mytech
Members
-
Joined
-
Last visited
Everything posted by mytech
-
Unfortunately not. The only other thing I thought of trying, but I haven’t gotten around to yet, is installing NPM on another device and pointing it at the Immich container’s LAN IP.
-
I had it as the Docker container initially and that’s where we were having problems. Transcoding was pegging the CPU, rarely touching the GPU and causing 4K playback to be impossible. Moving to the VM and passing the GPU through solved that issue (mostly).
-
Thanks for this - it’s really useful. The VM in question is a Windows Server 2022 machine running Plex/Jellyfin. It’s got 32GB of RAM (system has 64GB total) and an RTX 3060 passed through to it. I wanted to give it as much resource as possible because we were having problems with Plex transcoding stuttering, so I was hoping a lot of resources would help. I have seen Plex use 100% of the CPU when scanning library files, but I don’t mind that taking longer with the fewer cores given that it only does that from time to time. I’m hopeful that reducing the cores to the VM will solve the stability issues without impacting Plex! 🤞
-
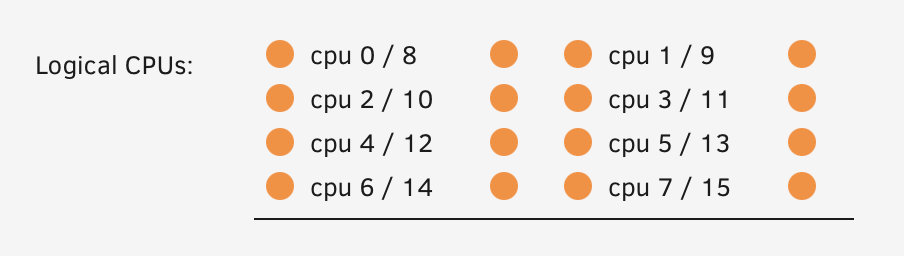
It's really frustrating because the issue occurs randomly - it can sometimes take weeks for it to happen again, so I don't think I'd be able to put it in safe mode, as I'd have to wait weeks without VMs or dockers. The only other thing I can think to try is removing a couple of CPUs from one of the VMs that seemed to have all of them assigned to it. I'm just wondering if at some point the CPU gets pegged at 100% causing things to crash maybe... I've now removed 0/8 and 2/10.
-
As requested, please see attached the syslog file. The server had this issue again today (1st August), sometime after 04:00am. I've looked through the log but can't see anything obvious. Thank you in advance. syslog-127.0.0.1.log
-
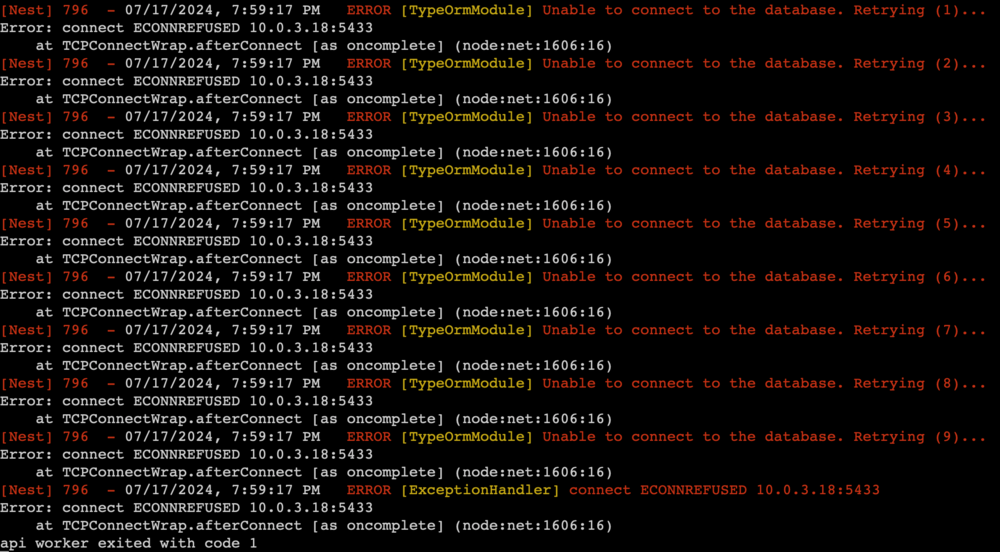
I've got Immich, PostgreSQL_Immich (spaceinvaderone's image) and NGNIX Proxy Manager all installed via Apps on my UNRAID server. My router is configured to port forward 80 and 443 to my NPM docker image (10.0.3.254). For the life of me, I can't work out the correct way to get these to all talk to each other in terms of network config. On some occasions, I can get Immich to be able to connect to the DB, but then NPM refuses to see it, and othertimes the other way around. I've tried having them all on custom br0 with their own IPs, but Immich (10.0.3.17) refuses to connect to the DB (10.0.3.18): I've put Immich and the DB on the 'Bridge' network type and changed the config so that it uses the 172.17.0.x address for the DB (Immich IP then becomes 10.0.3.1:8080) which work, but then NPM behind Cloudflare gives me the 502 error. Can someone please help me with this and guide me on what the best way to set all of these up is please? Thank you.
