




patrickstigler
Members
-
Joined
-
Last visited
Everything posted by patrickstigler
-
only broken sectors ... I justed wiped the disk, and recovered from the backup. Took a while, but it seems to work.
-
I ran Memtest, the whole weekend, last week :-D I got 2 broken modules. So the other ones, currently working fine - at leased I'd say so. I tried to scrub it. But there is one Uncorrectable error. So what to do now? UUID: 53b61841-b900-45f6-a9b6-7446d79b46bc Scrub started: Mon Apr 1 16:58:22 2024 Status: aborted Duration: 0:07:20 Total to scrub: 354.71GiB Rate: 795.44MiB/s Error summary: csum=1 Corrected: 0 Uncorrectable: 1 Unverified: 0
-
Welcome :-D Unfortunately I still have some trouble, while I want to convert back to singe drive. root@Server:~# btrfs balance start -f -dconvert=single -mconvert=single /mnt/cache ERROR: error during balancing '/mnt/cache': Input/output error There may be more info in syslog - try dmesg | tail root@Server:~# dmesg | tail [276079.589839] BTRFS info (device nvme0n1p1): relocating block group 4693758574592 flags system|dup [276079.611808] BTRFS info (device nvme0n1p1): found 3 extents, stage: move data extents [276079.624923] BTRFS info (device nvme0n1p1): relocating block group 4692684832768 flags metadata|dup [276084.175103] BTRFS info (device nvme0n1p1): found 25823 extents, stage: move data extents [276086.154762] BTRFS info (device nvme0n1p1): relocating block group 1636480057344 flags data|raid1 [276086.348070] BTRFS warning (device nvme0n1p1): csum failed root -9 ino 922 off 130379776 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 [276086.348083] BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 807, gen 0 [276086.357072] BTRFS warning (device nvme0n1p1): csum failed root -9 ino 922 off 130379776 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 [276086.357079] BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 808, gen 0 [276086.604873] BTRFS info (device nvme0n1p1): balance: ended with status: -5
-
Thank you so much - again. So enjoy the beer ;-D
-
Label: none uuid: 53b61841-b900-45f6-a9b6-7446d79b46bc Total devices 2 FS bytes used 282.78GiB devid 1 size 465.76GiB used 14.00GiB path /dev/nvme0n1p1 devid 2 size 931.51GiB used 290.06GiB path /dev/nvme1n1p1 looks better I guess?!
-
Created a new DOS disklabel with disk identifier 0x8744012d. Created a new partition 1 of type 'Linux' and of size 931.5 GiB. Partition #1 contains a btrfs signature. Do you want to remove the signature? [Y]es/[N]o:
-
warning, device 2 is missing warning, device 2 is missing ERROR: cannot read chunk root Label: none uuid: 53b61841-b900-45f6-a9b6-7446d79b46bc Total devices 2 FS bytes used 282.78GiB devid 1 size 465.76GiB used 14.00GiB path /dev/nvme0n1p1 *** Some devices missing
-
Ok, wrong order :-( Unfortunately not

-
Hi, I tried to remove the 2nd SSD of my cachepool. It used to be a raid1 - since I wanted to remove one disk, I converted it back to single. Then I removed the 2nd SSD from the config (new config). But I guess I missed a step. Now I can only wipe the data - which I want to avoid. So how do I either finish the conversion or restore it back? btrfs-select-super -s 1 /dev/nvme0n1p1 warning, device 2 is missing warning, device 2 is missing ERROR: cannot read chunk root ERROR: open ctree failed btrfs-select-super -s 1 /dev/nvme1n1 No valid Btrfs found on /dev/nvme1n1 ERROR: open ctree failed
-
No, not yet. But really good hint. Thanks. I started it. Thanks :-D hope the system will be stable now - I keep the thread open for a few days. But it seems that the RAM was the problem. Thank you so much, for the support.
