

weirdcrap
-
Posts
454 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by weirdcrap
-
-
42 minutes ago, Kilrah said:
Likely a single location was corrupted, but now since it can't be repaired it keeps reporting errors everytime it's accessed...
Sorry, make that a check filesystem on the cache then.
Ok I've got a data transfer going but once that's done I'll put the array in maintenance mode and check the filesystem on the cache disk.
40 minutes ago, itimpi said:It is always easy to recreate the docker.img file if it gets corrupted and restore containers with settings intact via Apps->Previous Apps so, as long as the underlying XFS file system look OK, I would probably recommend doing that.
Are you saying that you disagree that it is a RAM issue? Or just that if I don't want to address the RAM issue simply recreating the docker.img file is easy?
I do like my data uncorrupted so if it is a RAM issue I'll address it, doesn't mean I'm any less mad about having to do it in a server that's less than 2 years old. I've got someone who says the can memtest the sticks for me this weekend so I'll have them do that as well just to rule the RAM out.
-
50 minutes ago, JorgeB said:
If it's a RAM problem, all data can be affected, but since you don't have any other btrfs or zfs filesystems, only the docker image is detecting data corruption.
This is what I figured. Great.
Do I need to use the memtest built into the UnRAID USB or can I just grab any old copy? I assume there is nothing "special" about the unraid version?
If I can find someone local to do the testing for me I'll have them remove the unraid USB just so it doesn't accidentally boot and start the array if they miss the post prompt or something.
I also just realized Kilrah probably meant scrub the docker image not the cache itself (since its xfs). I ran a scrub on loop2 and got no errors.
EDIT: Oh wow I didn't look at the previous syslogs in the diagnostics. apparently this just blew up fast. April 8th and 9th both syslog.1 and syslog.2 are nothing but iterative BTRFS corruption errors, just thousands of them.
99% of them all seem to be the same ino (inode?) and a few different off (offsets?): root 13093 ino 10035 off 93798400. Even the single error from today is the same ino of 10035.
If it really is a RAM error would ALL the errors be on the same inode? I would think RAM issues would return lots of different inodes and offsets as things are shifted around in memory?
-
8 minutes ago, Kilrah said:
All depends on how it evolves, now it's just a single corrupted block in the Docker image, maybe it even fixes itself if that gets deleted/rewritten when updating a container, or maybe it gets worse. Could just leave it as is until it breaks more I guess.
If it's going to potentially corrupt data written to the array then I obviously need to address that. But if its just some corrupted bits in the docker.img file I don't really care and its not worth the time and headache to address currently.
I'll keep a close eye on the logs for the next few days and make a decision based on what I observe.
EDIT: How would I know if it fixes itself with a container update? The error would just stop appearing?
-
27 minutes ago, Kilrah said:
You can do a scrub of the cache pool, and if no errors recreate the docker image
https://docs.unraid.net/unraid-os/manual/docker-management/#re-create-the-docker-image-file
If the problem comes back it'll likely be a hardware issue and you'll want that memtest.
It's not a pool its a single NVME drive. What are the possible consequences of just not addressing it then?
I would like to exhaust all other avenues before I have to take multiple days off work or track someone else down to run and baby sit memtest for me. It's not just a simple run memtest once and you're done type of thing, since i have 4 sticks if I get errors I then have to play the test 1 stick at a time game to figure out which stick needs to be replaced. So i'm looking at multiple days of down time while I try to track down which stick or sticks the problem is.
I rebuilt this server brand new because of RAM issues less than two years ago when I could no longer find new sticks of DDR3 RAM. I'm understandably pretty mad that I'm already having to take time off work to go track down some RAM related error again.
I'm desperately waiting for a fiber to the home provider to build out in my neighborhood so I can bring this server home and stop having to deal with this crap. I can't run a plex server for remote streaming when I'm out of the house off of 10-15Mbps upload though.
-
7 minutes ago, JorgeB said:
Start by running memtest, that could be a RAM problem.
That's going to be a problem as it's a remote server 4 hours away and it would have to stay down for days to thoroughly memtest 64GB of RAM (3-4 passes assuming I get no errors right away).
Anything else I can try before I have to pull the server offline for an extended period of time?
-
v6.12.10
I've been noticing intermittent appearances of the following error:
Apr 23 05:28:31 Node kernel: BTRFS warning (device loop2): csum failed root 13298 ino 10830 off 741376 csum 0x4458e96e expected csum 0x9c63b882 mirror 1 Apr 23 05:28:31 Node kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 0, flush 0, corrupt 232049, gen 0Per recommendations here I deleted and recreated my docker image but barely a day later the error is back.
Apr 24 19:22:17 Node kernel: BTRFS warning (device loop2): csum failed root 382 ino 10035 off 83816448 csum 0xc0681546 expected csum 0x185344aa mirror 1 Apr 24 19:22:17 Node kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0My docker.img file is on the cache and not in the array: /mnt/cache/docker.img
What else should I try?