-
Ah, okay. I did have a quick look inside and thought that might be the case. So for now, looks like I'll need to enable syslog and wait until it happens again? Thank you.
-
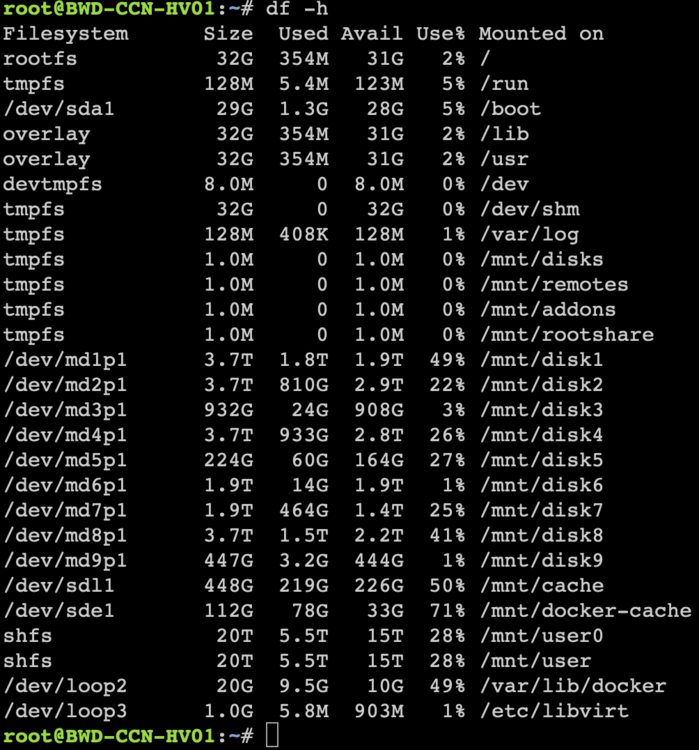
Hi, On a couple of occasions now, today being one of them, I've had an alert from my monitoring software to say that my VM has gone offline - I've confirmed this as I'm unable to access or ping the VM. However, upon checking the UNRAID machine itself, I'm unable to access the UNRAID GUI (via any address/IP), nor can I SSH into it. It does, however, still respond to ping. This has happened twice now from memory in the past month or so, and I'm at a loss. I saw another post about checking if rootfs was full, but that's not the case on this server: The only disk capacity issues I've noticed is that I had around 150 emails yesterday from the UNRAID server saying that the docker-cache drive (sde) was 71% full. I didn't have time to explore that yesterday or today, but I doubt that this is related. I've attached my diagnostics in the hope that someone more skilled than I can notice anything wrong? The VM flagged as being offline around 12:55. Thank you in advance. Kind Regards, Callum bwd-ccn-hv01-diagnostics-20240717-1834.zip
-
I'm currently trying to passthrough a new GPU to a VM, which I understand means I need to enable IOMMU in the BIOS. However, when I do this, any disks attached to my StarTech.com 8 Port SATA PCIe Card - PCI Express 6Gbps SATA Expansion Adapter Card with 4 Host Controllers - SATA PCIe Controller Card - PCI-e x4 Gen 2 to SATA III - SATA HDD/SSD (8P6G-PCIE-SATA-CARD) (4x ASM1182e controllers) no longer show in the array (so the array won't start). Disks not attached to that card (either directly to the motherboard or to another, different, SATA addin card) appear to be unaffected. The system devices list shows the four controllers as being in the same IOMMU group: IOMMU group 13: ... [1b21:0612] 05:00.0 SATA controller: ASMedia Technology Inc. ASM1061/ASM1062 Serial ATA Controller (rev 02) [1b21:0612] 06:00.0 SATA controller: ASMedia Technology Inc. ASM1061/ASM1062 Serial ATA Controller (rev 02) [1b21:0612] 07:00.0 SATA controller: ASMedia Technology Inc. ASM1061/ASM1062 Serial ATA Controller (rev 02) [1b21:0612] 08:00.0 SATA controller: ASMedia Technology Inc. ASM1061/ASM1062 Serial ATA Controller (rev 02) I've tried enabling each of the ACS override settings, which didn't help. I've tried swapping my GPU and the SATA PCIe card, which didn't help. I've tried adding "iommu=pt" to the syslinux config (as I read that online), which didn't help. I'm at a total loss - I need to be able to pass through my GPU, but it seems like I can't even start my array with IOMMU enabled. Thank you to anyone who can help. Specs: Motherboard: Gigabyte Technology Co., Ltd. B550 GAMING X (GPU is in PCIEX16, StarTech card is in PCIEX2). Processor: AMD Ryzen 7 3700X 8-Core @ 3600 MHz GPU: NVIDIA RTX 3050 bwd-ccn-hv01-diagnostics-20240610-2309.zip
-
Thanks so much for this. I tried a couple of the suggestions with no success, but then tried looking for similar settings in the BIOS. In the end, I made the below changes and the HDDs now all appear in UNRAID! IOMMU: Disabled Upon further testing, it is the IOMMU setting that fixed this, not the two below. Above 4G Decoding: Enabled Re-Size BAR Support: Auto
