




vvzvlad
Members
-
Joined
-
Last visited
Everything posted by vvzvlad
-
Three days passed and it happened again. What additional diagnostics can I do to figure out what to do? farewell-diagnostics-20220329-1210.zip

-
There are no tabs or active devices. Reboot what? The client device? Doesn't help, the error is the same on all devices. Server? It helps. But I can't reboot it every three days, given that rebooting is taking it out of service for an hour or more (stopping all dockers and virtual machines when rebooting is very long for some reason).
-
Good afternoon, this is the second time my server has stopped showing me the web panel, responding with "500 Internal Server Error". The ssh and samba access continues to work. Last time this happened three days ago. I am attaching the diagnostic files collected then and just now. I can see it in the syslog, but I don't understand what kind of error it indicates. Mar 26 19:21:15 Farewell nginx: 2022/03/26 19:21:15 [error] 10911#10911: *663875 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.88.90, server: , request: "GET /plugins/ipmi/include/ipmi_temp.php?unit=C&dot=. HTTP/1.1", subrequest: "/auth_request.php", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "192.168.88.111", referrer: "http://192.168.88.111/Apps" Mar 26 19:21:15 Farewell nginx: 2022/03/26 19:21:15 [error] 10911#10911: *663875 auth request unexpected status: 504 while sending to client, client: 192.168.88.90, server: , request: "GET /plugins/ipmi/include/ipmi_temp.php?unit=C&dot=. HTTP/1.1", host: "192.168.88.111", referrer: "http://192.168.88.111/Apps" Mar 26 19:22:41 Farewell nginx: 2022/03/26 19:22:41 [error] 10911#10911: *664172 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.88.90, server: , request: "GET /Apps HTTP/1.1", subrequest: "/auth_request.php", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "192.168.88.111", referrer: "http://192.168.88.111/Docker" farewell-diagnostics-20220326-1923.zip farewell-diagnostics-20220323-1541.zip
-
I often create virtual machines in scaleway or aws to test this or that software, put it on a clean machine, play around, and delete everything without dirtying the machines in production. That's handy. I'd like to do the same thing on unraid, but unfortunately the current process of creating a virtual machine is very much lost compared to the server creation interfaces in scaleway. In order for me to create a server there, all I have to do is: select the operating system, host name, disk capacity, wait two minutes, and you have a working virtual machine. In order for me to create a server on unraid, I have to: select machine parameters, ISO, disk capacity, run, wait for the installer to load, answer installation questions via vnc, then wait for packages to download and deploy the operating system, and so on. I see two ways to do this: The first is to do it once, and then only copy the image of the finished configured virtual machine. But simple copying causes problems with the files in /etc/libvirt/qemu/nvram, it is not enough just to copy the image of the machine, you must also understand what is the UUID of the machine and copy the nvram file so the machine will boot. This process has no GUI and every time I forget exactly what to do. The second is to have an ISO image that contains the basic packages and doesn't ask too many questions other than the hostname. The installation will still not be very fast, but at least it won't require as much attention. I found how to create such an image, but it's complicated and will take time. I'd like to know if anyone has done this before? In any case, I accept other comments on how I can solve the problem of quickly deploying test virtual machines with a preconfigured environment. I found a plugin: But it was made a very long time ago, and is apparently unsupported. It also lacks a "copy machine" button.
-
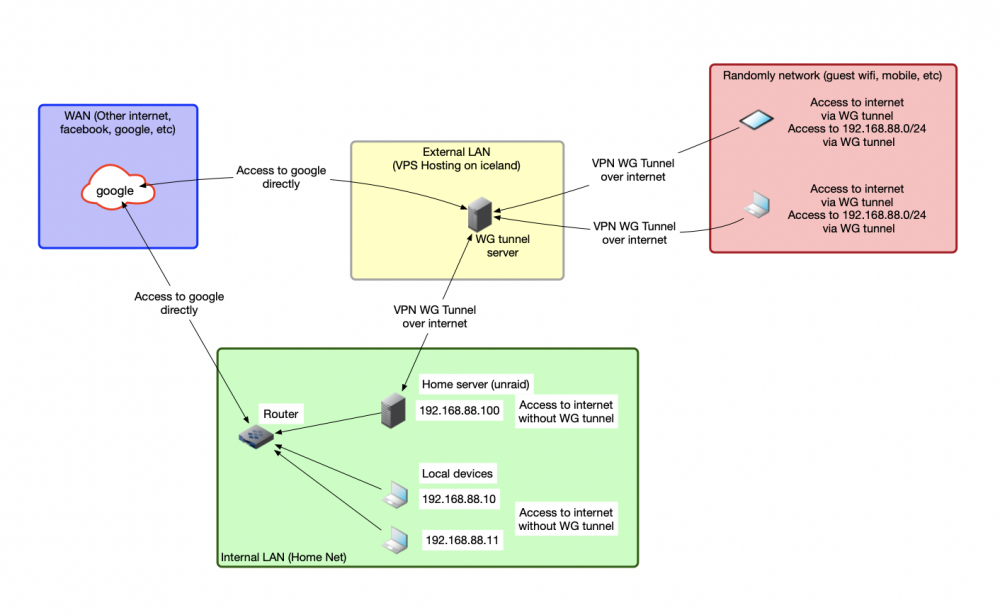
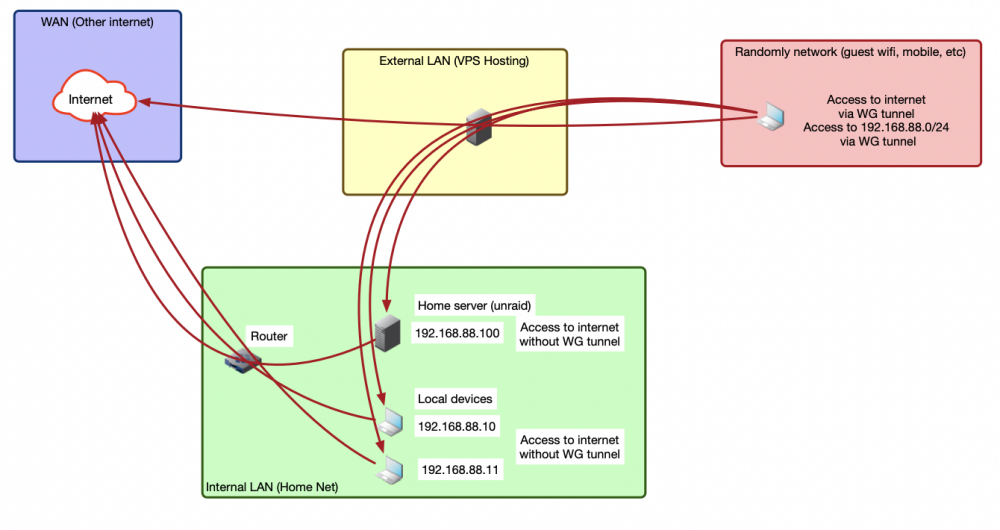
