




techlovin
Members
-
Joined
-
Last visited
Everything posted by techlovin
-
Thanks for checking out this topic. I recently hit the 30 drive limit and after researching a bit I've come to realize I probably don't have my server setup as intended for best practice. At the moment I've got 29 drives connected with 2 of those drives being parity drives, and I have a Super Micro 36 bay chassis I'm looking to fill up. I currently have about 200 TiBs of Linux ISOs on the Array that would not be considered mission critical and can easily be replaced should a drive fail unprotected. My intent is to setup a pool of drives to move all of my Linux ISOs to this pool, and leave everything I would like protected on the Array. Now my question, can I set up the pool with a JBOD sort of arrangement? Are there issues mixing and matching drive manufactures, drive-speed, size, and type? The large majority of my drives are Seagate EXOs drives but they range from 12 to 16 TBs, with only a few 8TB WDs in the mix.
-
Issues with my Plex db caused the container to consume all available RAM, eventually grinding my server to a complete halt killing off most functionality. After several hours Unraid would kill the process consuming all available memory and service would be restored. No issues with the Plex scheduled tasks turned off. I noticed some Plex log entries about this that made me believe the scanner was getting hung up trying to match some of the files. I deleted my hentai library which was using the hama.bundle plugin. Turned the tasks back on yesterday after deleting a few libraries, and did not notice the memory issue or my server locking up. Will monitor for a couple days and If no more issues crop up I'll mark this as resolved.
-
This is absolutely an issue with my Plex docker. Memory keeps ballooning during PlexScan and locking up the server until the process is killed.
-
Agreed, I may have been too hasty in assuming it was a crash. It happened again this morning and I just ignored it, left it to go to work and noticed it was online without requiring me to force shutdown. Reviewed the logs (mirrored to flash) and I see a massive wall of stuff happening around 5-6hrs after it went offline. I've attached the log, can anyone explain what I'm seeing there at line 2544, at Jan 1 09:13:30? Update: Well damn! Just noticed I have scheduled tasks to begin in Plex at 3AM, this is when my issues are popping up around 3:15am!!! Referencing the syslog I can see an out of memory warning... Not sure where things went wrong but I must've accidentally mis-configured something. Though I haven't touched my Plex settings in several months as far as I recall. Any tips on what to check for these memory issues with Plex? (Reminder, my RAM passed an exhaustive memtest.) Update2: My working theory is my Plex db may have corruption. Running an integrity check on it now. Following this guide. Not sure how long it will take, need to sleep, will check back in the morning.
-
10 passes, 18+ hrs and no errors. Definitely looks like its not a memory issue. I've replaced the flash drive, and I've disabled C states globally. I'm pretty sure this is a software issue, whether thats something with my dockers, or something Ive configured in Unraid.
-
I'm currently on Pass 3 of Memtest without any errors. Planning to go for the rest of the day.
-
Attached the most recent diagnostics, friday-diagnostics-20231231-0337.zip
-
Shutdown again, at exactly 3:15am, nothing in the syslog. Froze, couldn't access the GUI, shares, or any containers. Is there someway I can check to see what it may be doing at that time? I've connected a monitor to it so that I might be able to see something. I've set up the syslog to mirror to flash in-case something is being missed. Edit: Each time it's done this the last three days I could see the light blinking on my Unraid flash drive. I waited it out once for a couple hours but it was still down. The last two days I've just been doing an unclean shutdown and rebooting. While it happens I'm just streaming Plex from my server. Edit2: Went down again, less than 45mins after the first freeze. Running MemTest now, will update this thread after an extended test.
