




offroadguy56
Members
-
Joined
-
Last visited
-
OK I'm pretty sure I found the problem. The AIO that I had on the P40 has leaked. I never caught it because the tubes ran outside the case and had leaked onto the carpet. But I caught it this time when I reseated the video card and saw a water droplet on the tube. I'm going to assume that the card is either shutting off from thermal runaway or it has already fried. I'll see if thermaltake will warranty the cooler. Thankfully they still sell coolers with the same mounting style.
-
Minor update. I renabled the resize bar in the XML. Unfortunately I am away from the server and cannot check the BIOS. When the VM boots device manager says everything is ok. But when i try and execute CLI nvidia-smi. It tells me: unabel to determine device handle for 0000:09:05:0 GPU is lost. Reboot to recover GPU. I tried rebinding the GPU to VFIO on boot and the GPU still isn't working correctly. Getting the same as above. I guess now that I've complained about it it has stopped working entirely. I'll see if I can reseat the card and I'll take a peak in the BIOS to confirm above 4G decode and etc.
-
I thought so too. but when i upgraded from unraid 6.x.x to 7.x.x and installed windows 11 (fresh install from windows 10). I didn't need above 4g xml settings anymore. BIOS has remained untouched. IDK if the Tesla P40 has audio. Its a data center card of the GTX 1080 era. I am aware of this, but as #1 above. For some reason I never had to do this with the new windows 11 VM and updated unraid. This weird problem exists when using i440x and Q35. Chatgpt wants to suggest that unraid or a docker is keeping control of the video card. Hence the VFIO binding attempt. From my experience the above 4g decoding would just fail outright if it wasn't set correctly. Current conditions has the video card work for some while. Then after some time it'll show errors in windows. And a VM restart won't bind the card to the VM. It'll only work for a few hours my guess after a full server restart.
-
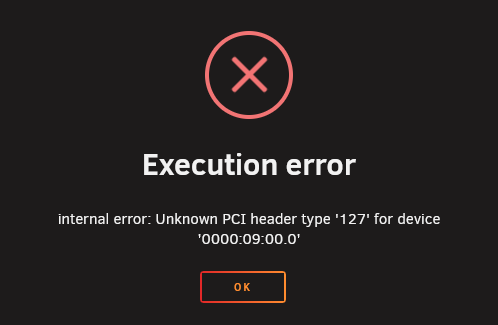
So I'm trying to get my windows VM to use my Tesla P40 video card. It was working fine in the past but now it is not. Nothing has changed between it working and not working (that i'm aware of). On a fresh restart of unraid I am able to boot the VM and use the video card as normal. After some time the video card becomes unusable. Windows inside the VM at this point will tell me everything is fine (the application using the card is the only one complaining) and device manager says everything is fine too. OR everything in Windows complains including device manager, saying something about error code 12. If I attempt to restart the VM after the video card error. I get this message: A search online said something about binding the video card to the VFIO on boot. So I did that and when I restarted unraid the entire server locked up when it attempted to launch the VM. I mean really weird stuff happened. SSH would fail but the webui would kind of load. sometimes not. commands on the console would take multiple minutes to execute. I managed to very quickly get into the VM settings and disable the VM service before the array could start allowing me to delete the libvirt.img and reset the VM settings. At that point I also disabled the VFIO binding not wanting to risk that again. So that is where I am at right now. If you need any more info let me know. waffle-diagnostics-20260423-1218.zip
-
Thanks a bunch. I've got disk6 rebuilding. Nightmare soon to be over.
-
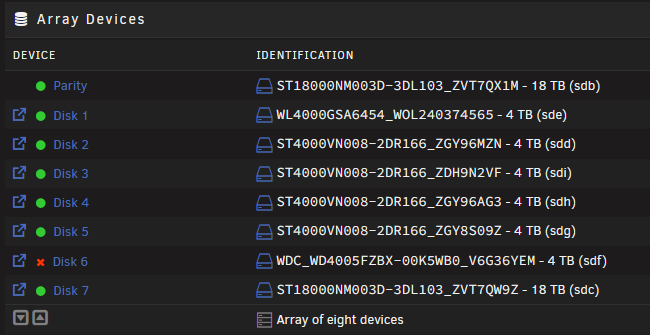
VM wrestling control away from the array was the issue. Started array, screenshotted VM settings, disabled VMs, deleted libvirt.img, stopped array, restarted array. That is where I am at now. I have disk 6 currently being emulated. Disks 3, 4 and 5 appear to be OK now. What I had done in restoring the cache drive was paste in my old libvirt.img. What you said with IDs changing makes sense now. Need to fix disk 6, then I manually set VMs back up. waffle-diagnostics-20260411-1700.zip
-
Linux still shows them connected under sdb to sdm. 8 drives show up under lsblk. Or am I seeing ghosts?
-
I have a 7 disk array + 1 parity. Unraid 7.1.2. I have been in the process of troubleshooting and recovering a corrupted zfs cache pool on the system. I backed up what I could outside of unraid and formatted the cache drives on unraid safemode. Cache drives are working as far as I can tell (2 drives striped). When I went into backup/restore appdata plugin to restore my dockers It told me directory could not be found. I checked my shares over SMB and windows errors out. I check on webUI and I'm told invalid path. I check on ls /mnt/disk3 and I'm told Input/output error. There have absolutely been unsafe shutdowns as the corrupted zfs pool would lock up unraid preventing a safe shutdown. Let me know how best to proceed. It's unfortunate that it's 4 disks instead of just 1. waffle-diagnostics-20260410-2000.zip
-
Thanks! I was curious why the device was loop2 instead of the original nvme0n1p1. I did try recsuing zero-log those devices, but was met with the "this isn't a btrfs file system" message.
