




patchrules2000
Members
-
Joined
-
Last visited
Everything posted by patchrules2000
-
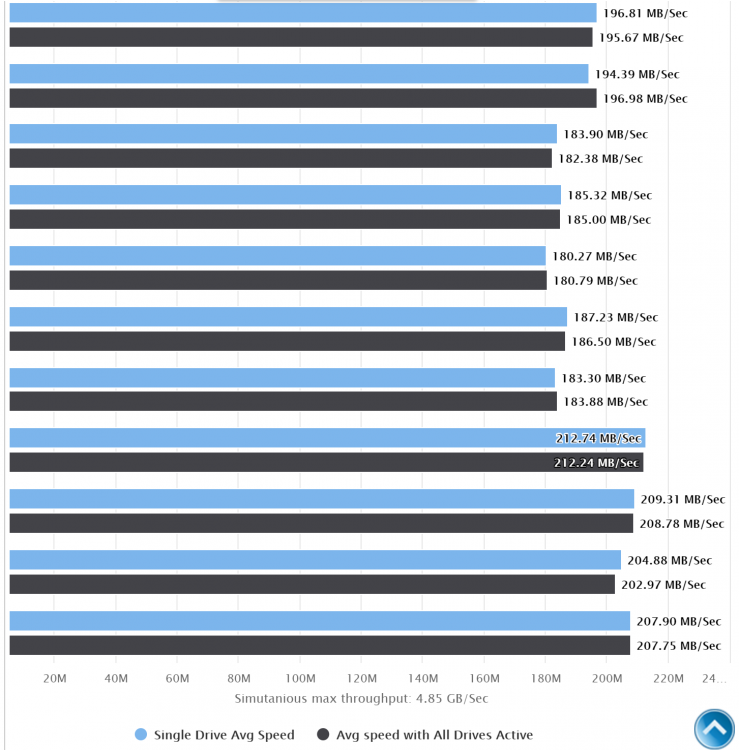
Haha, Happens to the best of us Update worked a treat! thanks for your help. I can now rest easy at night knowing im getting full throughput from my drives, all 4.85GB/s of it!!!! Also good to know i have some theoretical headroom of about 3GB/s for future expansion through expanders if i ever find a case to support that many drives. Thank you for supporting such a useful tool.
-
Hi Jbartlett, Thanks for working on the update. Unfortunately i updated to latest container and still getting the it showing version 2.2 in top left corner and still getting the same error. Even tried completely deleting docker image and all local files and reinstalling just incase it was cached wrong somehow and still not getting version 2.3 or removal of the error. Does it take a while for docker to propigate or is there something i need to do to force it to 2.3 (such as a beta branch or something)? Also just FYI SAS controllers (with expanders) can be connected to upto 256 drives! However that would be quite a large timeout value Just my thoughts on the issue as well for a future more robust fix. Would it be possible to change this value to be set as a variable not a constant to e.g "30seconds * #numofdrives" to fix any compatibility issues with different configs ? Alternatively a more reasonable general limit if that isnt possible would be the equivilent time needed for 32 drives as Unraids main array limit is 30 drives and a standard config usualy also includes 2 cache drives so 30+2 = 32 drives maximum on a "normal" unraid system. This would equate to a runtime of about 8 min's at your 15seconds per drive statement, so perhaps a 10 min timeout would be appropriate for this scenario? (Unraid techincaly does support 54 drives, 30 array, 24 cache. But that would be an extremely edge case and most likely never occur as the controller bandwidth bottlenecking would be something crazy if 30 array and 24 cache drives where being hit at once by users and all where on the same controller) Thanks for your help so far mate. Regards, Patrick
-
Hi all, hopefully you will be able to help. Just upgrade my unraid rig from two sas controllers to a single 24 port controller. I am trying to complete a controller benchmark but it keeps failing about 2/3 of the way through with a timeout error. I suspect it is because of a software constraint set by Diskspeed for the controller test as all drives pass testing with good speed and no other errors when run individualy for each drive. It fails around drive 16 of 24 every run through. Is there a config value i could change to increase this timeout limit (if that is the actual problem) to aproximately double to enable a full run through of the 24 drives. Thanks for your help :)