-
Noticed a warning in my syslog. 2023-12-30T22:35:01-08:00 Friday kernel: TCP: request_sock_TCP: Possible SYN flooding on port 8181. Sending cookies. Check SNMP counters. :8181 is my Tautulli container. Checked logs and found the following. 2023-12-30 22:35:40 - ERROR :: CP Server Thread-9 : Failed to access uri endpoint /status/sessions. Request timed out: HTTPConnectionPool(host='192.168.1.10', port=32400): Read timed out. (read timeout=15) 2023-12-30 22:35:40 - WARNING :: CP Server Thread-9 : Tautulli Pmsconnect :: Unable to parse XML for get_current_activity: 'NoneType' object has no attribute 'getElementsByTagName'. 2023-12-30 22:35:40 - WARNING :: CP Server Thread-9 : Unable to retrieve data for get_activity. 2023-12-30 22:35:44 - ERROR :: Thread-17 (run) : Failed to access uri endpoint /status/sessions. Request timed out: HTTPConnectionPool(host='192.168.1.10', port=32400): Read timed out. (read timeout=15) 2023-12-30 22:35:44 - WARNING :: Thread-17 (run) : Tautulli Pmsconnect :: Unable to parse XML for get_current_activity: 'NoneType' object has no attribute 'getElementsByTagName'. 2023-12-30 22:35:59 - ERROR :: Thread-17 (run) : Failed to access uri endpoint /status/sessions. Request timed out: HTTPConnectionPool(host='192.168.1.10', port=32400): Read timed out. (read timeout=15) 2023-12-30 22:35:59 - WARNING :: Thread-17 (run) : Tautulli Pmsconnect :: Unable to parse XML for get_current_activity: 'NoneType' object has no attribute 'getElementsByTagName'. {REPEATED} 2023-12-30 22:57:00 - ERROR :: CP Server Thread-7 : Failed to access uri endpoint /status/sessions. Request timed out: HTTPConnectionPool(host='192.168.1.10', port=32400): Read timed out. (read timeout=15) 2023-12-30 22:57:00 - WARNING :: CP Server Thread-7 : Tautulli Pmsconnect :: Unable to parse XML for get_current_activity: 'NoneType' object has no attribute 'getElementsByTagName'. 2023-12-30 22:57:00 - WARNING :: CP Server Thread-7 : Unable to retrieve data for get_activity. 2023-12-30 22:57:27 - WARNING :: CP Server Thread-11 : Failed to get image /library/metadata/281641/thumb, falling back to poster. 2023-12-30 22:57:27 - WARNING :: CP Server Thread-8 : Failed to get image /library/metadata/281635/thumb, falling back to poster. Now this looks like something that could bring my server down, doing some research it looks like I may need to adjust some settings in the container or on my firewall.
-
I have not, I've been avoiding it. It's my Plex server and I'm addicted, LOL. All of the issues I had with the Web GUI partially loading have been resolved by deleting all of my plugins. The only issue that remains is it locking up at night around 3:15am.
-
That directory does not appear to exist. I did look through the cron.d directory and found one file named root, and have attached a screenshot of its contents.
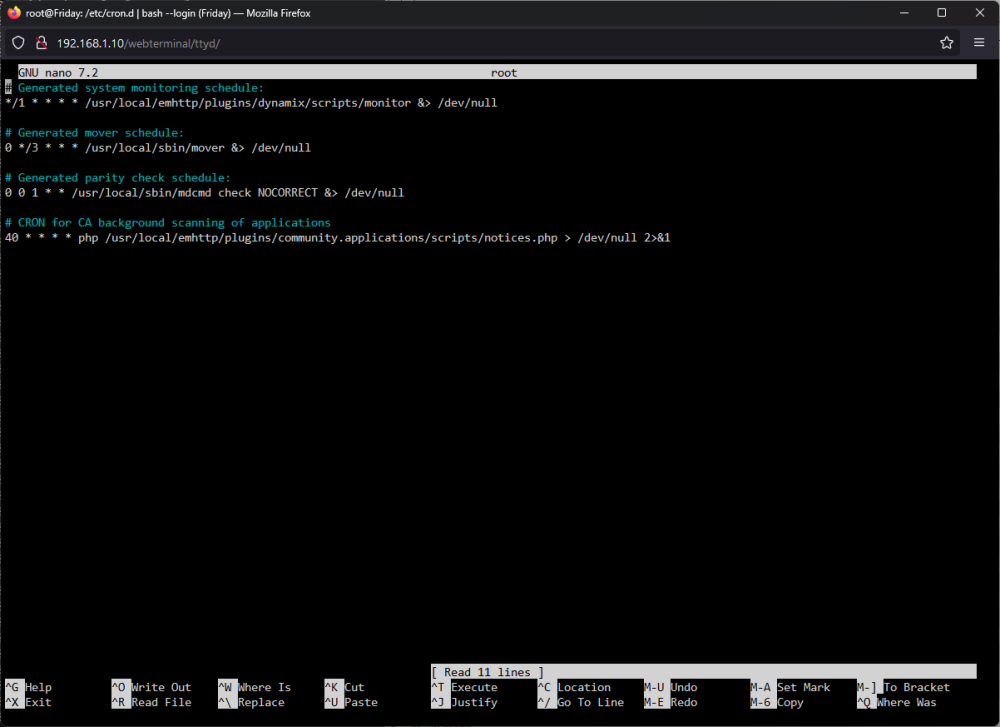
-
