




dellorianes
Members
-
Joined
-
Last visited
Everything posted by dellorianes
-
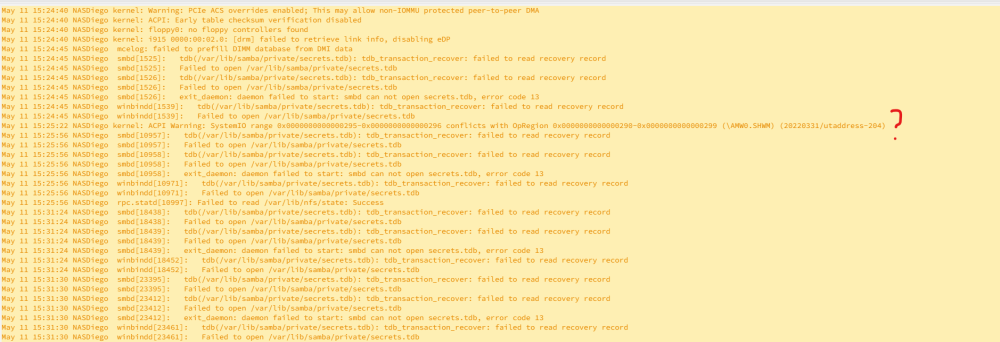
I proceed to delete smbpasswd and Reestart (I have to force the shootdown) the system. Once reestarted, smb continous not working. I checked that smbpasswd whas reseted (as you said without other users different than root). There are logs I am getting and the diagnostics file: nasdiego-diagnostics-20230511-1534.zip
-
The following shares are, between other, setup a smb shared: Andrea, Casa Regarding System Logs it a shows: In several periods of time Thank you again



-
Some days ago I found the array with all my disks unlocked. After rebooting the server all seems to be ok, but since then (I do not know if the problem existed before), I can not access my server via SMB from any device at home (Home Assistant OS, Android Mobile, Windows 11..) I tryed to stop the smb server, reestart the server and activate again but nothing changed. I have also tryed to make a share folder public but it cotinued not having access. Find attached my diagnostic file. Thank you very much nasdiego-diagnostics-20230511-1208.zip
-
The owner of the dms folder is root. I used the CA template, so no UID was defined. I applied "chmod 777 /mnt/user/appdata/dms" but the error continues. Thank you again
-
Hi, Trying to make first setup, when arriving to step "5. Try to connect to the server with an e-mail client.", I can add the account to my clients but when I try to send/receive an e-mail to my account it appears the following warnings in the log May 2 13:04:06 mail dovecot: [...] Error: Couldn't create mailbox list lock /var/mail/myaccount.com/diego/mailboxes.lock: file_create_locked(/var/mail/myaccount.com/diego/mailboxes.lock) failed: link(/var/mail/myaccount.com/diego/mailboxes.lockfacd1248548fb361, /var/mail/myaccount.com/diego/mailboxes.lock) failed: Function not implemented Any advise? Thank you in advance
-
What is the common speed for a single backup via sFTP? I always get 10 MB/S when doing that regardless of it is compressed or not. Is that a common speed? Thank you. Regards
-
any idea?
-
I want to run one script that runs 3 scripts in that way: Content of the script: ./script1 & wait && ./script2 wait && ./script3 I do not if it is possible and how to do it. What I want is to wait until previous script is fully finished until next script starts. How can I do that? I was searching but I did not find the question. Thank you very much.
-
This comment works for me.
-
I did and no changes.
