




MoherPower
Members
-
Joined
-
Last visited
-
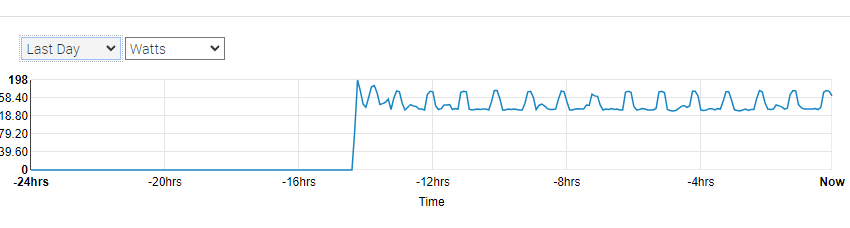
another update. Until yesterday everything was ok. all disks slept like they should. Yesterday i changed hardware configuration (took out 1 processore an RAM) of my Dell and i had to shut down server and take all power plugs out. after start all process of waking up and shuting down disks started again. also i noticed that my disks are making noice just like thay do when they write or read data but in unraid nothing is written ( i chacked in unraid reads / writes and the numbers are not growing) I think i change raid controller and get back after that with new infos. here is power graph from IDRAC. (i wonder why i lost all power usage data from before hardware change ? all changing process toom me 30 min.)
-
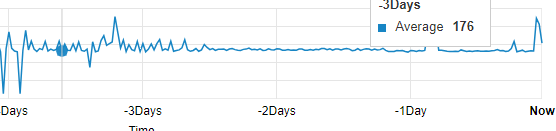
One more strange thing happened today. As i promissed i bought sas cables to change controller but it seems my disks are sleeping from over 2 days. i checked in idrac power graph that shows dell was waking up disks for 1,5 days from migration and than it stopped. I did nothing becouse of work, just turned on server and let it be. do any one knows exacly what those HBA330 controllers do in background. Do they check "smart" or do other tests to disks they consider new? Right now all is working like it should so i have no complains.
-
1) people say that this problem affect only segate sas drives but it is not. i have wd UltraStar (SAS), WD WD20EFRX (SATA), and ST8000NM0045(SATA). it afects them all if they are connected to dell server only. 2) to wake up disks from sleep you need to access them. there is 2 options --in my case -- or unraid started by miracle write something only when it is connected to dell machine or more prabable dell is "doing something" to wake disks up. Maby check smart or do other "checky" things. Also Dell is known from making things hard if you don't use dell hardware. and by the way i have segate exos 7e10 (S/N WREDA0LB if you want to check) branded by DELL with del firmware and you know what it sleeps like a baby. But it shlould not becouse it is segate That is why i can tell with clear conscience it is DELL fault. but i intend to check 2 things. a) put there old hewlett packard h330 card with flashed lsi firmware. if it helps i will know that problem is not Dell server platform but controller. i need to wait for sas cables becouse this controller have diferent connectors. b) flash hba330 with not dell firmware and if disks will stay aslep than we will know it is dell firmare not faulty controller. after that i will get back to you to point definite culprit (wishpering) witch is DELL ofc. i didn't done this thing before so it will take me some time to ask uncle google for help.
-
than how you explain my case? i just move usb stick and disks from one server to another and in non dell server all disk sleep well but in dell server they wake up after a while. i will try to find sas cables to connect my old HBA controller to dell derver and we will see than.
-
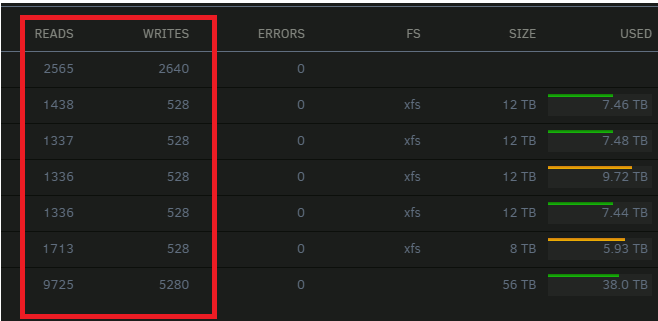
Hi to all. I have to add something to this topc. I got server that i put together by myself. MB MSI, CPU RYZEN 9 5800 and raid controller flashed to hba mode. all my disk no mather sas or sata was spin down and STAY that way until i did somethig to wake them up. All was so perfect that i wondered "what will happen when i buy a real server" and i did --- DELL t640 with HBA330. And now you know what happened and why am i here with you??? my disks spin dow and after 20-30 min they spin up. What i did? i took out usb from my old server and put into my new. no changes just disks swap to new server and usb. so my advice dont waste time for looking if someting is writing to disk or so. IT IS ALL DELL FAULT. i put disks and usb to my old server again and everything works like it shoud. This is becouse of firmware or bios of the DELL that wakes up disks. Nothing in unraid. we should look in dell bios/idrack settings. if any one know how to flash this DELL HBA330 to non dell firmware maby this will really help. I am preatty sure that some DELL "performance" settings or controller firmware wont let disks to sleep for long. one more proof. in unraid i switched disks view from bits per second to read / write number. than put disks to sleep and waited for them to wake up. the number of writes / reads not change but disks ware woken up. This is proof that nothing was trying to read write from/to disks.
