




sjthomas
Members
-
Joined
-
Last visited
Everything posted by sjthomas
-
Short answer is I don’t know. I made some changes and haven’t encountered the same issue since, but as it was only occurring relatively infrequently, with potentially several weeks between, I can’t say with certainty. But so far, so good. I think the two most impactful changes I made were to enable DHCP Guarding (in case there were any other devices trying to issue leases - I don’t think there are, but belt and braces) and probably more importantly, removing the static IP setting from UnRAID and letting the router handle it instead (rather than both). I’m still monitoring though as it’s only been a week or so since i made the changes and the average time between occurrences for me was two weeks.
-
Agreed, definitely strange. What I think is happening is that something is causing UnRAID to create new virtual network interfaces that are being joined to the network with the same IP, causing a conflict. I think those weird MAC addresses are those virtual interfaces. But I'm not certain, and I don't know what's triggering them. I can't find any reference to them in the UnRAID UI. I'm tempted to remove the static IP allocation from my router and just have it on UnRAID, or vice versa, to see if it's catching some weird race condition or something.
-
I've updated the DHCP pool so the assignable range includes the static IP of the Unraid server. Unfortunately I'll have to wait to see if the problem occurs again as it can take up to 2 weeks, but I'll report back. I've also enabled DHCP guard in UniFi on the off chance that there's something else issuing leases (I don't think there is, but better safe than sorry). I'll report back with observations, but it may take a little while due to the length of time it takes for this to occur.
-
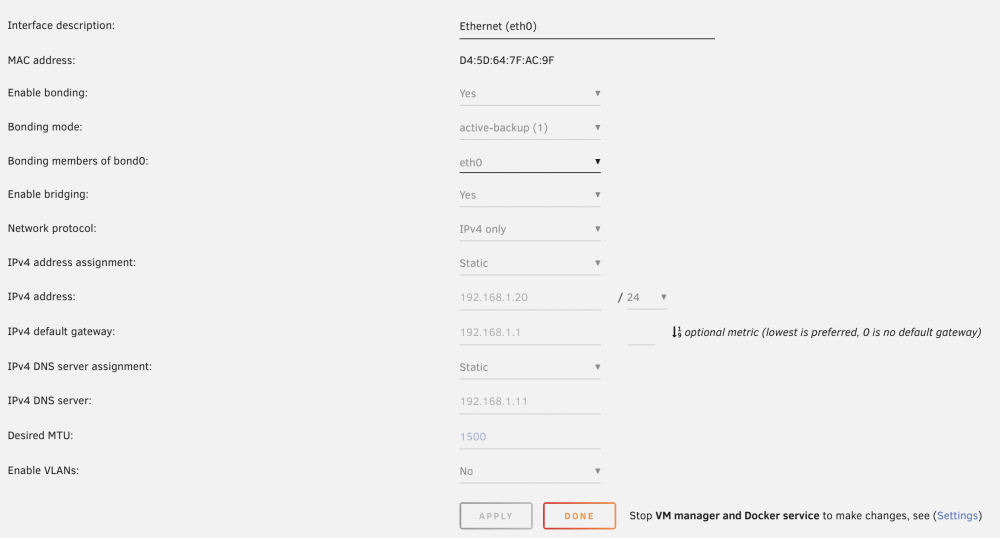
I seem to be having a slightly odd issue with my Unraid build that I can't seem to pin down. The symptom is that at seemingly random intervals (sometimes several weeks, sometimes just a couple of days) Unraid will leave my network and then rejoin with a new MAC address. This means I can't address it by its host name (toph.local), only by its IPV4 IP address. I have a static IP assigned to the original MAC, and looking at my router I can see that original config is still there and active (see screenshot below), but there's a new MAC address with the same IP address. Rebooting Unraid fixes it. This has happened a few times but today I managed to notice relatively quickly so I can see what's happening in the logs at the time. Unfortunately, they're not particularly insightful (apologies, lots of logs to follow). In the logs, shortly before this happens, flash_backup runs and outputs a websocket error: Aug 2 20:18:11 Toph flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup.php update Aug 2 23:19:17 Toph nginx: 2021/08/02 23:19:17 [error] 9666#9666: SUB:WEBSOCKET:invalid websocket close status code 22373 Aug 2 23:19:31 Toph flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup.php update Aug 2 23:49:34 Toph flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup.php update Aug 3 00:19:37 Toph flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup.php update Aug 3 00:50:40 Toph flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup.php update Aug 3 00:55:20 Toph crond[1894]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null I then, a little while (an hour) later, get a bunch of network config changes seemingly as a result of docker (I have several containers running - most of which are reached via ports but two have static IPs also assigned on the router): Aug 3 01:44:15 Toph kernel: docker0: port 10(veth875bc4a) entered disabled state Aug 3 01:44:15 Toph kernel: veth7bb5c6e: renamed from eth0 Aug 3 01:44:15 Toph avahi-daemon[7981]: Interface veth875bc4a.IPv6 no longer relevant for mDNS. Aug 3 01:44:15 Toph avahi-daemon[7981]: Leaving mDNS multicast group on interface veth875bc4a.IPv6 with address fe80::e44b:c8ff:feb5:f52c. Aug 3 01:44:15 Toph kernel: docker0: port 10(veth875bc4a) entered disabled state Aug 3 01:44:15 Toph kernel: device veth875bc4a left promiscuous mode Aug 3 01:44:15 Toph kernel: docker0: port 10(veth875bc4a) entered disabled state Aug 3 01:44:15 Toph avahi-daemon[7981]: Withdrawing address record for fe80::e44b:c8ff:feb5:f52c on veth875bc4a. Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered blocking state Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered disabled state Aug 3 01:44:16 Toph kernel: device veth327f93d entered promiscuous mode Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered blocking state Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered forwarding state Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered disabled state Aug 3 01:44:16 Toph kernel: eth0: renamed from vetha1e37f5 Aug 3 01:44:16 Toph kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth327f93d: link becomes ready Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered blocking state Aug 3 01:44:16 Toph kernel: docker0: port 10(veth327f93d) entered forwarding state Aug 3 01:44:18 Toph avahi-daemon[7981]: Joining mDNS multicast group on interface veth327f93d.IPv6 with address fe80::c00e:4fff:fee3:f51f. Aug 3 01:44:18 Toph avahi-daemon[7981]: New relevant interface veth327f93d.IPv6 for mDNS. Aug 3 01:44:18 Toph avahi-daemon[7981]: Registering new address record for fe80::c00e:4fff:fee3:f51f on veth327f93d.*. I then get a load of address withdrawals and registrations, and an error that there's a host name conflict: Aug 3 05:11:00 Toph avahi-daemon[7981]: Registering new address record for fe80::dcb9:4fff:fe7b:7b0a on shim-br0.*. Aug 3 05:11:00 Toph avahi-daemon[7981]: Registering new address record for fda9:5eaa:d065:1:dcb9:4fff:fe7b:7b0a on shim-br0.*. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for fd63:2af2:996f:1:dcb9:4fff:fe7b:7b0a on shim-br0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for fe80::dcb9:4fff:fe7b:7b0a on shim-br0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for fe80::c00e:4fff:fee3:f51f on veth327f93d. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for fe80::601e:bdff:feae:28d4 on veth94c4f2f. .... Tens more of these, presumably for every docker container I have running .... Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for 192.168.122.1 on virbr0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for 192.168.1.20 on shim-br0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for fe80::42:2cff:fe05:dc22 on docker0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for 172.17.0.1 on docker0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for 192.168.1.20 on br0. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for ::1 on lo. Aug 3 05:11:00 Toph avahi-daemon[7981]: Withdrawing address record for 127.0.0.1 on lo. Aug 3 05:11:00 Toph avahi-daemon[7981]: Host name conflict, retrying with Toph-2 Following this are a load of corresponding entries registering addresses, like this one: Registering new address record for fe80::c00e:4fff:fee3:f51f on veth327f93d.*. Then it appears to set the host name to Toph-2, I guess because "toph" is taken: Aug 3 05:11:02 Toph avahi-daemon[7981]: Server startup complete. Host name is Toph-2.local. Local service cookie is 2711267297. Aug 3 05:11:03 Toph avahi-daemon[7981]: Service "Toph-2" (/services/ssh.service) successfully established. Aug 3 05:11:03 Toph avahi-daemon[7981]: Service "Toph-2" (/services/smb.service) successfully established. Aug 3 05:11:03 Toph avahi-daemon[7981]: Service "Toph-2" (/services/sftp-ssh.service) successfully established. Followed by some more address registrations and clean up: Aug 3 05:20:40 Toph kernel: vethe94b699: renamed from eth0 Aug 3 05:20:40 Toph kernel: docker0: port 16(veth3169d37) entered disabled state Aug 3 05:20:40 Toph avahi-daemon[7981]: Interface veth3169d37.IPv6 no longer relevant for mDNS. Aug 3 05:20:40 Toph avahi-daemon[7981]: Leaving mDNS multicast group on interface veth3169d37.IPv6 with address fe80::ec6d:a9ff:fe3c:322. Aug 3 05:20:40 Toph kernel: docker0: port 16(veth3169d37) entered disabled state Aug 3 05:20:40 Toph kernel: device veth3169d37 left promiscuous mode Aug 3 05:20:40 Toph kernel: docker0: port 16(veth3169d37) entered disabled state Aug 3 05:20:40 Toph avahi-daemon[7981]: Withdrawing address record for fe80::ec6d:a9ff:fe3c:322 on veth3169d37. Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered blocking state Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered disabled state Aug 3 05:20:42 Toph kernel: device vethb903222 entered promiscuous mode Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered blocking state Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered forwarding state Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered disabled state Aug 3 05:20:42 Toph kernel: eth0: renamed from veth008f11f Aug 3 05:20:42 Toph kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethb903222: link becomes ready Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered blocking state Aug 3 05:20:42 Toph kernel: docker0: port 16(vethb903222) entered forwarding state Aug 3 05:20:44 Toph avahi-daemon[7981]: Joining mDNS multicast group on interface vethb903222.IPv6 with address fe80::28c5:1dff:fe03:1469. Aug 3 05:20:44 Toph avahi-daemon[7981]: New relevant interface vethb903222.IPv6 for mDNS. It then seems to go through this entire process again ultimately getting the host name toph-3.local, which works (but obviously isn't what services on my network expect). You can see this in the UniFi dashboard as follows: Different MAC address, same IP. Of note, I have a number of static IP addresses assigned to various devices and all are in the 192.168.1.0 - 192.168.1.99 range. The DHCP pool available for dynamic assignment is in the 192.168.1.100 - 192.168.1.199 range. ARP scaning reports the same as the UniFi dashboard. UnRAID network config looks like this: Where you can see the MAC address matches the static allocation, as does the IP. So where is this new MAC address coming from and what does it relate to? To reiterate, if I block that MAC address I can't access the UnRAID instance at all, not even by IP address, so it's clearly being used by the interface. It's also not there after a reboot, it appears after a seemingly random amount of time. I'm at a loss, so any help or ideas are greatly appreciated! UnRAID and UniFi are all up to date with latest stable releases.

-
I'm having some similar issues to others, in that the container hangs when trying to connect. I'm seeing a few errors in the logs that don't really make sense. The one that stands out is: If nothing happens, please visit https://join.nordvpn.com/order/?utm_medium=app&utm_source=linux Your account has expired. Renew your subscription now to continue enjoying the ultimate privacy and security with NordVPN Which isn't true. There's a year left on my subscription (just logged on to the site to confirm) and I've got another container using the same credentials to connect without issue. Credentials are copy & pasted, so 100% correct. Then: 2021/06/07 16:05:35 Get "https://os4work.com/v1/users/services": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) Which looks like a timeout issue. I've verified I can reach that domain ok from my network (but not from within the container, presumably because the IPTables rules have been set at that point?). Anyone got any ideas? I've got Nord working in another container (Transmission-VPN) fine with the same account right now, so it seems to be something odd going on with this one.

