

S1ckh34d
-
Posts
16 -
Joined
-
Last visited
S1ckh34d's Achievements
")
Noob (1/14)
0
Reputation
-
Also ich habe die freien Tage jetzt mit testen verbracht: Zunächst habe ich die ETH1 aus der Bridge genommen > keine Änderung Die NIC im Bios komplett deaktiviert > keine Änderung Automatischen Start der Container deaktiviert > keine Änderung Die Netzwerk Konfiguration in Unraid von „IPv4 + IPv6“ auf „IPv4 only“ umgestellt > Fehler ist weg. Daher Sie jetzt gerade so aus als hätte Unraid / Docker ein Problem mit IPv6 beim Booten
-
Ich kann es mit einem billigen 1G Switch testen, ja da hast du natürlich recht. Reicht es dann eth1 aus der Bridge zu nehmen, oder doch besser "Enable bridging" auf "NO"? Bzw. kann ich dann die VM*s und Docker Container auf eth0 legen?
-
Dieses Konstrukt ist eigentlich ein Workaround da der bestellte Switch voraussichtlich erst im Februar 22 lieferbar ist. Nachdem der Server ja nicht so oft rebootet wird werde ich wohl erst mal damit leben und hoffe das sich das verhalten ändert wenn ich eth1 aus der Bridge rausnehme.
-
Das finde ich spannend so sieht es bei mir im Webinterface aus. Wie gesagt ich muss nach dem reboot Docker "nur" deaktivieren und wieder aktivieren damit das Netzwerk für die Container da ist.


-
Netzwerk Karten habe ich 2 Stk, einmal eine onboard Intel I219-V 1G und eine auf Realtek RTL8125 basierende 2,5G Karte beide sind in der Bridge. Die 2,5G Karte ist der UPLINK und an der 1G Karte hängt derzeit noch ein anderes System dran, somit wird der Server quasi als Switch missbraucht (ich weiß schön ist was anderes) Anbei die Zip Datei. tower-diagnostics-20211220-1344.zip
-
Hallo Community, ich habe einige Docker Container mit dem Network „br0“ so weit funktionieren die auch wie sie sollen. Ich habe jedoch das Problem, wenn ich Unraid reboote dann starten die Container nicht mehr. Ein „docker network list“ zeigt auch das hier das Netzwerk „br0“ vergessen wurde. Wenn ich jetzt bei Settings > Docker „Enable Docker“ von „Yes“ auf „No“ und anschließend wieder auf „Yes“ stelle ist plötzlich das Netzwerk „br0“ wieder vorhanden und auch die Container starten wieder. Was könnte hier der Fehler? lg.
-
Ich denke, nachdem das Problem erst nach einiger Zeit aufgetreten ist war das Plugin war schlichtweg einfach verwirrt. Falls noch jemand das Problem hat und über diesen Thread stolpert hier meine Lösung: Alle HDD aus dem Plugin rauslöschen, danach den Button "FORCE SCAN ALL" drücken und anschließend die Platten wieder den Slots zuweisen.
-
Danke für den tipp, hat mit "btrfs restore" wunderbar funktioniert, habe danach die SSD formatiert und die vorher wiederhergestellten daten darauf kopiert. Nach einem reboot vom System waren die Docker und VMs wieder da.
-
Hallo, Ich habe (leichtfertig) mit TOOLS > New Config, die HDD config zurückgesetzt, um nicht mehr vorhandene Laufwerke aus dem System zu entfernen. Dabei habe ich Funktion "Preserve current assignments" verwendet und anschließend die assignments der ausgebauten Platten entfernt. Das Array startet normal und durchläuft derzeit en Parity-Sync, soweit erst mal alles gut Später habe ich dann gesehen das die VM und Docker nicht laufen, und in weiterer Folge festgestellt, dass die Cache SSD zwar zugewiesen sind jedoch wird mir der Status "Unmountable: No pool uuid" ausgeben. Unraid bietet mir in weiterer Folge an die SSD's zu formatieren. Der Befehl "btrfs fi show" zeigt mit den btrfs pool mit der UUID an: Label: none uuid: a21a8035-4f1d-4569-9a7c-3e804cfd6d69 Total devices 2 FS bytes used 262.84GiB devid 1 size 465.76GiB used 285.03GiB path /dev/nvme0n1p1 devid 2 size 465.76GiB used 285.03GiB path /dev/nvme1n1p1 kann ich diesen pool bei unraid importieren oder sind die Daten verloren? Für Infos danke im Voraus