-
On 4/18/2024 at 10:59 AM, drohack said:
I'm having issues with my Appdata.Backup (v2024.03.17 up-to-date).
I've installed it for the first time and tried having it run overnight. But it got stuck on "[18.04.2024 06:46:58][ℹ️][Plex-Media-Server] Verifying backup..." It was on this step for over 2 hours which seems like that shouldn't be the case.Here's my log after Aborting the flow. (you can see the 2 hour difference when it give the message "[18.04.2024 08:19:39][❌][Plex-Media-Server] tar verification failed! Tar said: tar: Removing leading `/' from member names"):
[18.04.2024 05:00:02][ℹ️][Main] 👋 WELCOME TO APPDATA.BACKUP!! :D [18.04.2024 05:00:02][ℹ️][Main] Backing up from: /mnt/user/appdata, /mnt/cache/appdata [18.04.2024 05:00:02][ℹ️][Main] Backing up to: /mnt/user/backup/ab_20240418_050002 [18.04.2024 05:00:02][ℹ️][Main] Selected containers: FileBrowser, MinecraftBasicServer, NginxProxyManager, Plex-Media-Server, SpeedTest-By-OpenSpeedTest, bazarr-1, binhex-lidarr, binhex-radarr, binhex-sabnzbd, binhex-sonarr, ombi, overseerr, recyclarr, tautulli [18.04.2024 05:00:02][ℹ️][Main] Saving container XML files... [18.04.2024 05:00:02][ℹ️][Main] Method: Stop/Backup/Start [18.04.2024 05:00:02][ℹ️][tautulli] No stopping needed for tautulli: Not started! [18.04.2024 05:00:02][ℹ️][tautulli] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:00:02][ℹ️][tautulli] Calculated volumes to back up: /mnt/user/appdata/tautulli [18.04.2024 05:00:02][ℹ️][tautulli] Backing up tautulli... [18.04.2024 05:00:03][ℹ️][tautulli] Backup created without issues [18.04.2024 05:00:03][ℹ️][tautulli] Verifying backup... [18.04.2024 05:00:03][ℹ️][tautulli] Starting tautulli is being ignored, because it was not started before (or should not be started). [18.04.2024 05:00:03][ℹ️][SpeedTest-By-OpenSpeedTest] No stopping needed for SpeedTest-By-OpenSpeedTest: Not started! [18.04.2024 05:00:03][ℹ️][SpeedTest-By-OpenSpeedTest] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:00:03][⚠️][SpeedTest-By-OpenSpeedTest] SpeedTest-By-OpenSpeedTest does not have any volume to back up! Skipping. Please consider ignoring this container. [18.04.2024 05:00:03][ℹ️][SpeedTest-By-OpenSpeedTest] Starting SpeedTest-By-OpenSpeedTest is being ignored, because it was not started before (or should not be started). [18.04.2024 05:00:03][ℹ️][ombi] Stopping ombi... done! (took 14 seconds) [18.04.2024 05:00:17][ℹ️][ombi] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:00:17][ℹ️][ombi] Calculated volumes to back up: /mnt/user/appdata/ombi [18.04.2024 05:00:17][ℹ️][ombi] Backing up ombi... [18.04.2024 05:00:18][ℹ️][ombi] Backup created without issues [18.04.2024 05:00:18][ℹ️][ombi] Verifying backup... [18.04.2024 05:00:18][ℹ️][ombi] Starting ombi... (try #1) done! [18.04.2024 05:00:32][ℹ️][MinecraftBasicServer] No stopping needed for MinecraftBasicServer: Not started! [18.04.2024 05:00:32][ℹ️][MinecraftBasicServer] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:00:32][ℹ️][MinecraftBasicServer] Calculated volumes to back up: /mnt/cache/appdata/minecraftbasicserver [18.04.2024 05:00:32][ℹ️][MinecraftBasicServer] Backing up MinecraftBasicServer... [18.04.2024 05:01:20][ℹ️][MinecraftBasicServer] Backup created without issues [18.04.2024 05:01:20][ℹ️][MinecraftBasicServer] Verifying backup... [18.04.2024 05:03:06][ℹ️][MinecraftBasicServer] Starting MinecraftBasicServer is being ignored, because it was not started before (or should not be started). [18.04.2024 05:03:06][ℹ️][binhex-sabnzbd] Stopping binhex-sabnzbd... done! (took 6 seconds) [18.04.2024 05:03:12][ℹ️][binhex-sabnzbd] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:03:12][ℹ️][binhex-sabnzbd] Calculated volumes to back up: /mnt/user/appdata/binhex-sabnzbd [18.04.2024 05:03:12][ℹ️][binhex-sabnzbd] Backing up binhex-sabnzbd... [18.04.2024 05:03:13][ℹ️][binhex-sabnzbd] Backup created without issues [18.04.2024 05:03:13][ℹ️][binhex-sabnzbd] Verifying backup... [18.04.2024 05:03:13][ℹ️][binhex-sabnzbd] Starting binhex-sabnzbd... (try #1) done! [18.04.2024 05:03:24][ℹ️][recyclarr] Stopping recyclarr... done! (took 7 seconds) [18.04.2024 05:03:31][ℹ️][recyclarr] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:03:31][ℹ️][recyclarr] Calculated volumes to back up: /mnt/user/appdata/recyclarr [18.04.2024 05:03:31][ℹ️][recyclarr] Backing