




rsbuc
Members
-
Joined
-
Last visited
-
Sure! see attached This log has my array going from normal temps to 57c which is above my CRIT level. syslog.txt
-
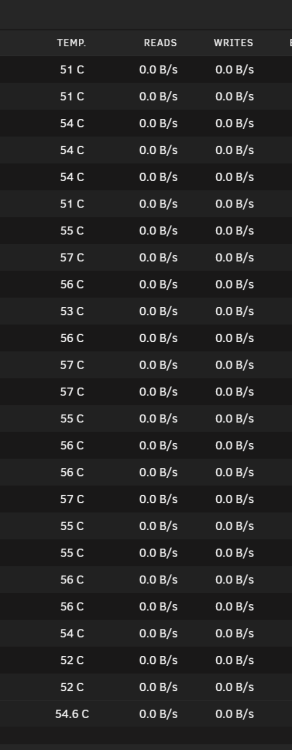
Hello! I was having an issue before where my Incremental parity checks were not reading the disk temperatures correctly when the disks had spun down (they were reporting "=*". I have updated to the latest version of the Parity Tuning Script, and now the script doesn't appear to be collecting/detecting the disk temperature at all anymore. here is a snippet from the syslog (with Testing logs enabled) *** Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR ----------- MONITOR begin ------ Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR /boot/config/forcesync marker file present Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR manual marker file present Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR parityTuningActive=1, parityTuningPos=886346616 Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR appears there is a running array operation but no Progress file yet created Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR ... appears to be manual parity check Mar 11 13:30:22 219STORE Parity Check Tuning: DEBUG: Manual Correcting Parity-Check Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR MANUAL record to be written Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR Current disks information saved to disks marker file Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR written header record to progress marker file Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR ... appears to be manual parity check Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR written MANUAL record to progress marker file Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR Creating required cron entries Mar 11 13:30:22 219STORE Parity Check Tuning: DEBUG: Created cron entry for scheduled pause and resume Mar 11 13:30:22 219STORE Parity Check Tuning: DEBUG: Created cron entry for 6 minute interval monitoring Mar 11 13:30:22 219STORE Parity Check Tuning: DEBUG: updated cron settings are in /boot/config/plugins/parity.check.tuning/parity.check.tuning.cron Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR CA Backup not running, array operation paused Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR ... no action required Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR global temperature limits: Warning: 50, Critical: 55 Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR plugin temperature settings: Pause 3, Resume 8 Mar 11 13:30:22 219STORE Parity Check Tuning: DEBUG: array drives=0, hot=0, warm=0, cool=0, spundown=0, idle=0 Mar 11 13:30:22 219STORE Parity Check Tuning: DEBUG: Array operation paused but not for temperature related reason Mar 11 13:30:22 219STORE Parity Check Tuning: TESTING:MONITOR ----------- MONITOR end ------ *** the parity check tuning clearly shows "Warm=0, Cool=0, Spundown=0" but there are several disks above 55c. and heres a screenshot of the disk temps in the webui. (thanks again for reading this message)
-
No worries, I appreciate the effort, if you'd like more info let me know.
