




samsausages
Members
-
Joined
-
Last visited
-
I had to deal with this again last evening after a reboot. May have a bigger issue here. If it happens again I'll report back, but usually don't do reboots often, so may be a while.
-
Great news! Glad it resolved it!
-
TLDR: The old docker macvlan network was bugged from the update. I had to remove it manually and recreate it. ---- Update on this, was looking at it more closely. I composed down all stacks & removed all docker networks to eliminate any potential conflicts and do more testing. On the docker settings page, I noticed that one of the networks, br2.10, doesn't have a gateway defined. Just shows -----. The others do have gateways assigned and when I attach containers it works. no way to edit that gateway, even with docker disabled. Resolution: Removed network manually with: docker network remove br2.10 (May give you an error, since it's bugged) Turned off docker. Checked Unraid Network settings and there still was an entry in the routing table for br2.10 Deleted entry manually. Went back to docker settings, now I could define a gateway IP for br2.10. Added entry. Enabled docker. Profit.
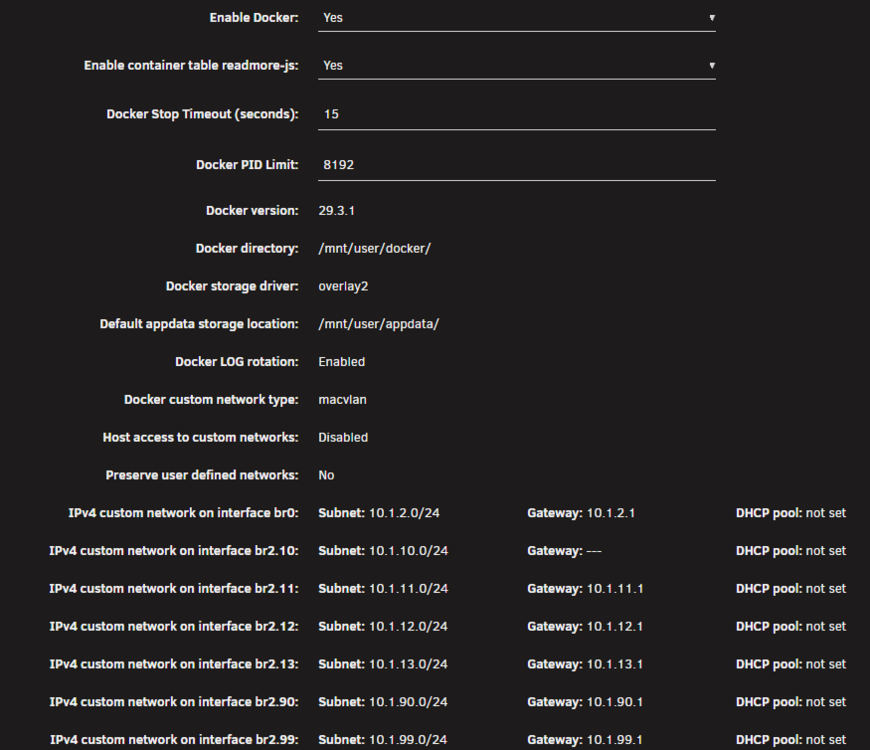
-
Going to 7.2.5 broke Nginx Proxy Manager for me as well. I'm using macvlan for the container. Tried ipvlan, same issue. Changed to dedicated docker network - works. With macvlan, I already had a MAC set in my docker compose file before updating. Tried without, or by changing it, no luck. No DNS resolution. ("communicate with host" is disabled) "getent hosts pypi.org" comes back blank. Docker container logs when on macvlan: [5/4/2026] [5:56:15 PM] [Certbot ] › ▶ start Installing cloudflare... [5/4/2026] [5:56:23 PM] [Certbot ] › ✖ error WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'NewConnectionError('<pip._vendor.urllib3.connection.HTTPSConnection object at 0x152a39cd0190>: Failed to establish a new connection: [Errno 101] Network is unreachable')': /simple/certbot-dns-cloudflare/ WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'NewConnectionError('<pip._vendor.urllib3.connection.HTTPSConnection object at 0x152a39cd0e90>: Failed to establish a new connection: [Errno 101] Network is unreachable')': /simple/certbot-dns-cloudflare/
-
Is blackwell supposed to work? I just got a new card and it's not showing up. AI tells me blackwell isn't supported in unraid yet. Can someone confirm before I pull the card out?||| FYI, error is: NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. I don't see the card anywhere in the device manager. Have tried reseating it, made sure 4g encoding and r-bar are enabled. Just confirmed it works in another PC. 6000 Pro Blackwell GPU bertha-diagnostics-20260205-1437.zip
-
I'm used to configuring a firewall on all of my servers, as I like to restrict all inbound and outbound traffic/ports. But I don't see an obvious way to do this on unraid. I have been relying on pfsense for this, but not ideal as I don't want to have a vlan just to isolate the unraid server. Is there a plugin or firewall service that I'm overlooking?