up recyclarr... [18.04.2024 05:03:33][ℹ️][recyclarr] Backup created without issues [18.04.2024 05:03:33][ℹ️][recyclarr] Verifying backup... [18.04.2024 05:03:34][ℹ️][recyclarr] Starting recyclarr... (try #1) done! [18.04.2024 05:03:46][ℹ️][overseerr] Stopping overseerr... done! (took 11 seconds) [18.04.2024 05:03:57][ℹ️][overseerr] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:03:57][ℹ️][overseerr] Calculated volumes to back up: /mnt/user/appdata/overseerr [18.04.2024 05:03:57][ℹ️][overseerr] Backing up overseerr... [18.04.2024 05:03:59][ℹ️][overseerr] Backup created without issues [18.04.2024 05:03:59][ℹ️][overseerr] Verifying backup... [18.04.2024 05:03:59][ℹ️][overseerr] Starting overseerr... (try #1) done! [18.04.2024 05:04:10][ℹ️][binhex-lidarr] Stopping binhex-lidarr... done! (took 18 seconds) [18.04.2024 05:04:28][ℹ️][binhex-lidarr] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:04:28][ℹ️][binhex-lidarr] Calculated volumes to back up: /mnt/user/appdata/binhex-lidarr [18.04.2024 05:04:28][ℹ️][binhex-lidarr] Backing up binhex-lidarr... [18.04.2024 05:04:59][ℹ️][binhex-lidarr] Backup created without issues [18.04.2024 05:04:59][ℹ️][binhex-lidarr] Verifying backup... [18.04.2024 05:05:05][ℹ️][binhex-lidarr] Starting binhex-lidarr... (try #1) done! [18.04.2024 05:05:19][ℹ️][bazarr-1] Stopping bazarr-1... done! (took 15 seconds) [18.04.2024 05:05:34][ℹ️][bazarr-1] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:05:34][ℹ️][bazarr-1] Calculated volumes to back up: /mnt/user/appdata/bazarr-1 [18.04.2024 05:05:34][ℹ️][bazarr-1] Backing up bazarr-1... [18.04.2024 05:05:38][ℹ️][bazarr-1] Backup created without issues [18.04.2024 05:05:38][ℹ️][bazarr-1] Verifying backup... [18.04.2024 05:05:39][ℹ️][bazarr-1] Starting bazarr-1... (try #1) done! [18.04.2024 05:05:53][ℹ️][binhex-radarr] Stopping binhex-radarr... done! (took 17 seconds) [18.04.2024 05:06:10][ℹ️][binhex-radarr] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:06:10][ℹ️][binhex-radarr] Calculated volumes to back up: /mnt/user/appdata/binhex-radarr [18.04.2024 05:06:10][ℹ️][binhex-radarr] Backing up binhex-radarr... [18.04.2024 05:10:12][ℹ️][binhex-radarr] Backup created without issues [18.04.2024 05:10:12][ℹ️][binhex-radarr] Verifying backup... [18.04.2024 05:26:39][ℹ️][binhex-radarr] Starting binhex-radarr... (try #1) done! [18.04.2024 05:26:52][ℹ️][binhex-sonarr] Stopping binhex-sonarr... done! (took 9 seconds) [18.04.2024 05:27:01][ℹ️][binhex-sonarr] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:27:01][ℹ️][binhex-sonarr] Calculated volumes to back up: /mnt/user/appdata/binhex-sonarr [18.04.2024 05:27:01][ℹ️][binhex-sonarr] Backing up binhex-sonarr... [18.04.2024 05:28:21][ℹ️][binhex-sonarr] Backup created without issues [18.04.2024 05:28:21][ℹ️][binhex-sonarr] Verifying backup... [18.04.2024 05:46:40][ℹ️][binhex-sonarr] Starting binhex-sonarr... (try #1) done! [18.04.2024 05:46:51][ℹ️][FileBrowser] Stopping FileBrowser... done! (took 5 seconds) [18.04.2024 05:46:56][ℹ️][FileBrowser] '/mnt/user/appdata/filebrowser/branding' is within mapped volume '/mnt/user/appdata/filebrowser'! Ignoring! [18.04.2024 05:46:56][ℹ️][FileBrowser] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:46:56][ℹ️][FileBrowser] Calculated volumes to back up: /mnt/user/appdata/filebrowser [18.04.2024 05:46:56][ℹ️][FileBrowser] Backing up FileBrowser... [18.04.2024 05:46:56][ℹ️][FileBrowser] Backup created without issues [18.04.2024 05:46:56][ℹ️][FileBrowser] Verifying backup... [18.04.2024 05:46:56][ℹ️][FileBrowser] Starting FileBrowser... (try #1) done! [18.04.2024 05:47:05][ℹ️][NginxProxyManager] Stopping NginxProxyManager... done! (took 7 seconds) [18.04.2024 05:47:12][ℹ️][NginxProxyManager] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:47:12][ℹ️][NginxProxyManager] Calculated volumes to back up: /mnt/user/appdata/NginxProxyManager [18.04.2024 05:47:12][ℹ️][NginxProxyManager] Backing up NginxProxyManager... [18.04.2024 05:47:14][ℹ️][NginxProxyManager] Backup created without issues [18.04.2024 05:47:14][ℹ️][NginxProxyManager] Verifying backup... [18.04.2024 05:47:15][ℹ️][NginxProxyManager] Starting NginxProxyManager... (try #1) done! [18.04.2024 05:47:25][ℹ️][Plex-Media-Server] Stopping Plex-Media-Server... done! (took 13 seconds) [18.04.2024 05:47:38][ℹ️][Plex-Media-Server] Should