-
For 3 Days stable, but Mar 19 11:13:39 Server kernel: PMS LoudnessCmd[16217]: segfault at 0 ip 000014ce38ac7090 sp 000014ce335d40b8 error 4 in libswresample.so.4[14ce38abf000+18000] likely on CPU 14 (core 6, socket 0) and Mar 19 12:00:02 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 318, gen 0 Mar 19 12:00:02 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 19 12:00:02 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 308, gen 0 Mar 19 12:00:02 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 19 12:00:02 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 319, gen 0 Mar 19 12:00:02 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Maybe the CPU got problems ... well. I will let it run for a while. We will see.
-
After a few hours of testing, and swapping the modules around, it seems that one of the Crucial Ballistix BL2K8G32C16U4B 3200 MHz modules died. It was 24/7 online since 28.11.21 - I guess not a server grade RAM module. Well, the test for the last module is running. And I will also check if that is only in that slot. But thank you for your help - I keep you updated. After another 20ish hours, I must say the Crucial ones are working fine. But the kingston ones are gone. So removed the kingston ram's, and till now it's working. Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 201, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 212, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 202, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 213, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 203, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 214, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 204, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 215, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 205, gen 0 Mar 16 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 16 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 216, gen 0 I have a few errors on one of the cache SSD's, but I assume that one is about to die. about 70% health ..