-
Thanks for the reply. In the BIOS, I can see all of my drives, correctly named so the controller does seem to be doing its job properly, until it gets into UNRAID. I'd seen posts where people were using this card and, after resolving various other issues (such as power), it seemed to work, so I was hoping it would for me too. Do you know if there's anything I can adjust to make it work properly in UNRAID like it does in the BIOS? If not, are you able to recommend an 8 port addin card (or two 4 port cards) that I can purchase from Amazon UK please? Thank you.
-
Hi all, After some issues with drives connected to a PCI to SATA card that I've had for a few years showing as missing after a reboot, I did some research on the forum about cards with different controllers etc. and purchased the StarTech.com 8 Port SATA PCIe Card which has 4x ASMedia - ASM1061 controllers (which I believe should work). The cables being used are those supplied with the card (2x Mini-SAS connections with Mini-SAS to 4x locking SATA adapter cables). However, no matter what I do, I can't get my disks to show in UNRAID again. The disks are a mix of SSD and HDDs from different manufacturers. Some of the drives are in the built in drive bays in the Silverstone SST-CS380 V2 (so connected to the included backplane). The others are in an Icy Dock MB326SP-B. The four controllers show in the UNRAID System Devices screen, but not the disks. The disks that do show up are either connected to the four SATA ports on the motherboard, or to another offbrand SATA card that is in the system (which if today had gone well, I was going to replace with another StarTech card...). When UNRAID is booting, I can see various ATA errors for a few minutes about devices being misidentified. By contrast, in the Gigabyte BIOS, I can see all 15 of my drives, including those on that new StarTech card, so the card does indeed appear to be working. The motherboard is a Gigabyte B550 GAMING X (rev. 1.0) with an AMD Ryzen 7 3700X. I've tried swapping my GPU and the StarTech card over to rule out a PCI issue, no change. I've attached my diagnostics. Is anyone able to help please? Thank you in advance. bwd-ccn-hv01-diagnostics-20240402-2137.zip
-
I changed the SATA cable for parity today. I also switched it from my one SATA controller to the other. I also removed the HDD from the hotswap and put it back in to ensure proper connection. The cache drive is in a totally different enclosure - I haven't noticed any issues with that one?
-
I'm using this case from Silverstone (https://www.silverstonetek.com/en/product/info/server-nas/CS380/) and all the HDDs are in the hotswap bays, so the power is handled (I guess split) by that backplane.
-
Thanks for this. While I did not know this was a thing, it turns out I have already done this. This is what I meant when I said removed from the array and then re-added. I started the array after removing, stopped and then re-added. It then starts to rebuild parity and fails after a few hours, causing the drive to be disabled again.