NOT backup external volumes, sanitizing them... [18.04.2024 05:47:38][ℹ️][Plex-Media-Server] Calculated volumes to back up: /mnt/user/appdata/Plex-Media-Server [18.04.2024 05:47:38][ℹ️][Plex-Media-Server] Backing up Plex-Media-Server... [18.04.2024 06:46:58][ℹ️][Plex-Media-Server] Backup created without issues [18.04.2024 06:46:58][ℹ️][Plex-Media-Server] Verifying backup... [18.04.2024 08:19:39][❌][Plex-Media-Server] tar verification failed! Tar said: tar: Removing leading `/' from member names [18.04.2024 08:25:03][ℹ️][Plex-Media-Server] Backing up the flash drive. [18.04.2024 08:25:57][ℹ️][Plex-Media-Server] Flash backup created! [18.04.2024 08:25:57][⚠️][Main] Backup cancelled! Executing final things. You will be left behind with the current state! [18.04.2024 08:25:57][ℹ️][Main] DONE! Thanks for using this plugin and have a safe day ;) [18.04.2024 08:25:57][ℹ️][Main] ❤️
I'm not sure the best way to post my settings:


Let me know if there's any other logs or information I should provide.
I did a quick Google Search and didn't see anything specific for this "stuck" or "hung" status on "verifying backup". But maybe I didn't look hard enough.I am also getting the tar verification error on several container backups:
[23.04.2024 05:11:55][?][nzbhydra2] tar verification failed! Tar said: tar: Removing leading `/' from member names; ; gzip: stdin: invalid compressed data--crc error; mnt/cache/appdata/nzbhydra2/backup/nzbhydra-2024-04-21 07-02-59.zip: Contents differ; tar: Child returned status 1; tar: Error is not recoverable: exiting nowIs this a user or container issue or a problem with the plugin?
-
2 hours ago, Rysz said:
I'm not getting involved with the guesswork about a possible future licensing model.
Should the financial need for a subscription model arise, I'll be happy to consider it for the system I've grown to love.
But it really hurts me to see that Unraid as a brand is taking what seems like a lot of unnecessary PR damage right now.
Unraid has always been very community reliant and driven and I'd say that was one the most liked points besides the OS.
All of the hate and doomsday scenarios being spun online right now could've been avoided by better communication.
I really hope a lesson is learnt from this and we'll see more up-front communication, rather than picking up the pieces later.
It is still concerning though that LimeTech doesn't seem to have learned a lesson about communicating with the community from the last big kerfuffle that drove @CHBMB away. The community is what makes UnRAID great, and to keep the community around communication and engagement should be a priority IMO.
I'm also not going to speculate and get mad over what are currently entirely unconfirmed changes to the licensing model.
-
Alright so I guess the containers were just kind of borked. I removed them and got a "no such container" error. After reinstalling the containers they both check for updates successfully.
Should have tried it sooner but didn't believe anything was wrong with the containers since they were both working correctly.
-
Hmm ok maybe this is a DNS thing? I kind of forgot I had a second server (I've been keeping it off because its so hot upstairs) so I installed the dockers and they seem to be able to check for updates on this server. I compared the repo URLs and they're the same.
Both servers are behind pfsense routers (v2.7.0) with nearly identical configurations. DNS on the routers has the two repo domains cached correctly.
EDIT: I forgot I think I patched my docker file manually rather than use the plugin like I thought I did:
But this wouldn't persist after a reboot without an entry in my go file or a user script, right?
I don't have a script or anything to reapply it so I don't think this is the issue but I could be wrong.
-
I'm having a bit of trouble figuring out what my issue is as I've rarely had any issues with docker and updating before.
The LinuxServer.io SABNZBD container and the plextraktsync container are consistently reporting that update info is not available".
I haven't changed anything on my end and the repos still appear to be up and active. I don't really see where UnRAID or docker logs any further details about WHY this information is unavailable so I'm struggling to find troubleshooting resources.