-
I understand. Just trying to tell people what's going on, as the question has been asked here and it's how I found this thread and previous posts made it sound like stable does not work on Linux.
-
Just wanted to give an FYI on the DayZ Server. This docker container uses the experimental branch. Yes, Dayz does run on linux using the Stable Branch. However, the stable branch requires you to log in with your steam account. I confirmed this installing on a Debian VM. Instructions here: https://community.bistudio.com/wiki/DayZ:Hosting_a_Linux_Server#top-page
-
TLDR: If you find that you still have leftover zfs datasets from when you had the ZFS storage Driver, run "zfs unmount dataset" and "umount /mount/location", then try removing the old docker datasets with "zfs destroy -r docker/dataset" Actions taken: Disabled docker in anticipation to switch from zfs storage driver to overlay2. Update to v7 from last stable version. Go to docker settings, used the "delete folder" and changed to overlay2 Compose up docker containers, everything looks fine. Look around and noticed with "zfs list" that all the datasets created by the docker zfs storage driver still exist. Stop docker. Delete docker folder contents. zfs destroy -r cpool/docker nothing happens cli stuck processing No logs other than confirmation of zfs destory command running cancel zfs destroy command. Try to stop array, nothing happens Reboot Upon boot, docker is still disabled. So I try to zfs destroy -r cpool/docker still same issue, nothing happens Try to delete just one docker dataset: zfs destroy -r cpool/docker/6a4f173927477f081f7cd22a560d2e3dd6bb82166190819ef083c0b309b73108 That works check for open files: lsof | grep /mnt/cpool/docker Nothing make sure dataset is unmounted: zfs unmount cpool/docker umount /mnt/cpool/docker umount /mnt/user/docker zfs destroy -r cpool/docker works Configure docker again with overlay2 driver OK check zfs dataset OK The only thing I could come up with that I may have done... not let the destroy task run long enough. I did wait several minutes and this is on NVMe. So I don't think that's it, but still a small possibility. But that still doesn't change that the "delete folder" action in the docker settings didn't delete the datasets and simply confirmed that the delete was successful. Maybe because I changed it to overlay2? So it didn't think it needed to run a zfs destroy command from the gui? If you need more info, let me know!
-
@limetech I do have a syslog server setup, but I don't have a good log aggregator setup, so digging through them is a bit of a pain right now. I did find the logs from last time I crashed, before I put the script in place. Attached are the relevant logs from right before and after that reboot. Looks like it crashed around 5am and I rebooted at about 5:35am If you need logs from another modules let me know, but pretty much everything else is just complaining about losing storage access. Nice to see a an attempt to fix it! I'm reluctant to try it right now because I can't easily roll back my zfs pools, so I'll probably just hang on unless that script stops working. unraid.log
-
@limetech No worries! With losing shares I mean that on the "shares" tab all the shares would be gone. Couldn't browse the shares even in the CLI and all containers/vm's that use storage crash. Doesn't matter if it's unraid array or cache. Disks would still show up on the "main" tab. I don't remember if I could still browse disks under /main/diskx, unfortunately. So I can't confirm if it was the fuse layer or the disk mount itself. A reboot would resolve the issue.
-
After losing shares about every 24 hours (did seem to depend on workload, usually when I ingested large amounts of data), I started searching for causes. There wasn't a specific error in the log so I had to go through trial and error. But my search lead me to people talking about the file limit, so I gave it a shot and I stopped dropping shares. My workload is mainly media, archiving and data hoarding, my stash is very large as I download entire youtube channels and entire websites, with hundreds of thousands of videos and well over 300TB on unraid. I have another server that runs Plex and connects to unraid using NFS. I also use a container that generates plex thumbnails in parallel, so it's faster, and a bunch of other services that process media. Running all those jobs often resulted in the array getting dropped. It's a 3rd gen Eypc server with 40tb in NVMe, and I do tax the system quite a bit when I have other systems accessing it to help process media. I did see it, rarely, without NFS. But it was so rare that I didn't worry about it, maybe once in 6 months. But when I moved my Plex to a 2nd server and added NFS for the file share, it got a lot more frequent, and when I started using containers to help re-build the plex thumbnails, it became a daily occourance.
-
I recently ran into a similar issue when adding an NFS share between unraid and my proxmox server. I'd lose shares after about a day. Looks like my issue was caused by unraid hitting the maximum open file limit, only set to 40k by default. I'm using this script to increase the file limit, haven't had any issues since: https://github.com/samssausages/unraid_scripts_and_fixes/blob/630629b0c40309f93626518f9f78472aa36fcc2c/unraid_increase_file_lock_limit.sh
-
The current version has been working great for me. If there is something you're missing let me know.
-
Kicking around the idea of replacing my parity drives with some dual actuator HDD's. Wondering if anyone has tried it yet and how performance is looking for them.