-
thank you for answer. i will try zfs and get back in fiew days.
-
Hi everyone. I have problem with my virtual mashine. 2 months ago i switched from my phisical server to virtual mashine. i got 1 TB phisical disk and i converted it to qcow2 dynamic disk. After this conversion qcow2 file was around 250GB. I created virtual mashine in unraid and put my qcow2 file on new 2x nvme disks specialy bought for my VM's and and dockers and formated with btrfs (as far as i know this is only option for disk redundancy). and all was working fast and ok. I'm making backup of this file regulary once in the week. Procedure is simple i shut down VM. than use rsync -ah ..... command to copy file from my nvme disk to array. At the beggining coppy speeds was around 166MB/s almoust constantly (all backup took like 25-30 min). but after this i started to put some files inside VM and my qcow2 file grow up. first 4 backups was rather fast but took me longer and longer every next week. i also expirienced more and more not 166MB/s speeds but 3MB/s !!. Right now after 2 months of usage my qcow2 file have 278GB and my speeds are very slow now. mousty limited to magical 3MB/s and i dont know why. backup take up like 1:20 hours now. average speeds dropped to 50MB/s. i know my disks are good in array and nvme. 0 smart warrnings or errors. I wonder if this is a problem with dynamic qcow2 disk or with nvme formated with btrfs. Can any 1 help what is going on? should i use fixed sixe qcow2 file or try to move vm on xfs disk? i moved appdata, domains, system, and, dockers folders also to thesame nvme cache pool what my qcow2 file is stored. Do i do something wrong here? my VM is windows and it makes alot of writes to swap file. maby i should balance or scrub nvme pool disk more those are the statistics of nvme pool Data, RAID1: total=358.00GiB, used=334.84GiB System, RAID1: total=8.00MiB, used=80.00KiB Metadata, RAID1: total=1.00GiB, used=501.12MiB GlobalReserve, single: total=448.27MiB, used=0.00B btrfs balance status: No balance found on '/mnt/cache' Current usage ratio: 93.5 % --- No Balance required UUID: f1ed6f74-2168-4a95-a1ed-a1a37537a84f no stats available Total to scrub: 670.66GiB Rate: 0.00B/s Error summary: no errors found unraid version is updated to 6.12.6 but this not solved the problem.

-
any one can help me???
-
I want to add to this topic There is strange thig. i have two almoust identical unraid configurations at home. One is older. Started with 6.9.2 and than updated it to 6.10.3 and all my disks spins down and stay down. no problems there The second system is newer and i instaled there 6.10.3 and the weird thing is that some drives go to sleep and some don't. even those not mounted do not want to spin down even when i spin them down manualy they just start up. i dont know if the path of upgrade means something or not. on the third system 6.11.3 that i set up in my work 11 disks wont stay spun down at all. when they is put to sleep manualy thy stay that way for about 10 seconds and start one by one. there is bug for sure. this unraid is new and now empty so no files are opened there. all appdata, system and such are on cache pool. disks are totaly empty.
-
Hi all I wanted to virtualize my phisical PC. So i come up with idea of backuping my whole drive C (1 TB ssd) and than creating virtual mashine in unraid and using recovery.iso to boot up and restore this PC in virtual mashine. Whole process went well and now i have vdisk.img but. when i look to the folder where it is i see root@Skynet:/mnt/user/vm-test/Windows 10# ls -al total 570856136 drwxr-xr-x 1 nobody users 24 Nov 13 12:57 ./ drwxrwxrwx 1 nobody users 49 Nov 14 18:36 ../ -rwxrwxrwx 1 nobody users 1099511627776 Nov 14 02:51 vdisk1.img* it seems that it takes only 570 GB in real but it shows 1TB in filesystem. and when i try to make a copy of it to array problems begins. my HDD that is capable of transfers 140-250 Mb/s when copy this particular file slow down to 5MB/s. copying this file take ages. I thought it is faulty drive so i did another test. I copyied part of this file to another folder using "cp" command and stop copy proces after 100GB. Than i try to copy that second file and sudenly my HDD goes full speed. It seems that problems are only with oryginal file created by VM itself. thesame goes for my nvme drives. they have speeds around 3,5GB/s and when i create img file on them by VM manager and try to copy this file between nvme drives speed drops to 50-90 Mb/s. But when i try to copy already coppied file i go full speed. All VM are stopped while i coppy those files. I dont know what problem is and need your help please.