Repos are here: https://ghcr.io/taxel/plextraktsync & https://github.com/orgs/linuxserver/packages/container/package/sabnzbd
I know this was a widespread issue a few versions ago but afaik that was corrected already.
I tried to look for threads from others but my Google-Fu is failing me apparently.
-
3 minutes ago, Frank1940 said:
Try using \\<IP_Address_of_server> (Example \\192.168.1.123 )
It's the same result
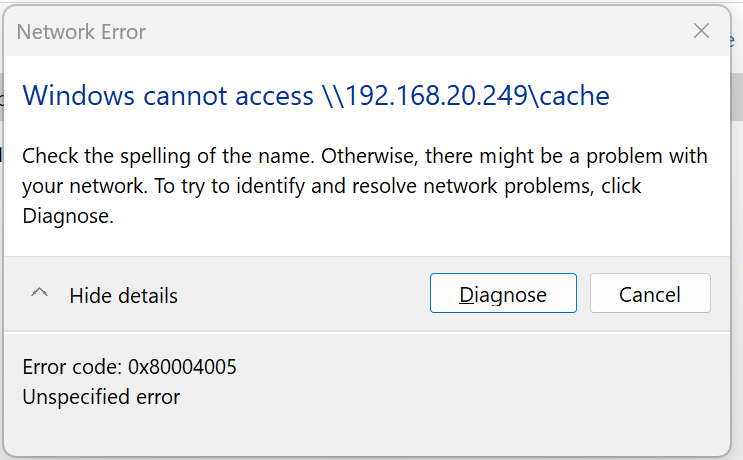
-
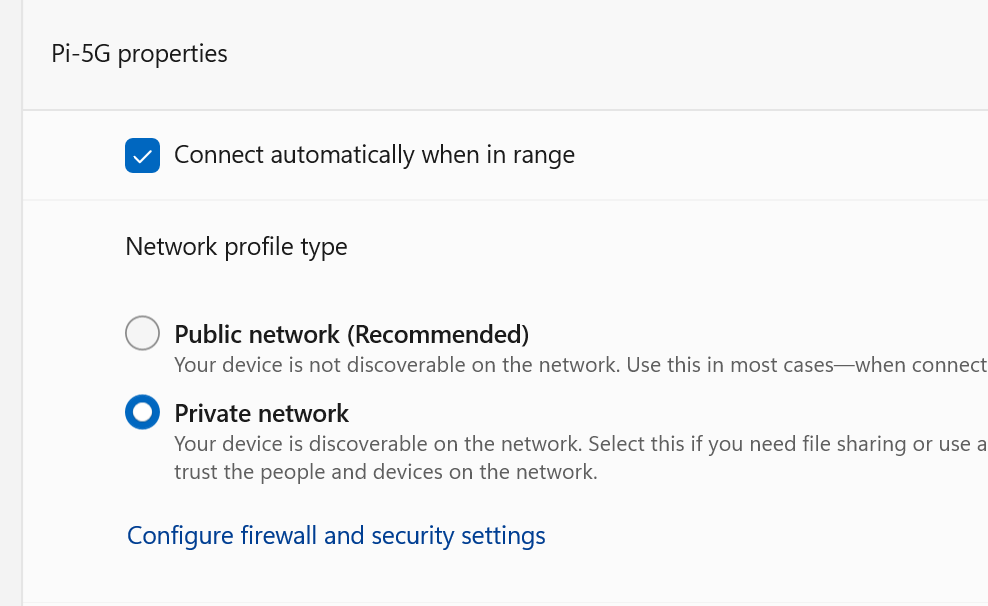
1 hour ago, Frank1940 said:
Also make sure your home network connection is Private, not Public. See here fro details:
It is:
 1 hour ago, Frank1940 said:
1 hour ago, Frank1940 said:Check to see that you have things setup as described here:
https://forums.unraid.net/topic/110580-security-is-not-a-dirty-word-unraid-windows-10-smb-setup/
Normally, this will not be allowed, for details, see here:
That's fine I don't really want or need public shares anyway.
I have already read through the document from that thread and my laptop already uses the sane defaults mentioned.
SMB1.0 is not installed. I already have my credentials loaded in credential manager and a matching user has existed on the UnRAID box this entire time. I played with the insecure guest login setting under lanman and it made no difference so I've kept it disabled.
