res 40/00:00:00:00:00/00:00:00:00:00/40 Emask 0x4 (timeout) Dec 21 00:24:14 Sugo kernel: ata1.00: status: { DRDY } Dec 21 00:24:14 Sugo kernel: ata1: hard resetting link Dec 21 00:24:19 Sugo kernel: ata1: link is slow to respond, please be patient (ready=0) Dec 21 00:24:24 Sugo kernel: ata1: found unknown device (class 0) Dec 21 00:24:24 Sugo kernel: ata1: softreset failed (device not ready) Dec 21 00:24:24 Sugo kernel: ata1: hard resetting link Dec 21 00:24:29 Sugo kernel: ata1: link is slow to respond, please be patient (ready=0) Dec 21 00:24:34 Sugo kernel: ata1: found unknown device (class 0) Dec 21 00:24:34 Sugo kernel: ata1: softreset failed (device not ready) Dec 21 00:24:34 Sugo kernel: ata1: hard resetting link Dec 21 00:24:39 Sugo kernel: ata1: link is slow to respond, please be patient (ready=0) Dec 21 00:24:44 Sugo kernel: ata1: found unknown device (class 0) Dec 21 00:24:50 Sugo kernel: ata1: link is slow to respond, please be patient (ready=0) Dec 21 00:25:09 Sugo kernel: ata1: softreset failed (device not ready) Dec 21 00:25:09 Sugo kernel: ata1: limiting SATA link speed to 3.0 Gbps Dec 21 00:25:09 Sugo kernel: ata1: hard resetting link Dec 21 00:25:14 Sugo kernel: ata1: found unknown device (class 0) Dec 21 00:25:14 Sugo kernel: ata1: softreset failed (device not ready) Dec 21 00:25:14 Sugo kernel: ata1: reset failed, giving up Dec 21 00:25:14 Sugo kernel: ata1.00: disable device Dec 21 00:25:14 Sugo kernel: ata1: EH complete Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#16 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=122s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#16 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3c f7 00 00 00 0a 00 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 3995392 op 0x1:(WRITE) flags 0x104000 phys_seg 49 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#17 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#17 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 01 00 00 00 00 38 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 3997952 op 0x1:(WRITE) flags 0x100000 phys_seg 5 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#18 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=122s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#18 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 15032387032 op 0x1:(WRITE) flags 0x9800 phys_seg 1 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#19 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#19 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 01 38 00 00 0a 00 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 3998008 op 0x1:(WRITE) flags 0x104000 phys_seg 168 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#20 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#20 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 0b 38 00 00 05 80 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 4000568 op 0x1:(WRITE) flags 0x104000 phys_seg 88 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#21 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#21 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 10 b8 00 00 08 48 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 4001976 op 0x1:(WRITE) flags 0x100000 phys_seg 70 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#22 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#22 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 19 00 00 00 05 b0 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 4004096 op 0x1:(WRITE) flags 0x104000 phys_seg 168 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#23 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#23 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 1e b0 00 00 05 80 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 4005552 op 0x1:(WRITE) flags 0x100000 phys_seg 88 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#31 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#31 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 24 30 00 00 0a 00 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 4006960 op 0x1:(WRITE) flags 0x104000 phys_seg 160 prio class 2 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=DRIVER_OK cmd_age=0s Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#0 CDB: opcode=0x8a 8a 00 00 00 00 00 00 3d 2e 30 00 00 06 00 00 00 Dec 21 00:25:14 Sugo kernel: I/O error, dev sdb, sector 4009520 op 0x1:(WRITE) flags 0x100000 phys_seg 96 prio class 2 Dec 21 00:25:14 Sugo kernel: XFS (sdb1): log I/O error -5 Dec 21 00:25:14 Sugo kernel: sdb: detected capacity change from 31251759104 to 0 Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#14 access beyond end of device Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#15 access beyond end of device Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#16 access beyond end of device Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#17 access beyond end of device Dec 21 00:25:14 Sugo kernel: XFS (sdb1): Filesystem has been shut down due to log error (0x2). Dec 21 00:25:14 Sugo kernel: sd 1:0:0:0: [sdb] tag#18 access beyond end of device Dec 21 00:25:14 Sugo kernel: XFS (sdb1): Please unmount the filesystem and rectify the problem(s). Dec 21 00:25:14 Sugo kernel: sdb1: writeback error on inode 137, offset 171966464, sector 3997952 Dec 21 00:25:14 Sugo kernel: sdb1: writeback error on inode 137, offset 180355072, sector 4005552 Dec 21 00:25:14 Sugo kernel: sdb1: writeback error on inode 137, offset 188743680, sector 4030720 Dec 21 00:25:14 Sugo kernel: sdb1: writeback error on inode 137, offset 197132288, sector 4041984 Dec 21 00:25:14 Sugo kernel: sdb1: writeback error on inode 137, offset 201326592, sector 4044992 Dec 21 00:25:14 Sugo kernel: XFS (sdb1): log I/O error -5 Dec 21 00:25:14 Sugo kernel: XFS (sdb1): log I/O error -5 Dec 21 00:25:14 Sugo kernel: XFS (sdb1): log I/O error -5 Dec 21 00:25:14 Sugo kernel: XFS (sdb1): log I/O error -5 -
Mal eine kurze Frage an die Backup Front ich bin wohl der zahlreichen Software Lösungen und wenig Zeit etwas überfordert.