Server locked up again, it seems to be happening every night/morning at 3:15am approximately. Syslog had no meaningful info around the crash/lock/freeze. 2023-12-29T21:52:48-08:00 Friday monitor: Stop running nchan processes 2023-12-29T23:18:52-08:00 Friday webGUI: Successful login user root from 192.168.1.203 2023-12-29T23:19:21-08:00 Friday monitor: Stop running nchan processes 2023-12-29T23:41:24-08:00 Friday monitor: Stop running nchan processes 2023-12-30T00:23:28-08:00 Friday monitor: Stop running nchan processes 2023-12-30T01:43:02-08:00 Friday monitor: Stop running nchan processes 2023-12-30T03:07:20-08:00 Friday webGUI: Successful login user root from 192.168.1.203 2023-12-30T03:08:05-08:00 Friday monitor: Stop running nchan processes 2023-12-30T03:16:27-08:00 Friday emhttpd: Starting services... I'm currently using a new flash drive, though considering the consistency in timing I don't think this is a hardware issue.
-
I've prepared a new flash drive, hopefully it's not my RAM cause I don't have any spares on hand.
-
Woke up again to my server completely frozen. Tried removing unraidsafemode from boot to look at my plugins but the WEB Gui would fail to load as it did in the screenshot above. Booted back into Safe Mode. Noticed these entries in the syslog before it went down. 2023-12-28T14:10:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T15:07:00-08:00 Friday monitor: Stop running nchan processes 2023-12-28T15:07:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T16:05:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T17:03:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T18:00:02-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T18:58:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T19:56:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T20:54:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T21:20:58-08:00 Friday webGUI: Successful login user root from 192.168.1.69 2023-12-28T21:21:35-08:00 Friday monitor: Stop running nchan processes 2023-12-28T21:28:08-08:00 Friday monitor: Stop running nchan processes 2023-12-28T21:43:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T22:42:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-28T23:41:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-29T01:09:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-29T02:07:01-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || : 2023-12-29T03:00:57-08:00 Friday crond[1866]: failed parsing crontab for user root: *"2,4,¶,8(90,12 1˛ $(date +%e -d -7days) -le w ]] && /usr/local/sbin/mdcmd check NOCORReCT &> /dev/null || :
-
Set "Power Supply Idle Control" to Typical Current Idle, and also disabled C-States from the BIOS. I'm not concerned with the power consumption of my server and would prefer as much stability as possible with my Ryzen build. Will update this post tomorrow with status.
-
I don't recall ever adjusting power control in the BIOS to mitigate issues with C-States. I'll work on addressing that issue, and will follow back up tomorrow.
-
Yes, enabled the server, and set up a rpi for logging. Not sure if I should've went and mirrored to the flash drive (I was trying to avoid potential wear as there was a warning about that.) I've attached the syslog. You can see on line 16 the last reported entry before I had to long-press the power button to shutdown. 2023-12-28T01:21:43-08:00 Friday monitor: Stop running nchan processes
-
Well sometime in the night while I was sleeping the server froze up again. I could PING it this morning, but the WEB GUI, Docker, and Shares were all inaccessible. I'm working on replacing the flash drive, because I have no idea what else to look for. I've also run another set of diagnostics.