My home network and sharing settings already use sane security defaults:
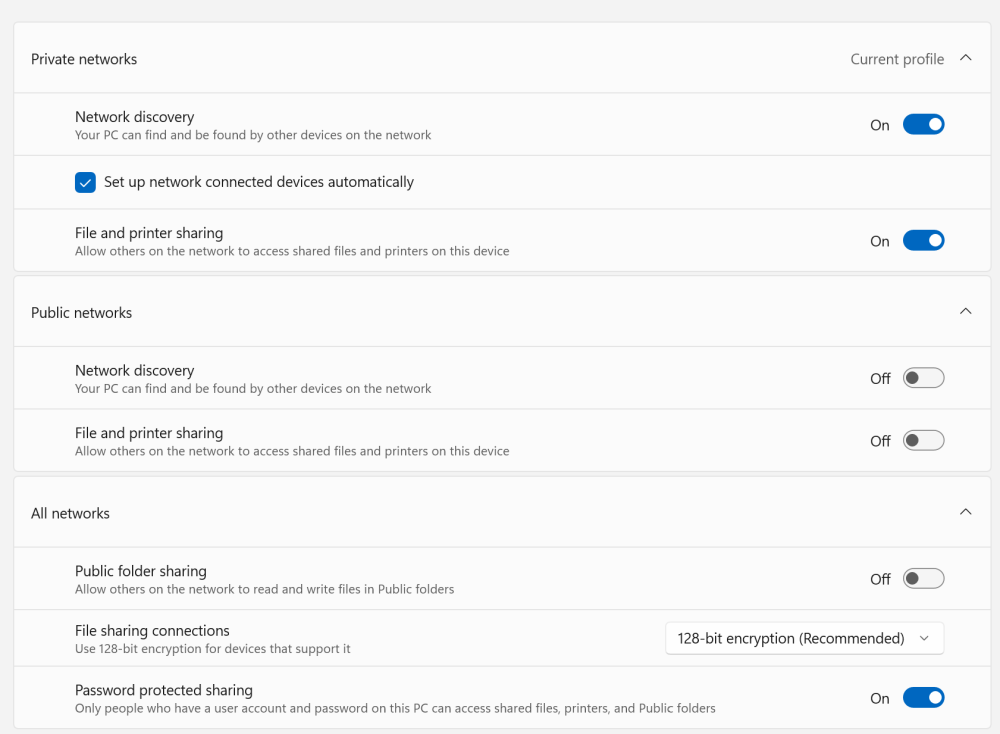
I did not follow the network neighborhood part of the linked doc because I don't really care if the servers show up in the network window or not.
All of my exported shares are set to private so no guest read access is allowed anyway.
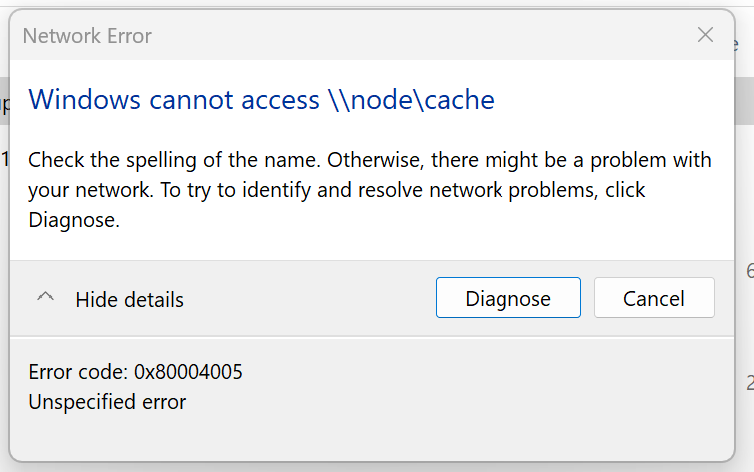
The issue is that I can't even get a listing of my available shares by going to the server path "\\node" so I don't think this is an authentication issue as I can't even get to the point where I would attempt to open a share. Furthermore trying to access a share path directly results in the same unhelpful error.
-
Turning up Samba logging produced absolutely zero log entries when trying to access the server. So the issue is clearly that the laptop's requests for shares are never making it across the tunnel for some bizarre reason.
EDIT: I tested again with a bootable copy of linux on the laptop and I can access the shares fine outside of Windows so this is 100% a Windows issue, not an issue with the WireGuard tunnel.
Am I missing some network setting in Windows that allows cross subnet traffic to work that gets enabled when I activate the WireGuard for Windows client?
-
I've got a fresh Windows 11 install on a brand new laptop and I cannot access my remote UnRAID server via SMB. I can ping by name/IP and access the web interface for management.
I have two servers, one local and one remote but connected to my local LAN by a WireGuard site to site VPN. There is a static route established for the remote subnet in pfsense and other devices (Windows 10, 11, & Linux) can access the remote server shares without issue. I have both server's defined in my host file on the laptop.
I get an "unspecified error" 0x80004005 trying to access the remote server by name or IP address.
I've been making my way through the Windows issues with UnRAID thread but so far nothing I've tried has helped.
I've tried enforcing a minimum SMB setting in the extra config for SMB on the remote server.
I've also tried adding my credentials into credential manager for the device. My UnRAID user credentials fully match my laptop credentials (capitalization and all) so I don't think the credential manager thing was necessary but I'm not sure what else to try.
All of this works fine from my other Windows computer but it was upgraded from win 10 and its possible I changed other settings to make it work but I don't recall what they are if I did. The linux laptop I have and a bootable copy of ubuntu both can access the server without any mucking about. My wife's Windows laptop also works fine.