-
Good guess - I guess :-D Faild after 30min But how do I know which module is broken? edit: So ... does that mean 4 modules 8GB each, my 3rd module is broken? Or do I need to check them separately?
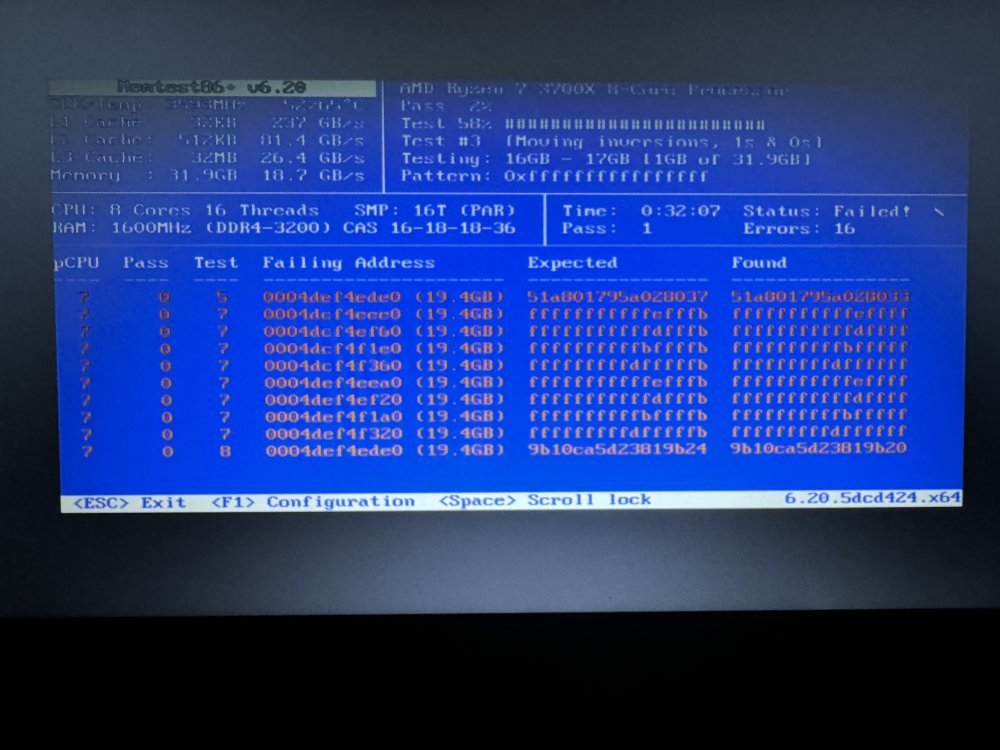
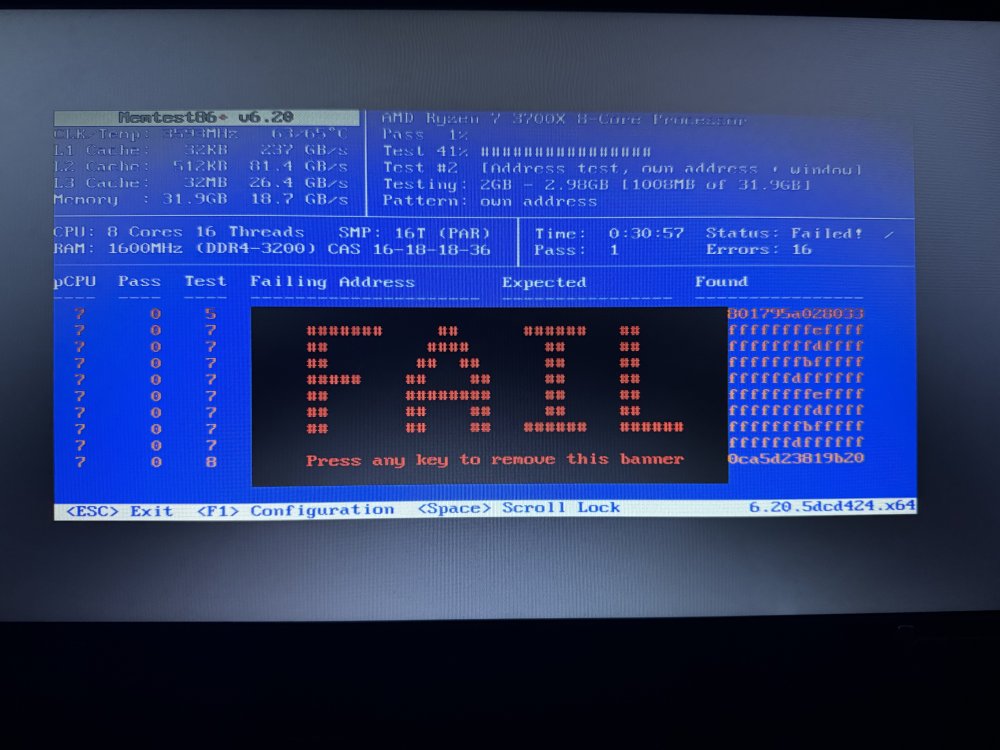
-
Something is wrong.... Mar 13 19:54:39 Server smbd[25669]: INTERNAL ERROR: assert failed: (fh->fd == -1) || (fh->fd == AT_FDCWD) in pid 25669 (4.17.12) Mar 13 19:54:39 Server smbd[25669]: [2024/03/13 19:54:39.999494, 0] ../../lib/util/fault.c:178(smb_panic_log) Mar 13 19:54:39 Server smbd[25669]: If you are running a recent Samba version, and if you think this problem is not yet fixed in the latest versions, please consider reporting this bug, see https://wiki.samba.org/index.php/Bug_Reporting Mar 13 19:54:39 Server smbd[25669]: [2024/03/13 19:54:39.999507, 0] ../../lib/util/fault.c:183(smb_panic_log) Mar 13 19:54:39 Server smbd[25669]: =============================================================== Mar 13 19:54:39 Server smbd[25669]: [2024/03/13 19:54:39.999525, 0] ../../lib/util/fault.c:184(smb_panic_log) Mar 13 19:54:39 Server smbd[25669]: PANIC (pid 25669): assert failed: (fh->fd == -1) || (fh->fd == AT_FDCWD) in 4.17.12 Mar 13 19:54:39 Server smbd[25669]: [2024/03/13 19:54:39.999873, 0] ../../lib/util/fault.c:292(log_stack_trace) Mar 13 19:54:39 Server smbd[25669]: BACKTRACE: 27 stack frames: Mar 13 19:54:39 Server smbd[25669]: #0 /usr/lib64/libgenrand-samba4.so(log_stack_trace+0x2e) [0x14b30c6e064e] Mar 13 19:54:39 Server smbd[25669]: #1 /usr/lib64/libgenrand-samba4.so(smb_panic+0x9) [0x14b30c6e08a9] Mar 13 19:54:39 Server smbd[25669]: #2 /usr/lib64/libsmbd-base-samba4.so(+0x4d0fb) [0x14b30cac20fb] Mar 13 19:54:39 Server smbd[25669]: #3 /usr/lib64/libtalloc.so.2(+0x44df) [0x14b30c68f4df] Mar 13 19:54:39 Server smbd[25669]: #4 /usr/lib64/libsmbd-base-samba4.so(file_free+0xd6) [0x14b30cacf266] Mar 13 19:54:39 Server smbd[25669]: #5 /usr/lib64/libsmbd-base-samba4.so(+0xc0781) [0x14b30cb35781] Mar 