-
I've finally had a few mins to test this out with the TESTING log mode enabled. I think you were hinting at what I've seen. When the array goes into 'overheat mode' and the parity check pauses, the disks eventually spin down and the temperature value in the log goes to "Temp=*" instead of showing an actual Temperature value, so the Parity Check Tuning script doesn't see a valid numerical temperature value to resume the parity check process. after waiting ~12minutes, I manually clicked 'spin up disks' and then 6minutes later the parity check process resumed as it was able to see the temperature values when the disks were spun up. I'm attaching my syslog. syslog.txt
-
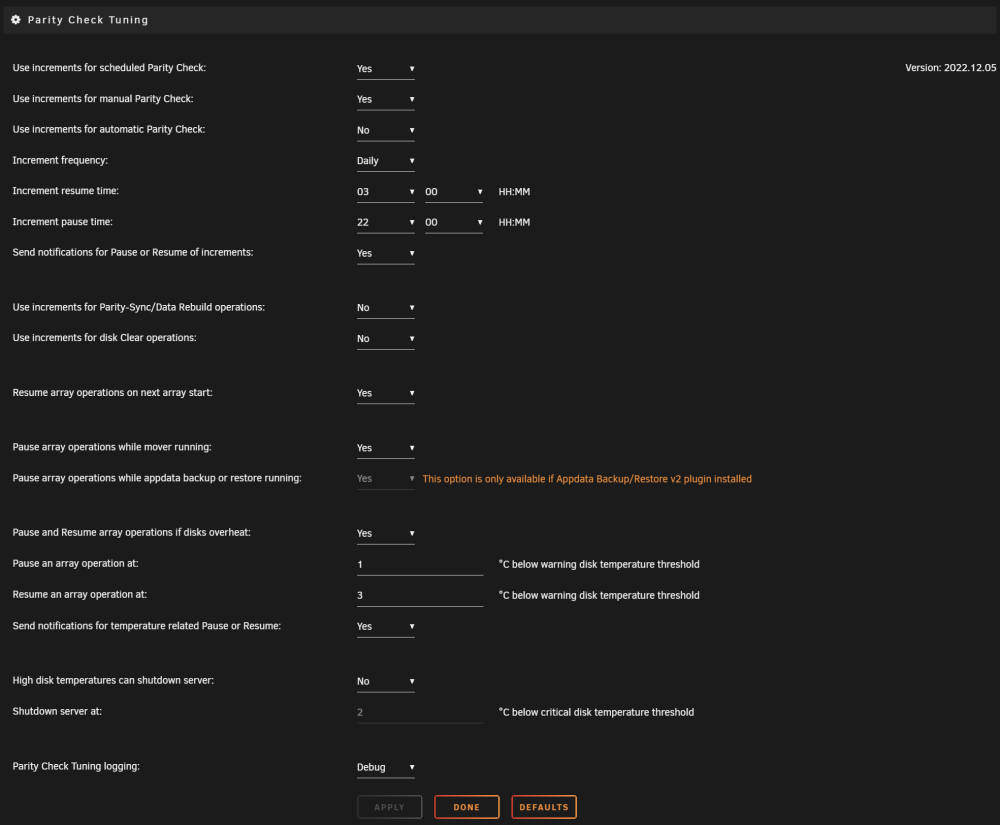
Interesting, I've enabled Debug logging, and that totally demystifies a lot of what the plugin is doing (Thanks for that). Here is what I'm seeing (I'm sure I have a bad setting or something) -- I start the parity check, it runs for an hour or so, then the hard drives hit their temperature limit, and the parity check pauses. The drives spin down, and the drives cool off, but the plugin doesn't seem to resume the parity operations. If I "Spin up all disks" it will detect the drive temperatures as being cool again and resume the parity check. are there special disk settings that I need to enable for this to work properly? (also, thanks again for trying to helping me out!)

-
Hello! Am I understanding this correctly? The plugin will pause the parity operation when the disks reach the temperature threshold and wait until the temps fall below the temperature threshold value -- then the script immediately resume the parity operations? or will it only attempt to resume after the 'Increment resume time' schedule?
-
Hey Everyone! I've been trying to get the "Increment Frequency/Custom" working for what I need, but I'm struggling. I have cooling issues with my Unraid, and what my goal is to allow the the Parity Check to 'Pause when disks overheat', then have the Custom Increment frequency pause the Parity operations for ~30mins to let the disks cool down, and then resume (or at least check if the disks are cooled down enough) and then Resume parity operations. Clearly my cron skills are weak, is there an "Increment Resume Time" and "Increment Pause Time" that someone can suggest? (thanks again for all the awesome features in the Parity Check Tuning plugin!)