Mein Ziel
Von 2-3 PCs (Server/Clients) spezifische Verzeichnisse vom Server aus (Pull) per Scheduler zu sichern. Nur wenn nicht anders möglich mit Clientlösung.
Das ganze sollte per Webinterface konfigurierbar sein und wegen Ransomware Möglichkeit im TimeMachine Modus.
Gibts da was bzw. was könnt ihr empfehlen?
-
Kurzes Update zu meiner Havarie.
Der Hinweis von @JorgeB die emulierte Platte über den nachfolgenden Befehl zu bereinigen war genau die richtige Lösung. Thanks JorgeB.
xfs_repair -vL /dev/md4Natürlich auch an alle anderen vielen lieben Dank für den Support!
Zurück zum Thema mir stellen sich hier noch zwei entscheidende Fragen:
1) Es sieht zwar so aus als wenn die Daten wieder da sind aber genau Wissen kann ich es leider nicht. D.h. wenn es das XFS Dateisystem zerlegt kann es trotz Parität zu einem Datenverlust kommen soweit mein aktuelles Verständnis?
2) Ich mache zur Sicherheit noch eine 1:1 Kopie auf eine extra Platte außerhalb des Arrays die 16TB sind schon unterwegs. Aber wie hänge ich die SSD wieder ins Array rein einfach formierten und wieder als Disk 4 hinterlegen?
-
Gewerke vergeben?! Das sind wir zwei Irren (Vater + me) 😁 Bis auf ein paar spezielle Themen (Dach, Putz) machen wir alles allein...hab dieses Jahr schon 80-100m³ Beton gepumpt
wird ein Niedrigenergie/Passivhaus.
Nachbarn gibts nur bedingt ist ein Neubaugebiet 250m neben nem See. Wir sind eigentlich 18hx7 aufm Bau. Nur der Arzt 150m weiter hat sich mal etwas Lautstark beschwert als ich Sa 20.30 bei Regen die Fenster mit nem 250er Trennjäger bearbeitet hab😂
-
18 minutes ago, mgutt said:
Photorec, also auch von den Testdisk Leuten. Du kannst dich dann allerdings von den Dateinamen verabschieden. Bei XFS sind die nicht wiederherstellbar. Das geht nur bei BTRFS und dem Kommando btrfs restore.
Was du machen kannst, um die Disk nicht anfassen zu müssen:
dd if=/dev/sdb of=/mnt/disk1/sdb.img bs=128k
Dann hast du schon mal das Image von der kompletten Disk ohne Änderungen. Dieses Image könnte man nun mounten oder zb auch an eine VM als zweite vdisk übergeben. Wenn du zb mit knoppix die Disk analysieren willst.
Photorec hab ich schon gesehen eventuell zieh ich die Daten damit erstmal wenn möglich. Dateinamen sind egal Hauptsache der Content ist wieder da.
Bin erstmal aufm Bau muss da Abend weitermachen. Danke.
-
12 minutes ago, hawihoney said:
Du hast die Grundzüge der Parity nicht verstanden. Da wird nichts vorgehalten. Das ist kein Backup. Die Parity bietet Ausfallsicherheit.
Ich habe mich falsch ausgedrückt das ist mir schon klar was die Parity macht in dem Kontext.
Das Problem ist doch das es mir wegen einem HW Fehler anscheinend das Dateisystem zerlegt hat und die Parity das nicht rafft und ohne Fehler durchläuft und das kann ich nicht verstehen an dieser Stelle.
-
19 minutes ago, JorgeB said:
Zeroing the log is IMHO your best bet but since the SSD is also being emulated you can repair that filesystem instead if you want and leave the original device untouched:
-start the array in maintenance mode and type
xfs_repair -vL /dev/md4-when done stop array
-start array in normal mode and the emulated disk4 should now mount, check contents
Does the XFS protocol now only refer to the emulated disk? Will I somehow get the discs back together when I run this?
-
14 minutes ago, hawihoney said:
Aber Du siehst Ordner mit "ls -la /mnt/disk4/"? Und Du kannst mit "cd /mnt/disk4/Ordner/" in einen dieser Ordner hinein wechseln und dann mit "ls -la" den (leeren) Inhalt von diesem Ordner aufrufen ohne das eine Fehlermeldung erscheint?
Das ist wichtig, denn das bedeutet, dass die emulierte Disk4 offensichtlich nicht ganz im Eimer ist. Der Inhalt von Disk4 im Array mag dann weg sein, aber die Disk4 muss nicht zum Abschluss neu eingerichtet werden.
Wenn ja: Alle weitergehenden Arbeiten konzentrieren sich jetzt auf die außerhalb des Arrays stehende Disk4. Alles was dort rekonstruiert werden kann, könnte auf die emulierte Disk kopiert werden. Letzteres nur wenn Du wie oben geschrieben Ordner unterhalb von /mnt/disk4 siehst.
Zieh dann aber jedes mal ein Backup für die Zwischenstände. Ist ja nur eine 4 TB Disk
Ja es erscheint kein Fehler und das Verzeichnis ist leer das ist so weit korrekt. Soweit mein aktuelles Verständnis reicht bin ich da aber doch doppelt gekniffen denn das bedeutet die Parity hält die Daten nicht vor und auf der Disk4 kann ich auch nicht direkt/indirekt zugreifen. Warum sollte ich jetzt Daten von DIsk4 rekonstrurieren und auf die emulierte Disk schreiben da bin ich gedanklich jetzt vollkommen raus vom Verständnis?
Das mit dem Backup ziehen ist leichter gesagt als getan....ich bin nicht Daheim wo mein ganzer IT Stuff liegt und hab hier nur einen alten Laptop mit einem USB Port🤪...baue grad Häuschen in Eigenleistung 500km entfernt und die ganzen Baubilder liegen in dem Ordner weil ich diese noch nicht ins 3fach gesicherte Storage schieben konnte 😐
Wie ziehe ich denn am leichtesten unter Linux eine 1:1 Bit Kopie einer Platte direkt unter Unraid geht das auch in virtuelle Abbilder? Am liebsten würde ich die Platte zum Datenrestore einschicken es geht eigentlich nur um 50GB Bilder der Rest waren nur x fach gesicherte Kopien auf der Platte die sind mir total wurscht aber der Rest umso wichtiger.
-
2 hours ago, mgutt said:
Ok, dann bitte wie empfohlen die xfs logs entfernen, dann noch mal Reparatur versuchen und wenn das auch nicht hilft, mit testdisk sein Glück versuchen.
Wegen der nicht gemeldeten kaputten Disk: Steht denn was in den Logs von vor dem Update? Kannst du mir auch gerne per PN senden.
Die fehlenden Daten sind extrem wichtig ich bin grad echt unschlüssig was ich tun soll. Irgendwelche Aktionen auf der Platte durchführen und in Kauf nehmen das die Daten überschrieben werden oder volles Risiko fahren und hoffen das die Struktur wiederhergestellt werden kann? Was mich in dem Fall so wundert das ich in der emulierten Disk leere Verzeichnisse bekomme auf nahezu TopLevel Ebene.
Kennt jemand von euch ein gutes Datenwiederherstellungstool auf OS Basis?
So wie es aussieht habe ich beim Stöbern in den Logs folgendes entdeckt:
Nov 10 00:36:09 Sugo kernel: XFS (md4): Corruption detected. Unmount and run xfs_repair Nov 10 00:36:09 Sugo kernel: XFS (md4): Failed to recover intents Nov 10 00:36:09 Sugo kernel: XFS (md4): Filesystem has been shut down due to log error (0x2). Nov 10 00:36:09 Sugo kernel: XFS (md4): Please unmount the filesystem and rectify the problem(s). Nov 10 00:36:09 Sugo kernel: XFS (md4): Ending recovery (logdev: internal) Nov 10 00:36:09 Sugo kernel: XFS (md4): log mount finish failed Nov 10 00:36:09 Sugo root: mount: /mnt/disk4: mount(2) system call failed: Structure needs cleaning. Nov 10 00:36:09 Sugo root: dmesg(1) may have more information after failed mount system call. Nov 10 00:36:09 Sugo emhttpd: shcmd (31): exit status: 32 Nov 10 00:36:09 Sugo emhttpd: /mnt/disk4 mount error: Wrong or no file system Nov 10 00:36:09 Sugo emhttpd: shcmd (34): umount /mnt/disk4 Nov 10 00:36:09 Sugo root: umount: /mnt/disk4: not mounted. Nov 10 00:36:09 Sugo emhttpd: shcmd (34): exit status: 32 Nov 10 00:36:09 Sugo emhttpd: shcmd (35): rmdir /mnt/disk4 Nov 10 00:36:09 Sugo emhttpd: shcmd (36): mkdir -p /mnt/cache Nov 10 00:36:09 Sugo emhttpd: /mnt/cache uuid: 73f566c2-b85d-431a-93b1-51ef3f3a2206 Nov 10 00:36:09 Sugo emhttpd: /mnt/cache (null) Nov 10 00:36:09 Sugo emhttpd: /mnt/cache (null) Nov 10 00:36:09 Sugo emhttpd: /mnt/cache (null) Nov 10 00:36:09 Sugo emhttpd: /mnt/cache (null) Nov 10 00:36:09 Sugo emhttpd: /mnt/cache found: 2 Nov 10 00:36:09 Sugo emhttpd: /mnt/cache extra: 0 Nov 10 00:36:09 Sugo emhttpd: /mnt/cache missing: 0
D.h. direkt nach dem Update hat es das Dateisystem zerlegt?