-
1) insert any nvme disk with partitions 2) use unraid UNASSIGNED DEVICES to delete those partitions. 3) format disk with new partition no matter what xfs,btrfs, ntfs no difference. 4) try to mount newly formated disk (you will be unable to finish this). 5) look at logs and you will se this : Nov 14 07:26:38 Skynet unassigned.devices: Adding partition 'nvme1n1p1'... Nov 14 07:26:38 Skynet unassigned.devices: Mounting partition 'nvme1n1p1' at mountpoint '/mnt/disks/Windows'... Nov 14 07:26:38 Skynet unassigned.devices: Mount drive command: /sbin/mount -t 'ntfs' -o rw,noatime,nodiratime,nodev,nosuid,nls=utf8,umask=000 '/dev/nvme1n1p1' '/mnt/disks/Windows' Nov 14 07:26:38 Skynet ntfs-3g[6819]: Version 2021.8.22 integrated FUSE 27 Nov 14 07:26:38 Skynet ntfs-3g[6819]: Mounted /dev/nvme1n1p1 (Read-Write, label "", NTFS 3.1) Nov 14 07:26:38 Skynet ntfs-3g[6819]: Cmdline options: rw,noatime,nodiratime,nodev,nosuid,nls=utf8,umask=000 Nov 14 07:26:38 Skynet ntfs-3g[6819]: Mount options: nodiratime,nodev,nosuid,nls=utf8,allow_other,nonempty,noatime,rw,default_permissions,fsname=/dev/nvme1n1p1,blkdev,blksize=4096 Nov 14 07:26:38 Skynet ntfs-3g[6819]: Global ownership and permissions enforced, configuration type 1 Nov 14 07:26:38 Skynet unassigned.devices: Successfully mounted 'nvme1n1p1' on '/mnt/disks/Windows'. Nov 14 07:26:59 Skynet unassigned.devices: Removing all partitions from disk '/dev/nvme0n1'. Nov 14 07:27:19 Skynet unassigned.devices: Format device '/dev/nvme0n1'. Nov 14 07:27:19 Skynet unassigned.devices: Device '/dev/nvme0n1' block size: 500118192. Nov 14 07:27:19 Skynet unassigned.devices: Clearing partition table of disk '/dev/nvme0n1'. Nov 14 07:27:19 Skynet unassigned.devices: Clear partition result: 1+0 records in 1+0 records out 2097152 bytes (2.1 MB, 2.0 MiB) copied, 0.0119385 s, 176 MB/s Nov 14 07:27:21 Skynet unassigned.devices: Reloading disk '/dev/nvme0n1' partition table. Nov 14 07:27:21 Skynet unassigned.devices: Reload partition table result: /dev/nvme0n1: re-reading partition table Nov 14 07:27:21 Skynet unassigned.devices: Creating Unraid compatible mbr partition on disk '/dev/nvme0n1'. Nov 14 07:27:21 Skynet kernel: nvme0n1: Nov 14 07:27:21 Skynet kernel: nvme0n1: p1 Nov 14 07:27:21 Skynet kernel: nvme0n1: p1 Nov 14 07:27:21 Skynet unassigned.devices: Create mbr partition table result: write mbr signature done Nov 14 07:27:23 Skynet unassigned.devices: Reloading disk '/dev/nvme0n1' partition table. Nov 14 07:27:23 Skynet kernel: nvme0n1: p1 Nov 14 07:27:23 Skynet unassigned.devices: Reload partition table result: /dev/nvme0n1: re-reading partition table Nov 14 07:27:23 Skynet unassigned.devices: Formatting disk '/dev/nvme0n1' with 'xfs' filesystem. Nov 14 07:27:35 Skynet unassigned.devices: Reloading disk '/dev/nvme0n1' partition table. Nov 14 07:27:35 Skynet kernel: nvme0n1: p1 Nov 14 07:27:35 Skynet unassigned.devices: Reload partition table result: /dev/nvme0n1: re-reading partition table Nov 14 07:27:39 Skynet kernel: nvme0n1: p1 Nov 14 07:27:49 Skynet unassigned.devices: Adding partition 'nvme0n1p1'... Nov 14 07:27:49 Skynet unassigned.devices: Mounting partition 'nvme0n1p1' at mountpoint '/mnt/disks/ESP'... Nov 14 07:27:49 Skynet unassigned.devices: Mount drive command: /sbin/mount -t 'vfat' -o rw,noatime,nodiratime,nodev,nosuid,iocharset=utf8,umask=000 '/dev/nvme0n1p1' '/mnt/disks/ESP' Nov 14 07:27:49 Skynet kernel: FAT-fs (nvme0n1p1): utf8 is not a recommended IO charset for FAT filesystems, filesystem will be case sensitive! Nov 14 07:27:49 Skynet kernel: FAT-fs (nvme0n1p1): bogus number of FAT structure Nov 14 07:27:49 Skynet kernel: FAT-fs (nvme0n1p1): Can't find a valid FAT filesystem Nov 14 07:27:49 Skynet unassigned.devices: Mount of 'nvme0n1p1' failed: 'mount: /mnt/disks/ESP: wrong fs type, bad option, bad superblock on /dev/nvme0n1p1, missing codepage or helper program, or other error. ' Nov 14 07:27:49 Skynet unassigned.devices: Partition 'ESP' cannot be mounted. 