-
Hi, Recently, my parity drive has gone into error state and has been disabled. I have removed it from the array and readded multiple times, to which it errors out a few hours later. Today, I finally got around to changing both the SATA cable and changing which PCI-e SATA card it is plugged into. Unfortunately, no change. Would someone please be able to take a look through my diagnostics (no idea what I'm looking for) to see if they can identify anything that would be causing this please? This drive is almost brand new and was put straight into the UNRAID box as the parity drive. Thank you in advance. bwd-ccn-hv01-diagnostics-20221002-1916.zip
-
Hi, Probably not the answer you were hoping for, but I think it just fixed itself one day. I've checked my config to see if I'd changed the temp warnings to just be super high (because that sounded familiar) but they're still 55/65, so I can only presume that it fixed itself one day and I didn't notice... Sorry!
-
Hi, Please see attached - is this what you need? bwd-ccn-hv01-diagnostics-20210509-1153.zip
-
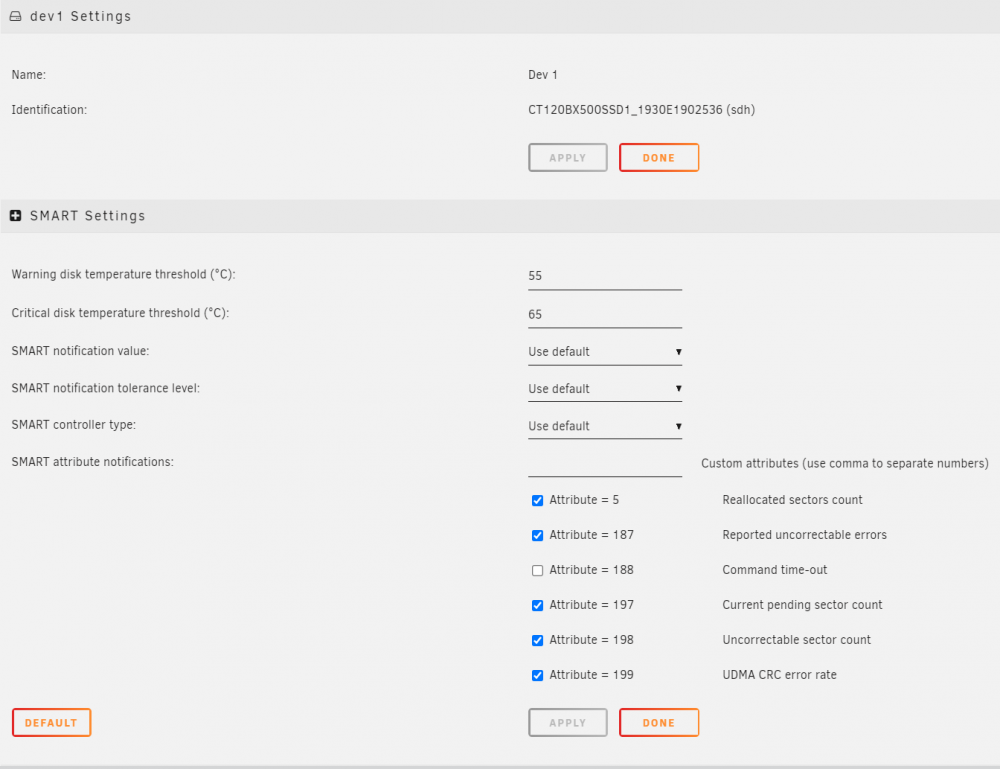
Hi there, I've got a Crucial SSD in my Undraid Box, piped directly into a VM (not part of an array etc.). I keep receiving temperature warnings from Unraid around the 44-48° mark, which is not anywhere near the limit. I checked the manual for the drive and adjusted the temperatures for this drive in Unraid to match (see image), yet I still keep getting the same emails from Unraid multiple times per day: 1. Warning [BWD-CCN-HV01] - device dev1 is hot (48 C) 2. Notice [BWD-CCN-HV01] - device dev1 returned to normal temperature Does anyone know what is causing these emails to still trigger? Is there another setting I need to configure elsewhere to change this? It's just this single drive - none of the others trigger the notification. Similarly, whenever I log into Unraid, the dashboard doesn't even report temperatures anywhere near what the emails say for that drive, with them usually sitting around 33° Any help is appreciated, as these emails are extremely annoying! Thank you in advance.