Now here's the real kicker. thinking maybe something was wrong with my WireGuard tunnel so I connected to my phone hotspot and fired up WireGuard on the laptop and lo and behold it works without changing anything!?
So What could be causing this? I checked the network settings on both devices and they match, no additional IP settings specified or anything. Everything is pulling DHCP from my pfsense box.
I'm fairly certain this is an SMB issue and not a WireGuard issue but the fact that changing net connections and using the WireGuard for Windows client suggests maybe not?
So, why do all my other devices work over the tunnel with no issues and not this one?
node-diagnostics-20230604-1551.zip
EDIT: I'm going to try and bump the log level in samba once I can find a moment to stop the array. I'm curious if there are requests even hitting the server or if I'm not making it past the router on my side.
EDIT2: I forgot to mention I also tried making a public share and setting it public to ensure it wasn't a credential issue. I can't even access public shares.
-
14 hours ago, thymon said:
Hello,
Same here

Test iperf3 unraid --> unraid-backup
(30Mbits)root@Unraid-Backup:~# iperf3 -s ----------------------------------------------------------- Server listening on 5201 (test #1) ----------------------------------------------------------- Accepted connection from 10.253.0.1, port 54148 [ 5] local 10.253.0.2 port 5201 connected to 10.253.0.1 port 54162 [ ID] Interval Transfer Bitrate [ 5] 0.00-1.00 sec 2.26 MBytes 19.0 Mbits/sec [ 5] 1.00-2.00 sec 2.63 MBytes 22.1 Mbits/sec [ 5] 2.00-3.00 sec 2.75 MBytes 23.1 Mbits/sec [ 5] 3.00-4.00 sec 3.00 MBytes 25.2 Mbits/sec [ 5] 4.00-5.00 sec 3.09 MBytes 25.9 Mbits/sec [ 5] 5.00-6.00 sec 3.00 MBytes 25.1 Mbits/sec [ 5] 6.00-7.00 sec 2.96 MBytes 24.8 Mbits/sec [ 5] 7.00-8.00 sec 2.81 MBytes 23.5 Mbits/sec [ 5] 8.00-9.00 sec 2.81 MBytes 23.6 Mbits/sec [ 5] 9.00-10.00 sec 2.26 MBytes 19.0 Mbits/sec [ 5] 10.00-10.09 sec 224 KBytes 21.5 Mbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate [ 5] 0.00-10.09 sec 27.8 MBytes 23.1 Mbits/sec receiver
root@Unraid:~# iperf3 -c 10.253.0.2 Connecting to host 10.253.0.2, port 5201 [ 5] local 10.253.0.1 port 54162 connected to 10.253.0.2 port 5201 [ ID] Interval Transfer Bitrate Retr Cwnd [ 5] 0.00-1.00 sec 3.91 MBytes 32.8 Mbits/sec 0 337 KBytes [ 5] 1.00-2.00 sec 2.64 MBytes 22.1 Mbits/sec 0 350 KBytes [ 5] 2.00-3.00 sec 2.76 MBytes 23.1 Mbits/sec 0 337 KBytes [ 5] 3.00-4.00 sec 3.13 MBytes 26.2 Mbits/sec 0 369 KBytes [ 5] 4.00-5.00 sec 3.19 MBytes 26.7 Mbits/sec 0 326 KBytes [ 5] 5.00-6.00 sec 3.19 MBytes 26.7 Mbits/sec 0 315 KBytes [ 5] 6.00-7.00 sec 2.39 MBytes 20.1 Mbits/sec 0 310 KBytes [ 5] 7.00-8.00 sec 3.19 MBytes 26.8 Mbits/sec 0 313 KBytes [ 5] 8.00-9.00 sec 2.39 MBytes 20.1 Mbits/sec 0 297 KBytes [ 5] 9.00-10.00 sec 2.39 MBytes 20.1 Mbits/sec 0 307 KBytes - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate Retr [ 5] 0.00-10.00 sec 29.2 MBytes 24.5 Mbits/sec 0 sender [ 5] 0.00-10.09 sec 27.8 MBytes 23.1 Mbits/sec receiver
rsync with 1Go "testfile" over Wireguard VPN at 3Mbits.... (I tested all possible options for rsync and SSH without improvement)...
root@Unraid:~# rsync -az --progress testfile 10.253.0.2:/mnt/cache([email protected]) testfile 50,987,008 4% 3.04MB/s 0:05:20
So, what other solution do you use to backup to another remote Unraid server?
You can setup a VM in UnRAID or really make a wireguard server on any other device besides directly in the UnRAID OS. I set it up on my site routers and it performs way better than UnRAID ever did.
-
6 hours ago, miicar said:
I am also getting a random error "kernel: traps: lsof[*****] general protection fault ip:************* error:0 in libc-2.36.so[**********]" in my logs as well. This is quite frustrating over the last few weeks, as random things i do "resolve" the issue, so i have no idea what the actual cause/solution is!
I've gotten this on and off for years across various versions. It doesn't seem to affect anything for me that I can tell.