6) restart unraid. 7) try to mount again and viola. all is now correct. magicly all bad superblocks and other struff is corrected. Nov 14 07:42:51 Skynet unassigned.devices: Adding partition 'nvme0n1p1'... Nov 14 07:42:51 Skynet unassigned.devices: Mounting partition 'nvme0n1p1' at mountpoint '/mnt/disks/S50ANF2N628803'... Nov 14 07:42:51 Skynet unassigned.devices: Mount drive command: /sbin/mount -t 'xfs' -o rw,noatime,nodiratime,discard '/dev/nvme0n1p1' '/mnt/disks/S50ANF2N628803' Nov 14 07:42:51 Skynet kernel: XFS (nvme0n1p1): Mounting V5 Filesystem Nov 14 07:42:51 Skynet kernel: XFS (nvme0n1p1): Ending clean mount Nov 14 07:42:51 Skynet kernel: xfs filesystem being mounted at /mnt/disks/S50ANF2N628803 supports timestamps until 2038 (0x7fffffff) Nov 14 07:42:51 Skynet unassigned.devices: Successfully mounted 'nvme0n1p1' on '/mnt/disks/S50ANF2N628803'. for me there is one thing very strange. the name of filesystem. first unraid remembered the name of deleted partition "ESP" and after restart unraid tried to mount "S50ANF2N628803" partition. maby this is problem i dont know. but simple restart helps. if there is a problem with partition name than it schould be replicated by 1) unmounting drive 2) changing partition name 3) mounting again and error should apear again.
-
Why unraid to power off needs to spin up all disk in arryay? Why am I asking? This is problem when power fails and i need to shut down unraid running on ups. he needs to spin up all 24 disks and it taks time and POWER from ups. Second question why i need to make parity check when power fails with all array disks spin down? what can happen to data with disks powered off that needs any check?
-
I have problem with ups Power off. I want my unraid to power off itself immediately when main power fails. that is why i set it to Shutdown Mode: Battery Level Battery Runtime Left: Battery Runtime Battery level to initiate shutdown (%): 96 UPS Mode: Standalone Turn off UPS after shutdown: NO Unraid start shutdown 30sec after power failure but it also turns OFF UPS. this leads to parity check and to powering off all my network switches and stuff. It also leaves my UPS in strange state that even after returning main power needs me to push the powerbutton on UPS to start working. This is not happening when my UPS runs ouf of battery. After power returns it just turns on. My ups is PowerWalker VI 850 LCD Can you help me to solve this problem?
-
how old parity disk will update if this disk is supposed to be taken out from unraid? the procedure is as far as i know 1) stop array and take out first parity disk 2) start array and stop after information about parity disk missing 3) assign new parity (precleared/checked) and rebuild parity. so how old parity drive will update since this disk will lay on my desk?. Can i just stop array and assign new parity disk without removing old one from server so the information will be coppied from old to new?
-
The problem in all of those scenarios is this. Unraid server works in company and is used as backup storage for all pc(64) / servers(4). Puting array off for 24h is not acceptable and more over when parity will be rebuild on new disk there will be writes form backup to array too, so my old parity disk will be not valid if anything goes wrong. Is there no other way to copy data from one parity to another without braking parity for a period of time??