-
2 hours ago, ich777 said:
So, hatte kurz Zeit, hab es auch kompiliert aber ich hab dann mal mit un-get gesucht und auch gefunden.
Um es in gang zu bekommen einfach un-get installieren und dann:
un-get update un-get install testdisk libewf
(libewf brauchst damit testidsk läuft)
Danach kannst:
testdisk
ganz normal ausführen.
Zum löschen einfach wieder:
un-get remove testdisk libewf
Super vielen Dank mit dem Thema sehe ich wengistens wo er steht....Testdisk unter Windows mit USB angeschlossen hat keine Anzeige gehabt vom aktuellen Status jetzt lasse ich noch mal den Depper Search laufen.
-
3 hours ago, hawihoney said:
Und genau so muss es sein.
Disk4 wird nun emuliert. Das degradierte Array zeigt nun "seinen" aktuellen Wissensstand. Dieser unterscheidet sich nicht von dem "Wissen" mit defekter Disk4.
Jetzt mal auf die emulierte Disk4 zugreifen (ls -la /mnt/disk4 oder mc aufrufen). Was siehst Du?
Danach guckst Du was den Inhalt des Arrays angeht und machst ggfs. ein Backup.
Das Problem ist das in den Ordnern nichts enthalten ist einfach nur gähnende Leere.
-
21 minutes ago, jj1987 said:
Kommt drauf an, was du beim Parity Check eingestellt hast. Fehler korrigieren oder nicht.
Bin mir gerade nicht sicher was der Standard Wert ist, ich hab's bei mir auf alle Fälle auf deaktiviert stehen
Die Option ist bei mir auch deaktiviert das erklärt dann aber nicht wo die Daten hin sind.
17 minutes ago, jj1987 said:Die Parity kann nur den Ausfall einer Disk abfangen, da Disk 4 raus ist = kein Schutz vor weiteren Ausfällen bis Wiederherstellung Disk 4 bzw neuer Parity
Ach ich war durch die Anzeige der Disk 1 im Fotos Share irritiert aber das ist die Disk Ausnahme. Danke bin schon voll im Daten Worst Case Wahnsinn untwegs^^
-
Also Starten ohne eingehange Platte war gar keine gute Idee. Wenn ich die Platte wieder reinhänge erkennt er diese jetzt nicht mehr und will Sie als neues Device reinpacken.

Per UnassginedPlugin habe ich jetzt aber folgendes gefunden?

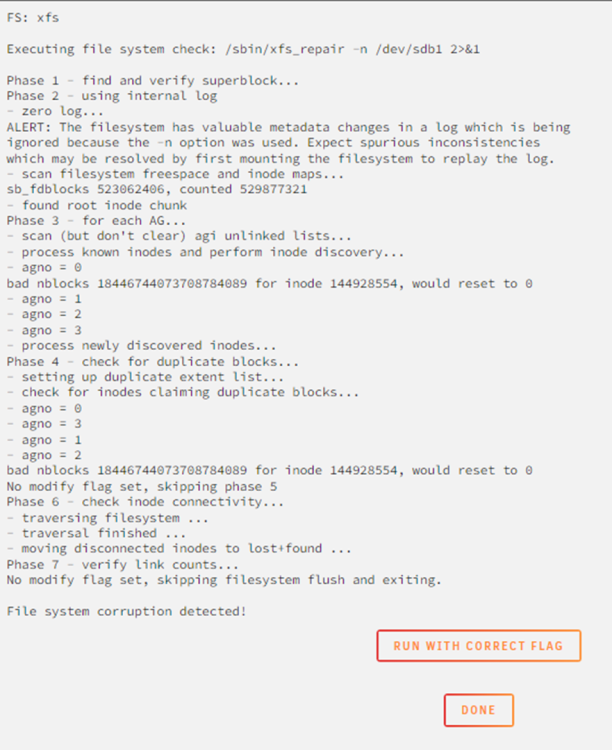
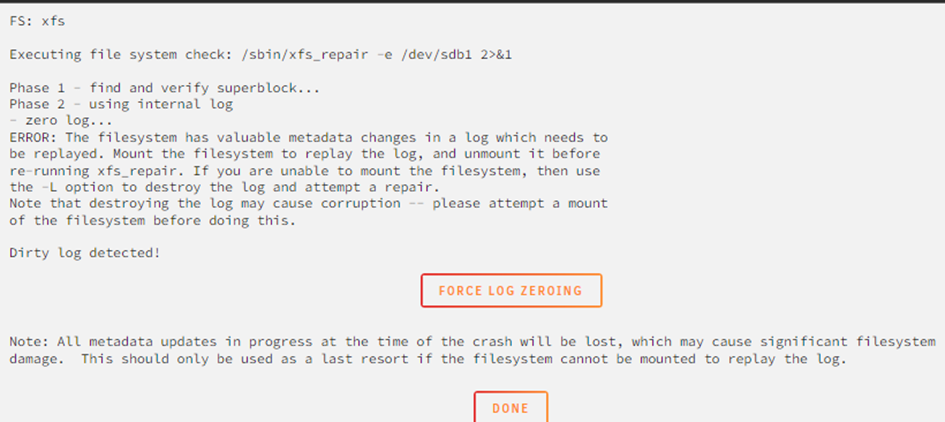
-
Kann mir das jemand erklären wie die anderen Disks ungeschützt sein können wenn die 4er nicht existent ist und er sagt die 1er spinnt?

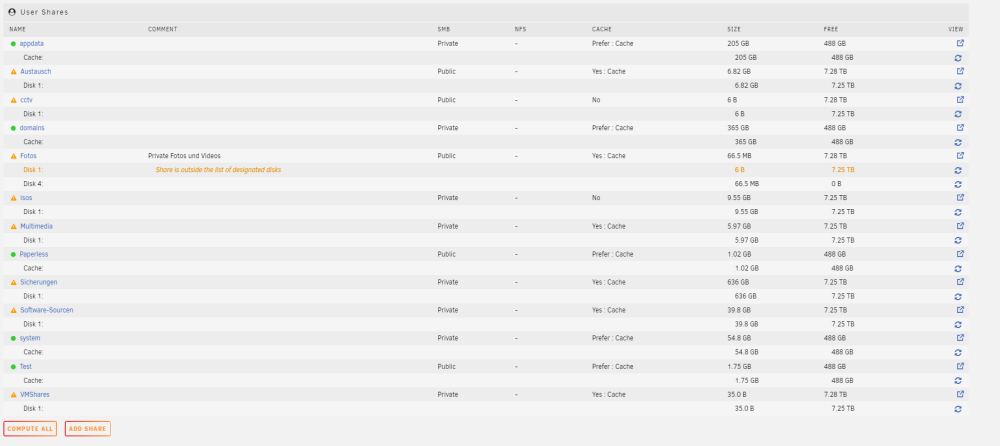
-
51 minutes ago, hawihoney said:
Ich würde wirklich mal testen was passiert wenn das Array ohne besagte Platte im Maintenance Mode gestartet wird. Nix schreiben, nur lesen. Wird die Platte emuliert? Werden die Daten emuliert? Wird das Array als "degraded" angezeigt? Oder wurde eine defekte/leere/unformatierte Platte in die Parity geschrieben?
Wenn ich das System hochfahre ohne die Platte sieht es wie folgt aus:
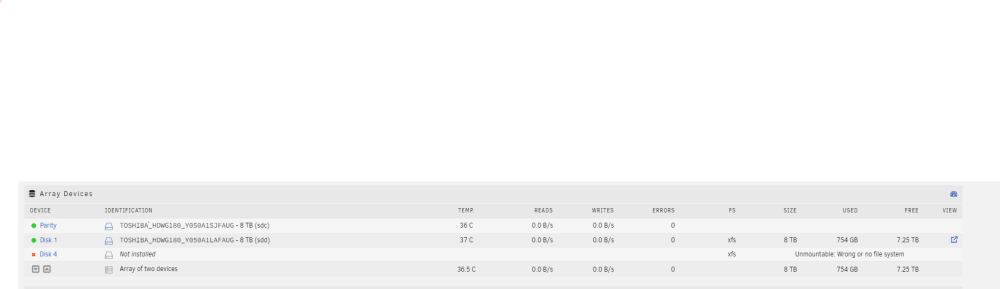
Es sind dann zwei Ordner da aber leider ist im "Bilder" Ordner nichts mehr enthalten. Im photoprism Ordner sind noch ein paar Thumbs und YML Dateien existient
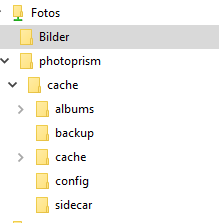
-
33 minutes ago, hawihoney said:
Aber angeboten vor dem Start. Nach dem Start wird dann formatiert.
Ich würde wirklich mal testen was passiert wenn das Array ohne besagte Platte im Maintenance Mode gestartet wird. Nix schreiben, nur lesen. Wird die Platte emuliert? Werden die Daten emuliert? Wird das Array als "degraded" angezeigt? Oder wurde eine defekte/leere/unformatierte Platte in die Parity geschrieben?
Über die Gründe kann man nur spekulieren. Mir ist noch nie (!!!) eine Harddisk fliegen gegangen ohne das Unraid das merkt. Ich hatte aber schon mehrere Ausfälle von SSD- und NVMe Disks die nicht zur Kenntnis genommen wurden. Das letzte mal vor 2 Wochen.
Nachtrag: Du bist jetzt auf 6.9.1?
Version habe ich aus der Signatur rausgeschmissen bin jetzt bei 6.11.2.
Ich habe grad den "genauen" Ablauf in meinen Telegram Meldungen gefunden:
- Update eingespielt
- Parity Check started
- Fix Common Problems meldet ein Problem mit der DISK
- Parity Check läuft ohne Problem durch?!
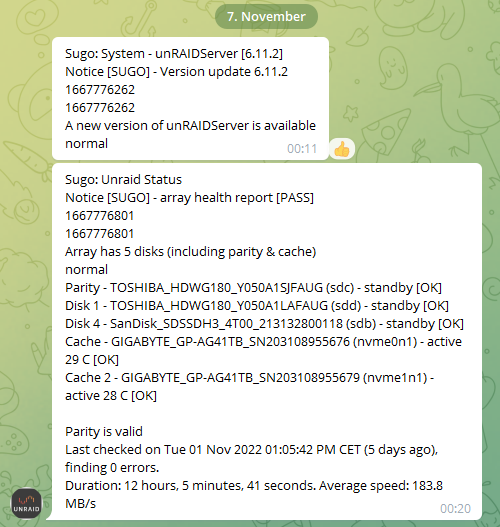
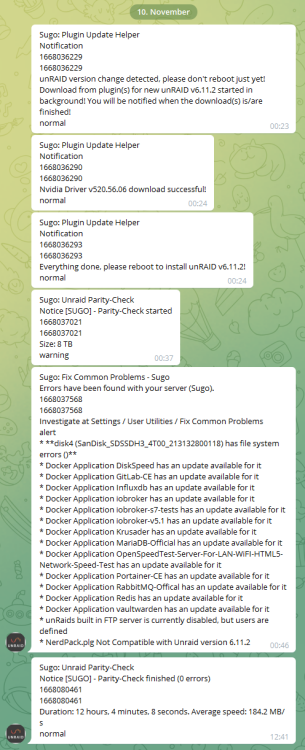
Wie kann man denn einen Ausfall einer Platte nicht zur Kenntnis nehmen? Und selbst wenn dürfte Unraid niemals aber niemals einfach die aktuelle Parität wegschmeißen!!!
-
Also ich hatte die Platte rausgenommen und am Laptop Testdisk ausgeführt der Quick Check hat folgendes gesagt:
Sat Nov 12 10:18:06 2022 Command line: TestDisk TestDisk 7.2-WIP, Data Recovery Utility, November 2022 Christophe GRENIER <[email protected]> https://www.cgsecurity.org OS: Windows 8 (9200) Compiler: GCC 11.2, Cygwin32 3001.4 ext2fs lib: 1.45.3, ntfs lib: 10:0:0, reiserfs lib: none, ewf lib: 20140608, curses lib: ncurses 6.1 disk_get_size_win32 IOCTL_DISK_GET_LENGTH_INFO(\\.\PhysicalDrive0)=256060514304 disk_get_size_win32 IOCTL_DISK_GET_LENGTH_INFO(\\.\PhysicalDrive1)=4000787030016 disk_get_size_win32 IOCTL_DISK_GET_LENGTH_INFO(\\.\C:)=254641487360 Hard disk list Disk \\.\PhysicalDrive0 - 256 GB / 238 GiB - CHS 31130 255 63, sector size=512 - SAMSUNG MZMTD256HAGM-000MV, S/N:S1GLNYADC01343, FW:DXT43M0Q Disk \\.\PhysicalDrive1 - 4000 GB / 3726 GiB - CHS 486401 255 63, sector size=512 - SanDisk SDSSDH3 4T00, S/N:060032200240 Partition table type (auto): EFI GPT Disk \\.\PhysicalDrive1 - 4000 GB / 3726 GiB - SanDisk SDSSDH3 4T00 Partition table type: EFI GPT Analyse Disk \\.\PhysicalDrive1 - 4000 GB / 3726 GiB - CHS 486401 255 63 hdr_size=92 hdr_lba_self=1 hdr_lba_alt=7814037167 (expected 7814037167) hdr_lba_start=34 hdr_lba_end=7814037134 hdr_lba_table=2 hdr_entries=128 hdr_entsz=128 Current partition structure: 1 P Linux filesys. data 2048 7814037134 7814035087 Backup partition structure partition_save search_part() Disk \\.\PhysicalDrive1 - 4000 GB / 3726 GiB - CHS 486401 255 63 XFS Marker at 0/32/33 recover_xfs Linux filesys. data 2048 7814037127 7814035080 XFS CRC enabled, blocksize=4096, 4000 GB / 3726 GiB file_win32_pread(604,1,buffer,3519069836(486401/80/28)) read err: read after end of file file_win32_pread(604,1,buffer,3519069837(486401/80/29)) read err: read after end of file file_win32_pread(604,14,buffer,3519069838(486401/80/30)) read err: read after end of file file_win32_pread(604,3,buffer,3519069852(486401/80/44)) read err: read after end of file file_win32_pread(604,1,buffer,3519069855(486401/80/47)) read err: read after end of file file_win32_pread(604,1,buffer,3519069856(486401/80/48)) read err: read after end of file file_win32_pread(604,1,buffer,3519069857(486401/80/49)) read err: read after end of file file_win32_pread(604,1,buffer,3519069840(486401/80/32)) read err: read after end of file file_win32_pread(604,1,buffer,3519069841(486401/80/33)) read err: read after end of file file_win32_pread(604,14,buffer,3519069842(486401/80/34)) read err: read after end of file file_win32_pread(604,1,buffer,3519069858(486401/80/50)) read err: read after end of file file_win32_pread(604,1,buffer,3519069856(486401/80/48)) read err: read after end of file file_win32_pread(604,1,buffer,3519069859(486401/80/51)) read err: read after end of file file_win32_pread(604,1,buffer,3519069857(486401/80/49)) read err: read after end of file file_win32_pread(604,1,buffer,3519069860(486401/80/52)) read err: read after end of file file_win32_pread(604,1,buffer,3519069843(486401/80/35)) read err: read after end of file file_win32_pread(604,1,buffer,3519069844(486401/80/36)) read err: read after end of file file_win32_pread(604,14,buffer,3519069845(486401/80/37)) read err: read after end of file file_win32_pread(604,1,buffer,3519069861(486401/80/53)) read err: read after end of file file_win32_pread(604,1,buffer,3519069859(486401/80/51)) read err: read after end of file file_win32_pread(604,1,buffer,3519069862(486401/80/54)) read err: read after end of file file_win32_pread(604,1,buffer,3519069860(486401/80/52)) read err: read after end of file file_win32_pread(604,1,buffer,3519069863(486401/80/55)) read err: read after end of file file_win32_pread(604,1,buffer,3519069846(486401/80/38)) read err: read after end of file file_win32_pread(604,1,buffer,3519069847(486401/80/39)) read err: read after end of file file_win32_pread(604,14,buffer,3519069848(486401/80/40)) read err: read after end of file file_win32_pread(604,1,buffer,3519069864(486401/80/56)) read err: read after end of file file_win32_pread(604,1,buffer,3519069862(486401/80/54)) read err: read after end of file file_win32_pread(604,1,buffer,3519069865(486401/80/57)) read err: read after end of file file_win32_pread(604,1,buffer,3519069863(486401/80/55)) read err: read after end of file file_win32_pread(604,1,buffer,3519069866(486401/80/58)) read err: read after end of file file_win32_pread(604,1,buffer,3519069849(486401/80/41)) read err: read after end of file file_win32_pread(604,1,buffer,3519069850(486401/80/42)) read err: read after end of file file_win32_pread(604,14,buffer,3519069851(486401/80/43)) read err: read after end of file file_win32_pread(604,1,buffer,3519069867(486401/80/59)) read err: read after end of file file_win32_pread(604,1,buffer,3519069865(486401/80/57)) read err: read after end of file file_win32_pread(604,1,buffer,3519069868(486401/80/60)) read err: read after end of file file_win32_pread(604,1,buffer,3519069866(486401/80/58)) read err: read after end of file file_win32_pread(604,1,buffer,3519069869(486401/80/61)) read err: read after end of file file_win32_pread(604,1,buffer,3519069852(486401/80/44)) read err: read after end of file file_win32_pread(604,1,buffer,3519069853(486401/80/45)) read err: read after end of file file_win32_pread(604,14,buffer,3519069854(486401/80/46)) read err: read after end of file file_win32_pread(604,1,buffer,3519069870(486401/80/62)) read err: read after end of file file_win32_pread(604,1,buffer,3519069868(486401/80/60)) read err: read after end of file file_win32_pread(604,1,buffer,3519069871(486401/80/63)) read err: read after end of file file_win32_pread(604,1,buffer,3519069869(486401/80/61)) read err: read after end of file file_win32_pread(604,1,buffer,3519069855(486401/80/47)) read err: read after end of file file_win32_pread(604,1,buffer,3519069856(486401/80/48)) read err: read after end of file file_win32_pread(604,14,buffer,3519069857(486401/80/49)) read err: read after end of file file_win32_pread(604,1,buffer,3519069871(486401/80/63)) read err: read after end of file file_win32_pread(604,1,buffer,3519069858(486401/80/50)) read err: read after end of file file_win32_pread(604,1,buffer,3519069859(486401/80/51)) read err: read after end of file file_win32_pread(604,14,buffer,3519069860(486401/80/52)) read err: read after end of file file_win32_pread(604,1,buffer,3519069861(486401/80/53)) read err: read after end of file file_win32_pread(604,1,buffer,3519069862(486401/80/54)) read err: read after end of file file_win32_pread(604,14,buffer,3519069863(486401/80/55)) read err: read after end of file file_win32_pread(604,1,buffer,3519069864(486401/80/56)) read err: read after end of file file_win32_pread(604,1,buffer,3519069865(486401/80/57)) read err: read after end of file file_win32_pread(604,14,buffer,3519069866(486401/80/58)) read err: read after end of file file_win32_pread(604,1,buffer,3519069867(486401/80/59)) read err: read after end of file file_win32_pread(604,1,buffer,3519069868(486401/80/60)) read err: read after end of file file_win32_pread(604,14,buffer,3519069869(486401/80/61)) read err: read after end of file file_win32_pread(604,1,buffer,3519069870(486401/80/62)) read err: read after end of file file_win32_pread(604,1,buffer,3519069871(486401/80/63)) read err: read after end of file Results P Linux filesys. data 2048 7814037127 7814035080 XFS CRC enabled, blocksize=4096, 4000 GB / 3726 GiB interface_write() No partition found or selected for recovery