13 19:54:39 Server smbd[25669]: #6 /usr/lib64/libsmbd-base-samba4.so(smbd_smb2_request_process_close+0x211) [0x14b30cb35f01] Mar 13 19:54:39 Server smbd[25669]: #7 /usr/lib64/libsmbd-base-samba4.so(smbd_smb2_request_dispatch+0xdfa) [0x14b30cb29bfa] Mar 13 19:54:39 Server smbd[25669]: #8 /usr/lib64/libsmbd-base-samba4.so(+0xb5bc1) [0x14b30cb2abc1] Mar 13 19:54:39 Server smbd[25669]: #9 /usr/lib64/libtevent.so.0(tevent_common_invoke_fd_handler+0x91) [0x14b30c6a28c1] Mar 13 19:54:39 Server smbd[25669]: #10 /usr/lib64/libtevent.so.0(+0xee07) [0x14b30c6a8e07] Mar 13 19:54:39 Server smbd[25669]: #11 /usr/lib64/libtevent.so.0(+0xcef7) [0x14b30c6a6ef7] Mar 13 19:54:39 Server smbd[25669]: #12 /usr/lib64/libtevent.so.0(_tevent_loop_once+0x91) [0x14b30c6a1ba1] Mar 13 19:54:39 Server smbd[25669]: #13 /usr/lib64/libtevent.so.0(tevent_common_loop_wait+0x1b) [0x14b30c6a1e7b] Mar 13 19:54:39 Server smbd[25669]: #14 /usr/lib64/libtevent.so.0(+0xce97) [0x14b30c6a6e97] Mar 13 19:54:39 Server smbd[25669]: #15 /usr/lib64/libsmbd-base-samba4.so(smbd_process+0x817) [0x14b30cb18be7] Mar 13 19:54:39 Server smbd[25669]: #16 /usr/sbin/smbd(+0xb090) [0x55de02472090] Mar 13 19:54:39 Server smbd[25669]: #17 /usr/lib64/libtevent.so.0(tevent_common_invoke_fd_handler+0x91) [0x14b30c6a28c1] Mar 13 19:54:39 Server smbd[25669]: #18 /usr/lib64/libtevent.so.0(+0xee07) [0x14b30c6a8e07] Mar 13 19:54:39 Server smbd[25669]: #19 /usr/lib64/libtevent.so.0(+0xcef7) [0x14b30c6a6ef7] Mar 13 19:54:39 Server smbd[25669]: #20 /usr/lib64/libtevent.so.0(_tevent_loop_once+0x91) [0x14b30c6a1ba1] Mar 13 19:54:39 Server smbd[25669]: #21 /usr/lib64/libtevent.so.0(tevent_common_loop_wait+0x1b) [0x14b30c6a1e7b] Mar 13 19:54:39 Server smbd[25669]: #22 /usr/lib64/libtevent.so.0(+0xce97) [0x14b30c6a6e97] Mar 13 19:54:40 Server smbd[25669]: #23 /usr/sbin/smbd(main+0x1489) [0x55de0246f259] Mar 13 19:54:40 Server smbd[25669]: #24 /lib64/libc.so.6(+0x236b7) [0x14b30c4a96b7] Mar 13 19:54:40 Server smbd[25669]: #25 /lib64/libc.so.6(__libc_start_main+0x85) [0x14b30c4a9775] Mar 13 19:54:40 Server smbd[25669]: #26 /usr/sbin/smbd(_start+0x21) [0x55de0246fb31] Mar 13 19:54:40 Server smbd[25669]: [2024/03/13 19:54:40.000043, 0] ../../source3/lib/dumpcore.c:315(dump_core) Mar 13 19:54:40 Server smbd[25669]: dumping core in /var/log/samba/cores/smbd Mar 13 19:54:40 Server smbd[25669]: Mar 13 19:58:50 Server emhttpd: read SMART /dev/sdh Mar 13 19:59:40 Server emhttpd: spinning down /dev/sdd
-
Mar 13 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 176, gen 0 Mar 13 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 13 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 165, gen 0 Mar 13 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 13 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 177, gen 0 Mar 13 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 13 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 166, gen 0 Mar 13 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 2 Mar 13 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 0, flush 0, corrupt 178, gen 0 Mar 13 18:00:01 Server kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 4711988 off 264597504 csum 0x3019a12b expected csum 0x3ed50501 mirror 1 Mar 13 18:00:01 Server kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 167, gen 0 I haven't rebooted to safe mode yet, should I do so? But it seems, that my SSD / the lanes to my SSD have some issue ?! (currently 207 GB free on the cache pool)
-
that worked - I guess. but the server just froze, I had to reset it. So I guess no log... I will enable the USB log mirroring for now. *update* Now the server behaves like it got ssd / whatever problems. It won't show my drives - and also the webinterface is slow / will not load every content. The web based logviewer is empty right now.

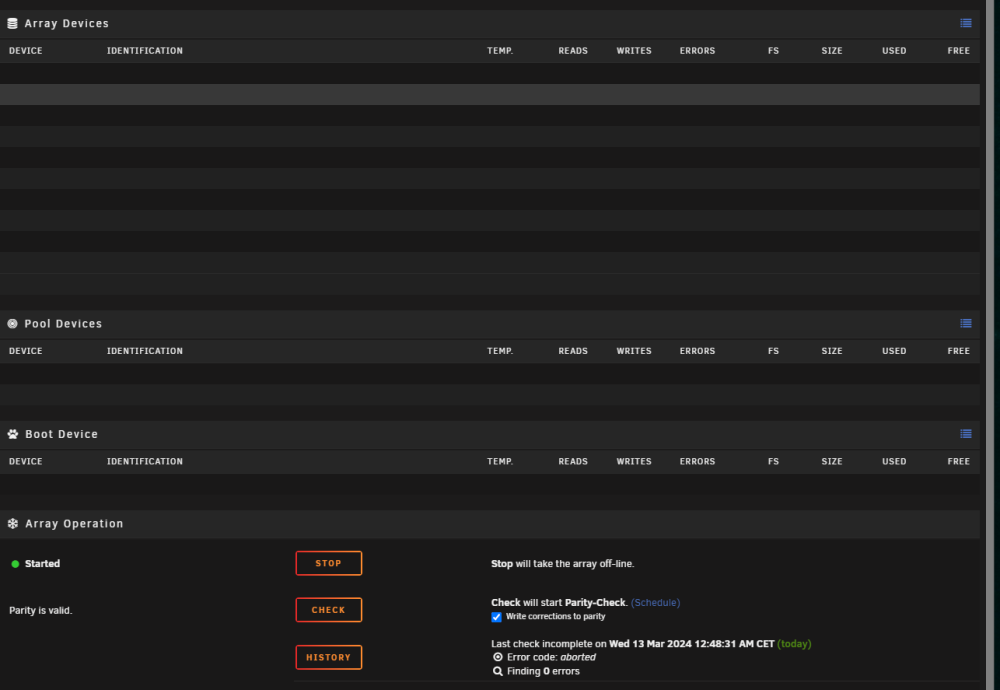
-
So I guess I would prefer raid one, since I have the disks anyway. So do I need to change the profile with "new config" or can I do it with btrfs?