-
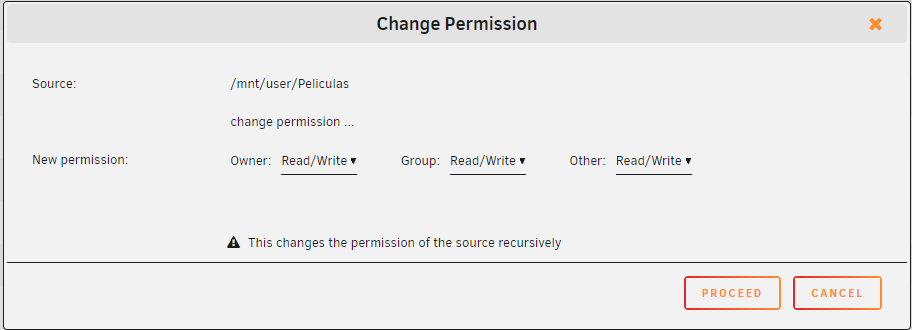
These are the permissions on Films and TV Shows, in all files (drwxrwxrwx)
-
The 192.168.29.5 IP is the IP of my QNAP NAS. I used it to mount the same folders than Oppo uses, in order to check that the setup was ok. The folders were mounted and all files available from QNAP NAS, so the prolem is between OPPO and UnRaid. Find attached current diagnostics Thank you ery much for your input. After adding UDP, rebooting the system and checking it: # rpcinfo -p | grep nfs 100003 3 tcp 2049 nfs 100003 4 tcp 2049 nfs 100003 3 udp 2049 nfs The Oppo continues detecting the shared folders but they continues empty. No changes. nasdiego-diagnostics-20221130-1830.zip
-
Once finished with parity, that was running, I have allready set up the RAM to 2133 Hz. After that, logs shows the following warnings: Nov 21 07:17:15 NASDiego kernel: Warning: PCIe ACS overrides enabled; This may allow non-IOMMU protected peer-to-peer DMA Nov 21 07:17:15 NASDiego kernel: ACPI: Early table checksum verification disabled Nov 21 07:17:15 NASDiego kernel: floppy0: no floppy controllers found Nov 21 07:17:15 NASDiego kernel: i915 0000:00:02.0: [drm] failed to retrieve link info, disabling eDP Nov 21 07:17:21 NASDiego mcelog: failed to prefill DIMM database from DMI data Nov 21 07:17:32 NASDiego kernel: ACPI Warning: SystemIO range 0x0000000000000295-0x0000000000000296 conflicts with OpRegion 0x0000000000000290-0x0000000000000299 (\AMW0.SHWM) (20220331/utaddress-204) Nov 21 07:17:54 NASDiego rpc.statd[8814]: Failed to read /var/lib/nfs/state: Success Nov 21 07:28:01 NASDiego kernel: EDID block 0 (tag 0x00) checksum is invalid, remainder is 182 Diagnostics included. Do I need to do something with tohose warnings? Thank you nasdiego-diagnostics-20221121-1018.zip
-
OK, thank you for the advice. Once changed to 2133, how I stabilize the system?? Is diagnostics ok?
-
After performing memtest86 appeared thousands of errors. Repeating the test with 2 from the 4 RAM cards, no errors during a compleate test. Repeting it with the other 2 cards, same result. Again repeating the test with the 4 cards, errors appears in less than an hour. My motherboard is: 4 x Memoria DIMM, Max. 64GB, DDR4 4266(O.C.)/4133(O.C.)/4000(O.C.)/3866(O.C.)/3733(O.C.)/3600(O.C.)/3466(O.C.)/3400(O.C.)/3333(O.C.)/3300(O.C.)/3200(O.C.)/3000(O.C.)/2800(O.C.)/2666/2400/2133 MHz Non-ECC, Un-buffered I was running the RAM at 3200, so, after changing them to 2666 MHz, I could complete 1 test without errors. This is the diagnostics file after changing. What should I do to stabilize the system?? Thank you again nasdiego-diagnostics-20221120-1017.zip
-
I return to the topic because this morning the server return to high cpu load values. Core 4 is continously at 100% load. I have 8 cores i7-9700 3000 MHz and 4x16 DDR4 3200MHz I tryed to get diagnostics but file doesn´t download ,as well as logs. I give attached the error and warning messages from logs (copy paste from the gui). after command: ~# btrfs dev stats /mnt/cache [/dev/nvme1n1p1].write_io_errs 0 [/dev/nvme1n1p1].read_io_errs 0 [/dev/nvme1n1p1].flush_io_errs 0 [/dev/nvme1n1p1].corruption_errs 48 [/dev/nvme1n1p1].generation_errs 0 [/dev/nvme0n1p1].write_io_errs 0 [/dev/nvme0n1p1].read_io_errs 0 [/dev/nvme0n1p1].flush_io_errs 0 [/dev/nvme0n1p1].corruption_errs 32 [/dev/nvme0n1p1].generation_errs 0 warning+errors_18-11-22.txt
-
Being imposible to know wich container was the culprit (they fail randongly on each reboot) I proceed to remove the docker image and built it again. Sistem is working fine since then.
-
Ok, I will try, but it is difficult to catch it. I have a window of some minutes since it starts increasing load until I can not access to the gui nor command line (and therefore I can not download the diagnostics file) and it random starts to increase. Since yesterday I was running on safe mode (running parity) and everything is running ok. May It be a docker issue?