Danach hab ich auf Advanced Search gemacht aber der lief dann 8h ohne das dann noch was passiert ist im Log stand folgendes:
search_part() Disk \\.\PhysicalDrive1 - 4000 GB / 3726 GiB - CHS 486401 255 63 file_win32_pread(604,1,buffer,34(0/0/35)) read err: read after end of file file_win32_pread(604,1,buffer,35(0/0/36)) read err: read after end of file file_win32_pread(604,14,buffer,36(0/0/37)) read err: read after end of file file_win32_pread(604,3,buffer,50(0/0/51)) read err: read after end of file file_win32_pread(604,3,buffer,97(0/1/35)) read err: read after end of file file_win32_pread(604,8,buffer,113(0/1/51)) read err: read after end of file file_win32_pread(604,11,buffer,160(0/2/35)) read err: read after end of file file_win32_pread(604,2,buffer,2082(0/33/4)) read err: read after end of file file_win32_pread(604,1,buffer,53(0/0/54)) read err: read after end of file file_win32_pread(604,1,buffer,100(0/1/38)) read err: read after end of file file_win32_pread(604,1,buffer,121(0/1/59)) read err: read after end of file file_win32_pread(604,1,buffer,171(0/2/46)) read err: read after end of file file_win32_pread(604,1,buffer,2084(0/33/6)) read err: read after end of file file_win32_pread(604,1,buffer,54(0/0/55)) read err: read after end of file file_win32_pread(604,1,buffer,101(0/1/39)) read err: read after end of file file_win32_pread(604,1,buffer,122(0/1/60)) read err: read after end of file file_win32_pread(604,1,buffer,172(0/2/47)) read err: read after end of file file_win32_pread(604,1,buffer,2085(0/33/7)) read err: read after end of file file_win32_pread(604,1,buffer,55(0/0/56)) read err: read after end of file usw......
Ich hab jetzt noch mal den Quickcheck angeworfen dat schaut so hier aus
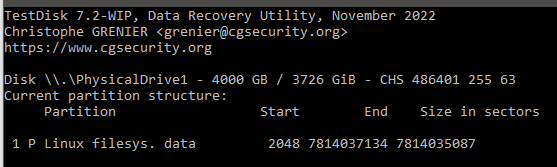
Ich bin echt am verzweifeln wieso läuft der Parity Check da überhaupt durch und warum freezt geht das System nicht in vollstop wenn da einfach ne Platte aus dem Array fällt?
-
12 minutes ago, mgutt said:
Kommt drauf an. Du sagtest, dass du einen Parity Check gemacht hast:
1.) Gab es dabei Fehler?
2.) Wurden diese korrigiert?
Nur wenn es Fehler gab und diese NICHT korrigiert wurden, ist die Parität noch auf dem alten Stand und ein Austausch des Datenträgers könnte helfen. Hast du allerdings die Fehler beheben lassen, dann haben die Daten auf den Disks Vorrang und die Parität wird dem kaputten Stand angepasst. Gab es dagegen gar keine Fehler, dann wurde der Schaden bereits vorher angerichtet und hat dabei die Parität ebenfalls aktualisiert.
Hast du das Kommando manuell ausgeführt und versehentlich /dev/sdb statt /dev/sdb1 genommen? Wenn nein oder wenn du die Reparatur über die GUI angestoßen hast, dann sind die Daten komplett hinüber, denn XFS kopiert den primären Superblock mehrfach verteilt auf dem Datenträger ab und wenn er gar keinen Secondary findet, ist das ziemlich offensichtlich ein Totalschaden:
https://manpages.ubuntu.com/manpages/jammy/man8/xfs_repair.8.html
Nein keine Fehler. Ich bin grad echt im Krisenmodus. Keine Fehler zu keiner Zeit ausser die kleine Anzeige in der GUI das die Platte nicht gemounted werden kann. Und jetzt sind die Daten futsch das kann es dich nicht sein?
Ich hatte grad auf der Platte wichtige Daten temporär abgelegt ...am normalen Speicherort wird alles 4 Fach gesichert nur zu dem Zeitpunkt grad nicht wegen Datenverschiebungen. Das kann es doch nicht sein und das bei ner neuen SSD / System ohne eine einzige Meldung 😮
Im GUI kann ich doch gar kein xfs repair fahren außer über die Konsole?
Ich habe natürlich SDB genommen sdb1 existiert bei mir nicht.
Irgendwelche Vorschläge?














BTRFS Errors Cache Disk Read Only
in General Support
Posted
@Jorge
After I successively deleted the files, it stopped at some point, i.e. no more display of corrupt files.
I am currently using a RAM bar.
What do I do now with the remaining errors?