-
In the meantime, the mover moved the data over. But this setup only exists because I thought I had a SSD. So I would remove one one the drives from the cache. I am not sure if I got, what you mean with dual data profiles?! My guess is, you mean, that the new files will be created on the ssd, and moved over using "mover" every X hours?! Isn't there an event like "drive full - start mover"? So how should I deal with that? The idea behind my setup is energy saving. I only need to spinup my drives every 6h (mover setting). But I haven't thought about filling the cache disc before the cronjob starts...
-
@JorgeB so it seems, it took a while - but it happed again. Mar 5 20:31:27 Server kernel: loop: Write error at byte offset 30351020032, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 59279328 op 0x1:(WRITE) flags 0x1800 phys_seg 4 prio class 2 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30082580480, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 58755040 op 0x1:(WRITE) flags 0x1800 phys_seg 4 prio class 2 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 1, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 2, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30574559232, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 59715936 op 0x1:(WRITE) flags 0x1800 phys_seg 4 prio class 2 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30306123776, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 59191648 op 0x1:(WRITE) flags 0x1800 phys_seg 4 prio class 2 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 3, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 4, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30410817536, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 59396128 op 0x1:(WRITE) flags 0x1800 phys_seg 23 prio class 2 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30142382080, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 58871840 op 0x1:(WRITE) flags 0x1800 phys_seg 23 prio class 2 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 5, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 6, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30410653696, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 59395808 op 0x1:(WRITE) flags 0x1800 phys_seg 32 prio class 2 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30142218240, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 58871520 op 0x1:(WRITE) flags 0x1800 phys_seg 32 prio class 2 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 7, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 8, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30377951232, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 59331936 op 0x1:(WRITE) flags 0x1800 phys_seg 80 prio class 2 Mar 5 20:31:28 Server kernel: loop: Write error at byte offset 30109515776, length 4096. Mar 5 20:31:28 Server kernel: I/O error, dev loop2, sector 58807648 op 0x1:(WRITE) flags 0x1800 phys_seg 80 prio class 2 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 9, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 10, rd 0, flush 0, corrupt 0, gen 0 Mar 5 20:31:28 Server kernel: BTRFS: error (device loop2) in btrfs_commit_transaction:2494: errno=-5 IO failure (Error while writing out transaction) Mar 5 20:31:28 Server kernel: BTRFS info (device loop2: state E): forced readonly Mar 5 20:31:28 Server kernel: BTRFS warning (device loop2: state E): Skipping commit of aborted transaction. Mar 5 20:31:28 Server kernel: BTRFS: error (device loop2: state EA) in cleanup_transaction:1992: errno=-5 IO failure Mar 5 20:31:31 Server kernel: docker0: port 3(vethc3d2d62) entered disabled state Mar 5 20:31:31 Server kernel: docker0: port 2(veth3acfc83) entered disabled state Mar 5 20:31:31 Server kernel: veth517a158: renamed from eth0 Mar 5 20:31:31 Server kernel: vethfaf214b: renamed from eth0 Mar 5 20:31:34 Server kernel: lo_write_bvec: 18 callbacks suppressed Mar 5 20:31:34 Server kernel: loop: Write error at byte offset 6943166464, length 4096. server-diagnostics-20240305-2234.zip
-
sorry for the late answer, meanwhile the server is crashing more or less every 2nd day. I will try that and let you know. Thanks for your support.
-
Hi there, I had a SSD (cache) problem a few days ago... maybe still have. I swapped the SSD. But still the system is instable. Any Idea's. I swapped the cache SSD, moved the systemdata from cache to HDD, and back to the new SSD. Started my containers in order and waited for errors.... removed the most plugins shutdown the VM's removed the CPU pinning removed the wannabe cache / temp SSD from unassigned devices server-diagnostics-20240211-1612.zip
-
fixed it
-
Hi there, I had a few random shutdown's / freezes die last weeks / months. Afterwards the parity check was always running. I thought it was due to the unclean shutdown - maybe it wasn't. So today my server was down again... but this time the array won't start because my appdata / system .. is on the cache ssd. I think the sdd is not completely dead, since I saw the files in the file browser before I restarted the machine - but they might been only the cached filenames .. Anyhow, I want to recover my data from the disc since I think the data is still on it. Feb 1 19:52:56 Server kernel: nvme1n1: p1 Feb 1 19:52:56 Server kernel: BTRFS: device fsid 839a38a5-9dac-4aa0-8708-10a624404a44 devid 1 transid 3826201 /dev/nvme1n1p1 scanned by udevd (990) Feb 1 19:53:37 Server emhttpd: Samsung_SSD_980_1TB_S649NF1R516194R (nvme1n1) 512 1953525168 Feb 1 19:53:37 Server emhttpd: import 30 cache device: (nvme1n1) Samsung_SSD_980_1TB_S649NF1R516194R Feb 1 19:53:37 Server emhttpd: read SMART /dev/nvme1n1 Feb 1 19:53:47 Server emhttpd: shcmd (64): mount -t btrfs -o noatime,space_cache=v2 /dev/nvme1n1p1 /mnt/cache Feb 1 19:53:47 Server kernel: BTRFS info (device nvme1n1p1): using crc32c (crc32c-intel) checksum algorithm Feb 1 19:53:47 Server kernel: BTRFS info (device nvme1n1p1): using free space tree Feb 1 19:53:47 Server kernel: BTRFS info (device nvme1n1p1): enabling ssd optimizations Feb 1 19:53:47 Server kernel: BTRFS info (device nvme1n1p1): start tree-log replay Feb 1 19:53:48 Server kernel: BTRFS info (device nvme1n1p1): leaf 2059519705088 gen 3826202 total ptrs 267 free space 806 owner 2 Feb 1 19:53:48 Server kernel: BTRFS error (device nvme1n1p1): unable to find ref byte nr 3843562323968 parent 0 root 7 owner 0 offset 0 Feb 1 19:53:48 Server kernel: BTRFS: error (device nvme1n1p1: state A) in __btrfs_free_extent:3072: errno=-2 No such entry Feb 1 19:53:48 Server kernel: BTRFS error (device nvme1n1p1: state EA): failed to run delayed ref for logical 3843562323968 num_bytes 16384 type 176 action 2 ref_mod 1: -2 Feb 1 19:53:48 Server kernel: BTRFS: error (device nvme1n1p1: state EA) in btrfs_run_delayed_refs:2149: errno=-2 No such entry Feb 1 19:53:48 Server kernel: BTRFS: error (device nvme1n1p1: state EA) in btrfs_replay_log:2417: errno=-2 No such entry (Failed to recover log tree) Feb 1 19:53:48 Server kernel: BTRFS error (device nvme1n1p1: state EA): open_ctree failed Feb 1 20:03:05 Server kernel: nvme1n1: p1 Feb 1 20:03:05 Server kernel: BTRFS: device fsid 839a38a5-9dac-4aa0-8708-10a624404a44 devid 1 transid 3826201 /dev/nvme1n1p1 scanned by udevd (11842) Feb 1 20:33:07 Server emhttpd: spinning down /dev/nvme1n1 Feb 1 20:33:07 Server emhttpd: sdspin /dev/nvme1n1 down: 25 Is it just corrupted ? Can I trust this ssd again? Should / Do I need to buy another one? Thanks for your help.
-
Ok, looks good. Thanks for the help
-
But somehow I can't use it, can't remove the 2nd parity. *EDIT* I guess I have to use the "New Config" tool to get it to remove the Parity 2. Am I right? Or is there another way?