-
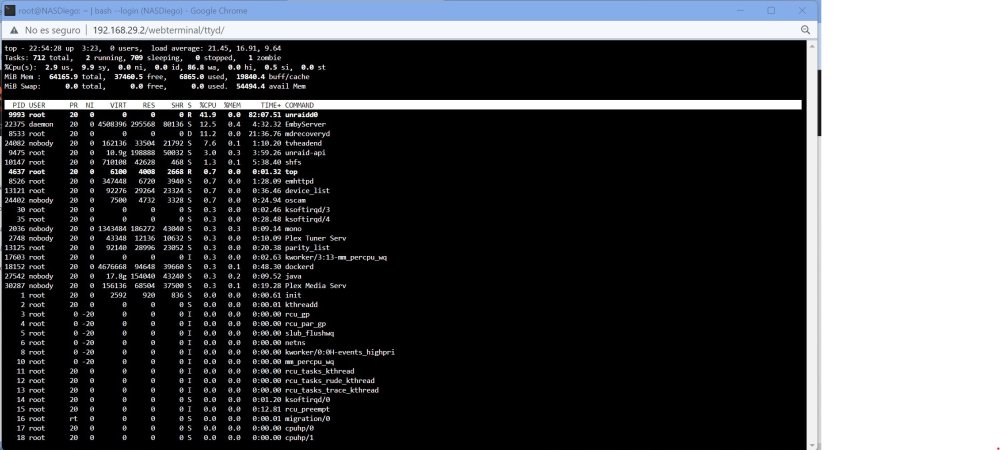
Hi, Since some days I suffer from high load average. Some minutes or hours after booting the load starts to increase until the system is overload and it is unreachable (nor shh, gui...) and forced me to do an unsafe shootdown Today I can take a photo when it starts to increase (another day I can see kworker rocketed too). Any idea how to deal? Thank you nasdiego-syslog-20221110-2223.zip
-
Thank you. Working again
-
After 6.11.1 install I have issues with the Wake on Lan of my VMs. Every time I reboot the sistem, the VM wake on lan service does not work even though I look as enable on VM settings (but status is stopped). Under Settings -> VM Manager -> Libvirt wake on lan -> Enable Wake On Lan , I have to disable, save and enable again on each reboot to have it working. Someone have an idea. As a patch, can someone recommend me a script that disable the wake on lan, save changes and enable it again on each reboot? Thank you
-
Solved in topic
-
I am suffering a problem with Wireguard (under Settings - VPN manager). I have it set up as usual but now my clients can not connect with the server. When I try starting the VPN, the clients show the following message: 2022-10-18 10:44:24.679: [TUN] [NASDiego_NUC] Starting WireGuard/0.5.3 (Windows 10.0.22000; amd64) 2022-10-18 10:44:24.679: [TUN] [NASDiego_NUC] Watching network interfaces 2022-10-18 10:44:24.686: [TUN] [NASDiego_NUC] Resolving DNS names 2022-10-18 10:44:24.753: [TUN] [NASDiego_NUC] Creating network adapter 2022-10-18 10:44:24.994: [TUN] [NASDiego_NUC] Using existing driver 0.10 2022-10-18 10:44:25.008: [TUN] [NASDiego_NUC] Creating adapter 2022-10-18 10:44:25.643: [TUN] [NASDiego_NUC] Using WireGuardNT/0.10 2022-10-18 10:44:25.643: [TUN] [NASDiego_NUC] Enabling firewall rules 2022-10-18 10:44:25.433: [TUN] [NASDiego_NUC] Interface created 2022-10-18 10:44:25.664: [TUN] [NASDiego_NUC] Dropping privileges 2022-10-18 10:44:25.665: [TUN] [NASDiego_NUC] Setting interface configuration 2022-10-18 10:44:25.666: [TUN] [NASDiego_NUC] Peer 1 created 2022-10-18 10:44:25.673: [TUN] [NASDiego_NUC] Monitoring MTU of default v4 routes 2022-10-18 10:44:25.672: [TUN] [NASDiego_NUC] Interface up 2022-10-18 10:44:25.713: [TUN] [NASDiego_NUC] Setting device v4 addresses 2022-10-18 10:44:25.775: [TUN] [NASDiego_NUC] Monitoring MTU of default v6 routes 2022-10-18 10:44:25.776: [TUN] [NASDiego_NUC] Setting device v6 addresses 2022-10-18 10:44:25.823: [TUN] [NASDiego_NUC] Sending handshake initiation to peer 1 (xx.xx.xx.18:51820) 2022-10-18 10:44:25.943: [TUN] [NASDiego_NUC] Startup complete 2022-10-18 10:44:30.840: [TUN] [NASDiego_NUC] Sending handshake initiation to peer 1 (xx.xx.xx.18:51820) 2022-10-18 10:44:35.953: [TUN] [NASDiego_NUC] Handshake for peer 1 (84.39.177.13:51820) did not complete after 5 seconds, retrying (try 2) 2022-10-18 10:44:35.953: [TUN] [NASDiego_NUC] Sending handshake initiation to peer 1 (xx.xx.xx.18:51820) 2022-10-18 10:44:41.024: [TUN] [NASDiego_NUC] Handshake for peer 1 (xx.xx.xx.18:51820) did not complete after 5 seconds, retrying (try 2) 2022-10-18 10:44:41.024: [TUN] [NASDiego_NUC] Sending handshake initiation to peer 1 (xx.xx.xx.18:51820) I have Local Server uses NAT as "NO" and a static rule in my router from the Local tunnel network pool IP to my Unraid Server IP. As it was working since the begining. Can someone help me? Thank you
-
Changed to cloudflare, swag is running again.
-
I suffered the same problem than you. That was the reason why I decided to unistall and install again.