Good afternoon! I want to implement a somewhat complicated scheme that is beyond my understanding. I drew it in this picture (above). I have: 1)Home network (green) with an unraid server, several devices on the LAN (pictured as laptops, although they are other servers and a bit IoT, lol) and a router that they are all connected to. 2)A server on a hosted VPS (yellow) outside my city and country, which is used to protect traffic from mobile devices (red) that can (and constantly do) end up on untrusted networks. 3)Mobile devices (which I mentioned above) (red) - laptop, phone, tablet that access the internet via guest wifi or mobile network. 4)And external internet resources (blue) - any websites. I drew google there, but it's not necessarily him. These are all things I access through my ISP. Now I want to configure the VPN on Unraid so that the traffic flows like this: The mobile devices still access the Internet via a VPN that is on an external server. But at the same time, they access the home network 192.186.88.0/24, the server and the local devices. To do this, I need to make a connection where the server on the UNRAID connects to the front-end server via wireguard. (Or vice versa, the external server connects to unraid (it has a white address)). But I don't understand how I can set up a connection through the Unraid GUI that would connect it as a client to an external server. I see the server-to-server and lan-to-lan options, but I always get "Data received: 0 B Data sent: 35.5 KB Last handshake: not received" when I try to enter the standard wg client credentials generated on the external server there. I haven't found any documentation about these functions, google didn't help. Please help me.
-
Yes, it was OC_URLPATH, it was set to "/owncloud/", when set to "/" it worked.
-
My nextcloud server is running at https://nd.nl.tab.digital/ and has the following WebDAV address: remote.php/dav/files/[email protected]/ So I set "OC_WEBDAV" to "remote.php/dav/files/[email protected]/" and I get the following errors in the logs: 03-28 19:08:11:406 [ info sync.discovery ]: STARTING "" OCC::ProcessDirectoryJob::NormalQuery "" OCC::ProcessDirectoryJob::NormalQuery 03-28 19:08:11:407 [ info sync.accessmanager ]: 6 "PROPFIND" "https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/remote.php/webdav/" has X-Request-ID "af56746b-456d-40ef-a2e5-37c7404e5949" 03-28 19:08:11:407 [ info sync.networkjob ]: OCC::LsColJob created for "https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/" + "/" "OCC::DiscoverySingleDirectoryJob" 03-28 19:08:12:064 [ warning sync.networkjob ]: QNetworkReply::ContentOperationNotPermittedError "Server replied \"405 Method Not Allowed\" to \"PROPFIND https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/remote.php/webdav/\"" QVariant(int, 405) 03-28 19:08:12:065 [ info sync.networkjob.lscol ]: LSCOL of QUrl("https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/remote.php/webdav/") FINISHED WITH STATUS "ContentOperationNotPermittedError Server replied \"405 Method Not Allowed\" to \"PROPFIND https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/remote.php/webdav/\"" 03-28 19:08:12:065 [ warning sync.discovery ]: LSCOL job error "Error transferring https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/remote.php/webdav/ - server replied: Method Not Allowed" 405 QNetworkReply::ContentOperationNotPermittedError They clearly have the wrong address "https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/remote.php/webdav/\" Also, a strange error: "03-28 19:08:11:130 [ info sync.networkjob ]: Redirecting "GET" QUrl("https://nd.nl.tab.digital/owncloud/remote.php/dav/files/[email protected]/ocs/v1.php/cloud/user?format=json") QUrl("https://nd.nl.tab.digital/apps/dashboard/")" P.S. Using the description "ownCloud Server URL, with, if necessary, with port" for the OC_SERVER field is wrong, because the field requires the server address (nd.nl.tab.digital), not its URL (https://nd.nl.tab.digital/), as stated in the description.