-
On 1/24/2023 at 7:42 AM, PlanetDyna said:
Unfortunately, no one is working to fix the problem?
The problem is no one seems to be able to definitively pinpoint the cause of the issue.
LimeTech is apparently unable to reproduce this in their testing and it seems to be limited to only a small subset of users so it just isn't garnering much attention I think. The more people who find this thread and share their experiences the more likely someone will start to take a more serious look at the problem.
The only solution at this time is to just not use UnRAID as a WireGuard server if you want to be able to move large amounts of data quickly.
-
 1
1
-
-
this fixed Recyclarr and PlexTraktSync for me, thanks!
-
Just encountered this as well after changing a share's minimum free space. Everything seems to be working, last log message was about winbind but i'm not sure they're related.
Dec 25 18:40:35 Node wsdd2[11454]: 'Terminated' signal received. Dec 25 18:40:35 Node winbindd[11458]: [2022/12/25 18:40:35.498412, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) Dec 25 18:40:35 Node winbindd[11458]: Got sig[15] terminate (is_parent=1) Dec 25 18:40:35 Node wsdd2[11454]: terminating. Dec 25 18:40:35 Node winbindd[11460]: [2022/12/25 18:40:35.498462, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) Dec 25 18:40:35 Node winbindd[11460]: Got sig[15] terminate (is_parent=0) Dec 25 18:40:35 Node winbindd[12972]: [2022/12/25 18:40:35.498567, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) Dec 25 18:40:35 Node winbindd[12972]: Got sig[15] terminate (is_parent=0) Dec 25 18:40:37 Node root: Starting Samba: /usr/sbin/smbd -D Dec 25 18:40:37 Node smbd[15089]: [2022/12/25 18:40:37.670343, 0] ../../source3/smbd/server.c:1741(main) Dec 25 18:40:37 Node smbd[15089]: smbd version 4.17.3 started. Dec 25 18:40:37 Node smbd[15089]: Copyright Andrew Tridgell and the Samba Team 1992-2022 Dec 25 18:40:37 Node root: /usr/sbin/wsdd2 -d Dec 25 18:40:37 Node wsdd2[15103]: starting. Dec 25 18:40:37 Node root: /usr/sbin/winbindd -D Dec 25 18:40:37 Node winbindd[15104]: [2022/12/25 18:40:37.722342, 0] ../../source3/winbindd/winbindd.c:1440(main) Dec 25 18:40:37 Node winbindd[15104]: winbindd version 4.17.3 started. Dec 25 18:40:37 Node winbindd[15104]: Copyright Andrew Tridgell and the Samba Team 1992-2022 Dec 25 18:40:37 Node winbindd[15106]: [2022/12/25 18:40:37.724476, 0] ../../source3/winbindd/winbindd_cache.c:3116(initialize_winbindd_cache) Dec 25 18:40:37 Node winbindd[15106]: initialize_winbindd_cache: clearing cache and re-creating with version number 2 Dec 25 18:41:52 Node sshd[16971]: Connection from 10.250.0.3 port 57350 on 192.168.20.249 port 22 rdomain ""
node-diagnostics-20221225-1845.zip
EDIT: and just like that after about 10 minutes its gone. No entries in the logs or anything.... very strange.
-
 1
1
-
-
6 hours ago, Torben said:
That's also my plan, the Pi4 with OpenWRT is already prepared.
The sad thing about this is that it was working flawlessly with 6.8.3 and something somewhere somehow broke the functionality starting with 6.9. But well, because of that I started looking at OpenWRT and got something new to tinker with.
Oh yeah it never worked right for me. From the day I set it up it ran like crap.
pfSense's implementation works great. Got a Proctectli FW4B at home and a J4125 at the remote site both running pfsense 2.6.0.
-
 1
1
-
-
All of this seems to have been resolved by putting my own router in. Plugin & docker update checks are 3-4x faster than before. pings to hostname's start faster. I'll keep monitoring for DNS issues but I'm considering this resolved for now.
A $100 J4125 box from aliexpress and pfSense CE made a night and day difference over that zyxel.
-
1
-
-
A final update to this.
Unfortunately I had to abandon using UnRAID as the WireGuard server as I couldn't resolve this. This issue coupled with my other issue drove me to invest in putting my own router in front of the remote server.
I've now built a site to site WireGuard tunnel between my two routers and everything is working exactly as I would expect it to over the WireGuard tunnel. I'm getting my full speed up to the bandwidth limit I set in the rsync command.
So TL;DR is don't expect UnRAID's implementation of WireGuard to be able to move large amounts of data without choking. At least not as of this post, hopefully it can be improved in the future.
-
9 hours ago, thestillwind said:
Yes I know, but it's not working. I saw on the issue that it was changing to macvlan BUT the GUi shows ipvlan.
This is a GUI bug, the setting applies correctly it just doesn't show right in the GUI. See here:









CSUM Loop2 error
in General Support
Posted
I assume this means the FS is fine?
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting.