StephenCND
Members
-
Joined
-
Last visited
-
I did that about 6 months ago for what seems to be the same problem and again maybe 1 year before that. Are USB keys that prone to going bad? I've ordered a few USB drives of a different make (The ones I used before were the same make and model), just to rule out the possibility that I had a bad batch before. The latest update is that I cannot get in at all. The command line says something to the effect of starting OS, but the cursor just blinks and nothing happens. Nothing in the diagnostics that would point to something else? Also, does anyone know how many times I can swap out my license to a new USB key?
-
Checked the USB, initially it said there might be a problem when I plugged it into my pc, but after I let it scan it, nothing was found wrong. (I re-plugged it into the PC a bit later, and the same story.. issue, no issue. Also tried other USB ports, same issue.
-
I've been having issues getting Unraid to boot lately. I finally got it to boot in safe mode however. Accessed it from another computer on my home network. While in safe mode, I have an error msg at the top of page saying "Your flash drive is corrupt or off-line", and it suggest I post my diagnostic file ... which I have done .. This is not the first time I have had this issue. Previously, I ended up changing and registering a new usb device . Not 100% sure this is the issue again, and would rather see if the diagnostics point to something else. Any assistance would be appreciated. Ps., if this is of any help, I did notice on boot up, the boot process will hang with the following approximate message: "waiting up to 30 seconds for device with label UNRAID to come online..." tower-diagnostics-20240825-1937.zip
-
StephenCND changed their profile photo
-
Hello everyone. I am having an issue with opening the WebUI for Binhex-Plex. When I do attempt, I get the following message from from the resulting web page. "This page isn’t working 192.168.40.18 didn’t send any data." The ports and network configuration seems to be ok. Below is a capture of the docker's configurations. Everything seems to be in order. Anyone have any suggestions? Below is Plex Docker Log file.: 2024-03-15 10:50:59.996091 [info] Host is running unRAID 2024-03-15 10:51:00.032267 [info] System information Linux NasTerminal1 6.1.74-Unraid #1 SMP PREEMPT_DYNAMIC Fri Feb 2 11:06:32 PST 2024 x86_64 GNU/Linux 2024-03-15 10:51:00.072639 [info] PUID defined as '99' 2024-03-15 10:51:00.155144 [info] PGID defined as '100' 2024-03-15 10:51:00.222610 [info] UMASK defined as '000' 2024-03-15 10:51:00.267529 [info] Permissions already set for '/config' 2024-03-15 10:51:00.320554 [info] Deleting files in /tmp (non recursive)... 2024-03-15 10:51:00.377697 [info] TRANS_DIR defined as '/config/transcode' 2024-03-15 10:51:00.429170 [info] Starting Supervisor... 2024-03-15 10:51:00,752 INFO Included extra file "/etc/supervisor/conf.d/plexmediaserver.conf" during parsing 2024-03-15 10:51:00,752 INFO Set uid to user 0 succeeded 2024-03-15 10:51:00,758 INFO supervisord started with pid 7 2024-03-15 10:51:01,761 INFO spawned: 'plexmediaserver' with pid 52 2024-03-15 10:51:01,762 INFO reaped unknown pid 8 (exit status 0) 2024-03-15 10:51:01,816 DEBG 'plexmediaserver' stderr output: Plex Media Server is already running. Will not start... 2024-03-15 10:51:01,823 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22658978613968 for <Subprocess at 22658980888080 with name plexmediaserver in state STARTING> (stdout)> 2024-03-15 10:51:01,823 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 22658980677008 for <Subprocess at 22658980888080 with name plexmediaserver in state STARTING> (stderr)> 2024-03-15 10:51:01,824 WARN exited: plexmediaserver (exit status 1; not expected) 2024-03-15 10:51:01,824 DEBG received SIGCHLD indicating a child quit 2024-03-15 10:51:02,827 INFO spawned: 'plexmediaserver' with pid 58 2024-03-15 10:51:03,828 INFO success: plexmediaserver entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2024-03-15 10:51:16,235 DEBG 'plexmediaserver' stdout output: Critical: libusb_init failed

-
Thanks again JorgeB ! Much appreciated.
-
Got the following: "Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata sb_ifree 160, counted 108 sb_fdblocks 729008010, counted 730399085 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 imap claims a free inode 2238793491 is in use, correcting imap and clearing inode cleared inode 2238793491 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 entry "Backup_Error-24-09-2023_23-26-31.log" at block 0 offset 1152 in directory inode 2147483887 references free inode 2238793491 clearing inode number in entry at offset 1152... - agno = 3 clearing reflink flag on inodes when possible Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... bad hash table for directory inode 2147483887 (no data entry): rebuilding rebuilding directory inode 2147483887 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (1:288358) is ahead of log (1:2). Format log to cycle 4. done" Rebooted out of maintenance mode and drive seems to be up and running. No errors. This issue possibly due to a bad sata cable causing corruption?
-
Got the following: " Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this." Do I proceed with the instructions or do you advise another course of action?
-
Been having issues with this drive lately. Initially there seemed to be a problem with it, but I swapped the drive to a new Sata cable and that fixed that. Now it seems the system doesn't recognize the drive (see photo). I ran "Fix Common Problems" but nothing came up. I've attached a Diag file if anyone could be of assistance please. nasterminal1-diagnostics-20231011-0914.zip

-
How would I go about stopping this spamming, other than disconnecting the UPS?
-
That would make sense. I do have a UPS attached to the server. But then again, this particular UPS been there for over 3 months now . Never got this error message before.
-
Upon rebooting, the system shows no errors. I've included a Diag. regardless. So, you say a USB device is "spamming" ? Not sure what that might be.. something I need to fix, and how? nasterminal1-diagnostics-20231003-1255.zip
-
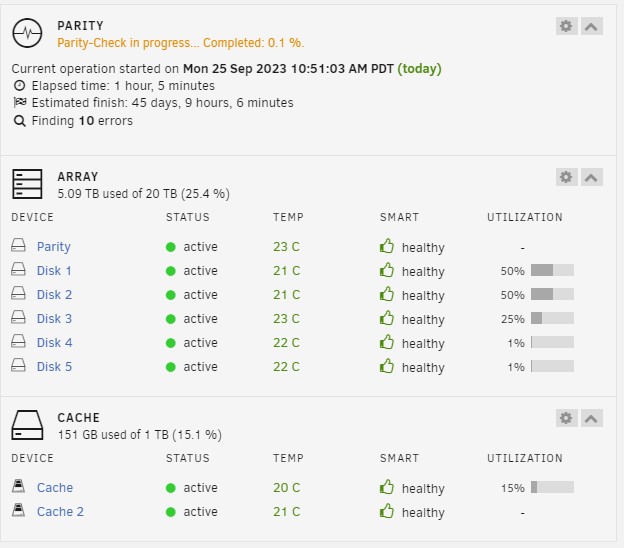
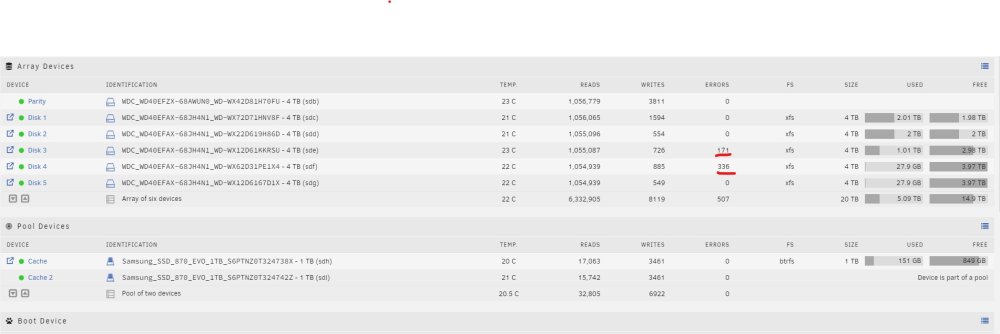
Getting this error msg. in Fix Common Problems, however the drive in question (3) looks fine . Status is green, not close to being full, and there are reads and writes. Note however, I recently had to replace that drives Sata cable due to a separate issue (Parity checks were taking forever). Perhaps that issue corrupted the file system? In any event, I have included a Diag. file and screen cap. Any assistance would be greatly appreciated. nasterminal1-diagnostics-20231003-1109.zip


-
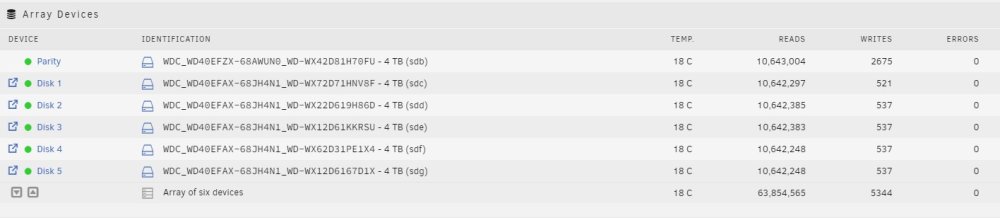
Well, that seems to have done it. ETA is a more reasonable 9 hours, disk error are zero at the moment on both drives. Have included diags as requested just the same. A big thanks JorgeB, Much appreciated. diagnostics3.zip syslog3.zip
-
Was thinking the same thing .. will do and report in.
-
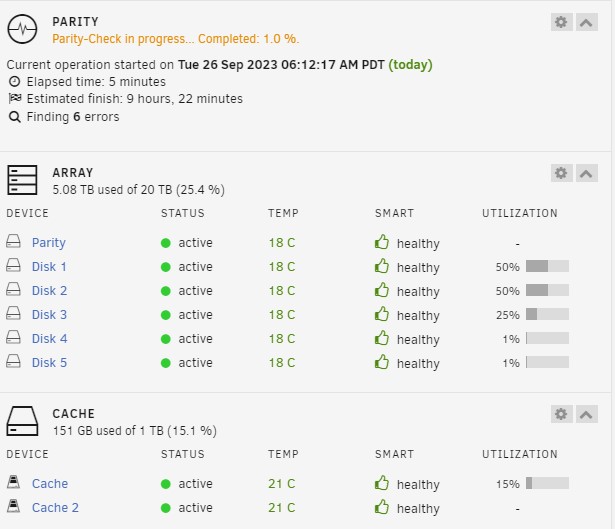
Hello JorgeB, I went into the Bios setting and changed "PCH Sata Control Mode" from "IDE" to "AHCI". Note, there were 2 other settings in the Bios that may or not be relevant to this discussion, but were left as-is (see below). "Onboard IDE Controller" set to "Auto" (other options are ""Enabled" or "Disabled") "Sata Port0-3 Native Mode" set to "Enabled" (other option is "Disabled" I've included 2 screen caps, as well as Diag and Syslog zip files. It's now showing that there are 2 drives with disk errors. Let me know if you require additional information. nasterminal1-diagnostics-20230925-1453.zipnasterminal1-syslog-20230925-1855.zip