-
I'm trying to do some research on Unraid's safe mode option, I would like to know what all it actually does besides booting without Plugins. In Windows you have a very basic, stripped down version of the OS with minimal drivers, and features. What else does Unraid's safe mode do besides disabling plugins?
-
The Web GUI does load though, it loads and will work just fine for several hours, and then it'll stop for a few hours, and then it comes back again. Edit: Though I suppose you may be suggesting safe-mode to determine whether or not the WEB Gui will stop working as it is periodically? Update: I'm currently running the system in safe-mode, I'll leave it in safe mode for a day or two to monitor it for further issues. I'm also setting up a syslog server now to help with monitoring as extra wear on the flash drive doesn't sound like a good idea.
-
I've attached a screenshot of the issue, as well as my diagnostics. (Please let me know if there was any sensitive information I should've redacted) I've had a few unclean shutdowns lately as a result of my server completely locking up. For months now I've been dealing with my Web GUI not fully loading, after a few hours it typically would come back up and I could access it without needing to make any changes. It seemed random when it would occur, though as I've been doing some troubleshooting I've noticed messages in the syslog like this one. crond[1863]: exit status 255 from user root php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 I've recently gone through and deleted several shares as I've been following the TRaSH Guides to optimize my setup. Though this does not appear to have affected my issue one way or the other I just wanted to mention it in-case it may be relevant. Fix Common Problems has not reported anything since I corrected the recent issues. I switched from macvlan to ipvlan but my issue was present before and after that change. Final thing to note, when the Web GUI would stop loading completely I could still access all of my shares, my dockers, I could access the terminal both from the shortcut in the Web GUI and via SSH.
-
Thanks, the issue was listed in the patch notes and resolved with the newest version of Unraid.
-
I'm currently trying to troubleshoot an issue I have with the WEB GUI not completely loading. Unraid loads up, shares, dockers, and VMs all work correctly. Researching this issue has been difficult because the vast majority of stuff I find is about the WEB GUI not loading at all. I found the attached thread, but unfortunately the issue appears to be different (though this user conveniently forgot to state what solved the issue). I've verified I can write to the USB (unlike the issue in that thread), I've ran chkdsk on the drive and no errors were found, and I've tried several different USB ports (including buying a USB 2.0 Adapter since my board didn't have any USB 2.0 ports). The drive itself appears to be as it should, and I've pulled a backup of the drive directly but I'm unable to access the WEB GUI to perform the Flash Backup present to try a new drive (I have plenty to test) Definitely could use some more advice, as was pointed out in the thread I linked this is typically a flash drive issue, but I'm not sure what to check next. Syslog.txt Pastebin Password: 4NZChcv0Pw https://pastebin.com/8gEQLzic
-
After repairing the file system on Disk16 as suggested in the thread below the issue with Disk14 showing up shared in Disks is now gone. It would appear that the issue with Disk14 was directly related to the corrupted file system on Disk16. I do have a question about this. I recently had an Nvidia GPU that I had passed through to Plex and I was using it for hardware transcoding. I have since removed the card. I deleted the entries to the card in the docker setting for my Plex container. Could these issues be linked to something else I forgot to remove? I know I've still got the monitoring on my dashboard though I don't recall how to remove that. I'm sure I missed something else I was supposed to remove since I've taken the GPU out. I also removed an Intel Quad NIC I had installed perhaps that's related?
-
The cabling has not been disturbed. I can reproduce this issue repeatedly. I reboot the server without ever touching it, drives, or any cables. The server is fine and disk16 is emulated exactly as I expect it should be. After 3 hours approximately disk16 is still emulated but the contents of it have disappeared. When checking via the GUI or Krusader and going to /mnt Disk16 is not readable. I can simply reboot and it will continue working again for 3 hrs.