-
Not sure how to troubleshoot this. I've had problems in the past when my cache was BTRFS. I would get periodic log tree corruptions. When Unraid began supporting ZFS I formatted the cache to ZFS and it was fine for many many months. Last month my Docker containers went down and I saw a BTRFS error in the server log. I disregarded it and restarted the server, everything fixed itself. It's happened again today and multiple restarts later, Docker will not start. Steps I've taken to remedy: rescue zero-log command (says no valid BTRFS found), restarts, reseating cache drive, reseating memory, confirming memory speed (too fast causes me problems), safe mode. Notes: The VM manager appears to be working just fine. I have a windows VM running exclusively on the cache drive and it appears unaffected. Browsing SMB shares located on the cache works fine too. Attached is my diag. Version 6.12.10. If URbackup has been doing its job I'll have proper backups of what I care about from the windows VM. I have appdata backup plugin running as well so docker container info is covered too. waffle-diagnostics-20241126-2103.zip
-
Trying to get this to work with reverse proxy. Currently using NPM. When I create a share link, the link is correct with my domain. But when I navigate to that link all I get in return is a blank page. After a little bit the browser returns "This site can't be reached". Navigating to the shared link with local IP address results in it working just fine. Photoprism is complaining about websockets not working. I've input their config in the proper place in NPM but it causes the proxy host to go offline. Does anyone have a working config for NPM? I am also looking at Traefik which was mentioned in photoprism's documentation. EDIT: I had websockets disabled in NPM. When I enabled it the proxy host went offline. I removed all the extra config from the advanced tab and re-enabled websockets and now that is correctly working. As for the blank page/page not loading issue, I had the docker form incorrectly configured. In the "PHOTOPRISM_SITE_URL" field the site url needs to exclude the port number. With those changes I am no longer experiencing any issues or warnings.
-
Pretty much. In a way it makes sense if it were an Unraid or Docker issue for it to affect all the containers, but instead it was only a select few. If your containers are communicating properly and all you are missing is the shortcut link to the webui, all you'd need to do is bookmark the webui by first navigating to it manually. My issue unfortunately meant my containers would not communicate with each other. No idea what the issue was.
-
I finally tried rolling back the docker image to a previous image. It's finally working now. Not sure what the issue was. Very strange to me to see it happen to multiple containers.
-
@joelonesI believe I found a fix for our problem. Through a lot of troubleshooting of network settings among other things. I completely forgot that the appdata backup plugin doesn't roll back the actual docker image. What I've done is rollback the problem docker containers to 2 months ago and they are working properly in the docker list and are able to communicate with each other. You might be able to get away with a more recent roll back, but for me it's good enough. What you'll need to do is click the container and select more info. It should take you to the docker page. Click tags then find an suitable previous version. on the right you'll see "docker pull ...." copy whats after docker pull and paste it into the repository field on the docker edit page in unraid. For example mine looks like "binhex/arch-privoxyvpn:3.0.34-3-02"
-
Linked above is another user with the same or similar problem to myself. The short of it is our IP address and port that we assigned on a custom network doesn't show up in the GUI. I can navigate manually to the ipaddress:port and access the webui. When I click the webui button on the container, nothing happens. The container won't communicate with other containers also. I have 3 broken containers; a vpn proxy, an indexer, and a download client. I feel the problem isn't just affecting the broken ones but the working ones as well. I have a 2nd indexer and download client and they too can't communicate with each other despite their appearance in the docker list being correct. Their webui work fine. I have cloud storage using a mariadb container and collab for documents, it's communication with those 2 containers seem to be unhindered. I have a reverse proxy running as well, as far as I can tell it is working perfectly fine and forwarding me to the correct services. For the other user, @joelones, it broke after an OS update. Rolling back didn't fix. For me it broke when I added a new drive to the array. I did an unbalance of the shares to move files to the new drive. I also ran docker safe new permissions as unbalance instructed me. Recent testing shows that newly installed containers will assign their default port and work standalone. But when I set them to a different port that change never reflects on the docker list nor when navigating to the webui. If I install a new container and utilize the Bridge network. It assignes the 172.17.0.x IP and the container port is as it states and the 192.168.1.x port is also correct showing the changed port from default. I did testing with my broken containers switching to Bridge network and they won't communicate with each other. Not with 172 or 192 IP address in their settings. You can check the other post for info I might have missed. But I think the meat of it is above. Attached is my diag. All my dockers run on the custom network. There are some on host or bridge. They were either required to be there to work or they didn't have functioning purpose to be on the custom network. I have full backups dating back to May of both docker and Unraid. Have held off on restoring a backup of Unraid until I can understand the problem better, and that it didn't fix the problem on the other post. Normally I have interest to troubleshoot and find the problem so it can be documented. At this point, I just want my services working again. If a nuke is what it takes, I've got backups. waffle-diagnostics-20240731-1235.zip