-
Ja das ist das Plugin "DISK LOCATION" (zugegeben hätte ich auch in den Topic schreiben können) Das Plugin dient eigentlich nur zur anzeige bzw. Doku in welchen Slot welche Platte verbaut ist.
-
Anbei zwei Screenshots
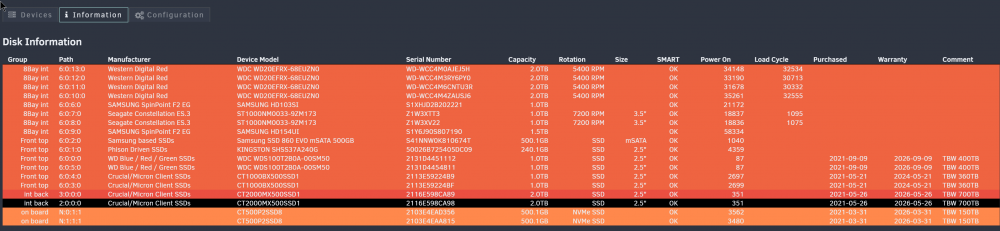
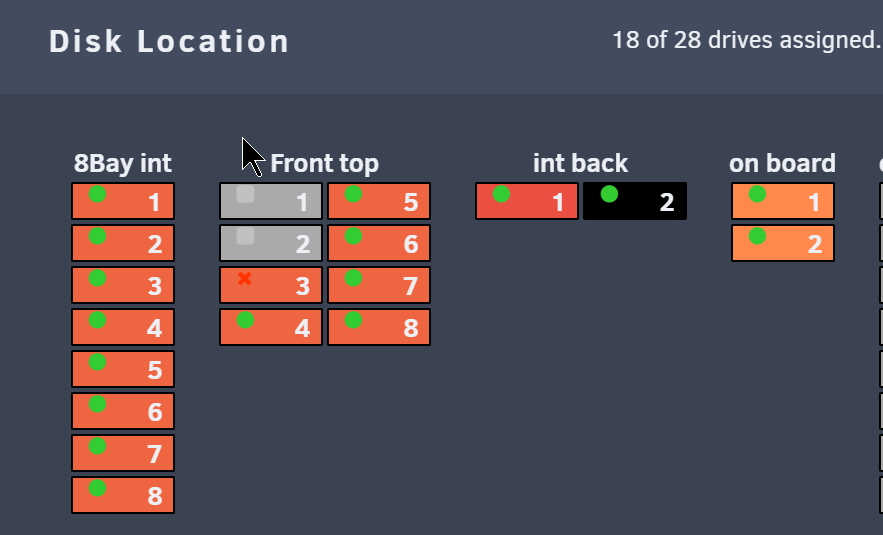
-
Hallo, mir ist gerade aufgefallen das mir bei Disk Location eine der beiden Parity disks schwarz angezeigt wird. Diese Farbe gibt es jedoch bei den Einstellungen nicht einmal einzustellen, hat jemand eine Idee was das bedeutet? Danke im Voraus
-
[6.9.2] Problem with size of replacement parity drive
S1ckh34d commented on S1ckh34d's report in Stable Releases
Thanks for this information, i will try to downgrade my installation. -
Hello, i have replaced my faulty parity drive with a new SSD. Now I can not start the array because unraid says: "Disk in parity slot is not biggest." I have checked the new drive and my second parity drive for "HPA" and size but there is no diffrence. root@Tower:~# hdparm -N /dev/sde /dev/sde: max sectors = 3907029168/3907029168, ACCESSIBLE MAX ADDRESS disabled root@Tower:~# hdparm -N /dev/sdo /dev/sdo: max sectors = 3907029168/3907029168, HPA is disabled tower-diagnostics-20210529-1509.zip
-
Ja diesen Thread habe ich eh auch schon gefunden, daher habe ich auch wie dort beschrieben die Größe der HDDs mit "hdparm" gecheckt, für mich schauen alle gleich groß aus. Auch wenn ich mir die alten sowie die neue Platte z.b. in "cfdisk" anschaue ist die Ausgabe der Sektoren sowie der Bytes identisch. Hier die neue: Disk: /dev/sde Size: 1.82 TiB, 2000398934016 bytes, 3907029168 sectors Label: dos, identifier: 0x00000000 Device Boot Start End Sectors Size Id Type >> /dev/sde1 64 3907029167 3907029104 1.8T 0 Empty Und hier exemplarisch eine der alten HDDs (die Ausgabe ist bei allen identisch): Disk: /dev/sds Size: 1.82 TiB, 2000398934016 bytes, 3907029168 sectors Label: dos, identifier: 0xb31d8a58 Device Boot Start End Sectors Size Id Type >> /dev/sds1 64 3907029167 3907029104 1.8T 83 Linux




