




prymordial
Members
-
Joined
-
Last visited
-
I received a notification from fix common problems that this plugin is no longer in the community apps store. Was there a reason why it was removed?
-
Much appreciated! I'll try clearing my browser cache as well just to be sure I cover all my bases.
-
Hey Masterwishx, I just updated to the latest version of this plug-in and it seems that the settings no longer align with their respective drop down menu. I've tested this in Edge, Firefox, and Chrome and they all are showing the same thing. Additionally, the information windows are covering parts of the configuration items. This may be because I'm on ver 7.0.0 but I wanted to bring this to your attention in case you weren't aware. Thanks again for all the hard work!
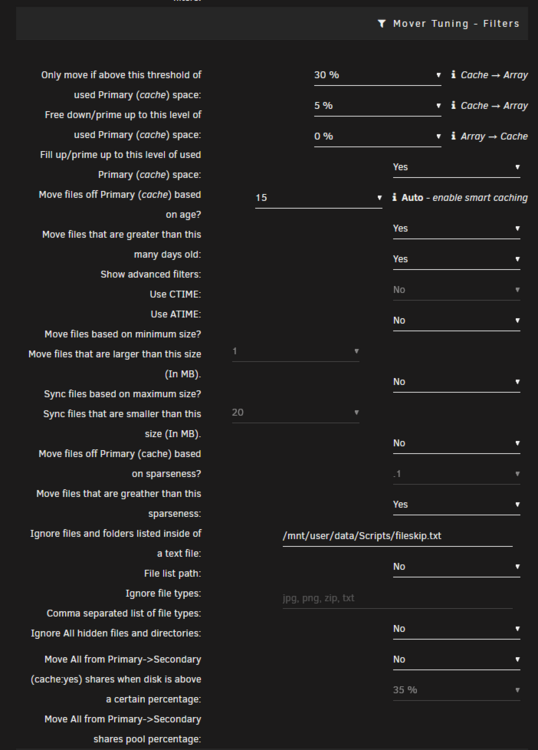
-
Sorry if this has been asked before, but it seems since upgrading to 7.0 and installing the compatible plugin that the mover is leaving empty folders after the move is finished. Would enabling the setting "Clean Empty Folders" fix this new behavior? Thanks! :D
-
Checking in after 1 week - After rolling back to version 6.9.2 (not 6.9.4 like I previously mentioned), my server seems to be much more stable. I'll continue to monitor and plan on adding the two sticks of memory back in over the weekend. I'm hoping this is simply an issue with the kernel and my hardware having some sort of bug.
-
That's been the strangest part about this whole thing. It will be fine for a few weeks and then one day the server is completely inaccessible in one of a few different ways: 1. The server goes completely offline from a software standpoint. Containers are no longer accessible, web UI can't be reached, SSH is DOA, but the server still has power. 2. The web UI goes offline, but the containers are still accessible. 3. qBitTorrent shows as running in the console, but is unreachable. When I try to stop the container using the context menu, it just throws a "server exception." The more I dig into this, the more I think my issue is either A. a piece of hardware is dying (HBA, mobo, CPU, add-in NIC) or B. there is some compatibility issue with my hardware and the current kernel version. There's been a few other posts that mention the same symptoms that I just described with no direct resolution. This is one of the posts that mention trying 6.12: So this is where I'm at currently; I removed 2 sticks of memory and set the XMP config in the BIOS to Auto for everything. I have stopped every docker and disabled every script schedule with the exception of Plex. I'm going to monitor syslog for any other btrfs errors to see if I can narrow down the issue further.
-
Hey @homiek33 - did you ever figure out this issue? I'm running into similar crashes that happen anywhere from a few weeks to a few days.
-
I am not. I went into my BIOS and set the XMP profile to Auto when I posted about some data corruption back in 2022 and set the memory speed to 1866 per AMD's recommendation
-
Hmm ok. So given that the memtest ran without any errors in almost 24 hours, could I be looking at a false negative with this test? I'm just at a loss at trying to figure out what the issue could be at this point. The server was completely stable when I was on 6.9.4 and really only started crashing when I upgraded to 6.11.5.
-
A little early on the 24hr mark, but my memory passed 6 sets of the 10 tests in memtest86+ ver 6.10. Prior to kicking off the tests, I did reseat the 4 modules just to be sure they were properly secured in each slot. What do you think about these btrfs errors binge caused by the mover trying to move files from my cache to array? I had a user script set up to stop my torrent docker at 3:55am each day then the mover is scheduled to move at 4am. I'm wondering if there's an issue with the script failing to stop the docker and the mover then executing on files that are in use by qBitTorrent.
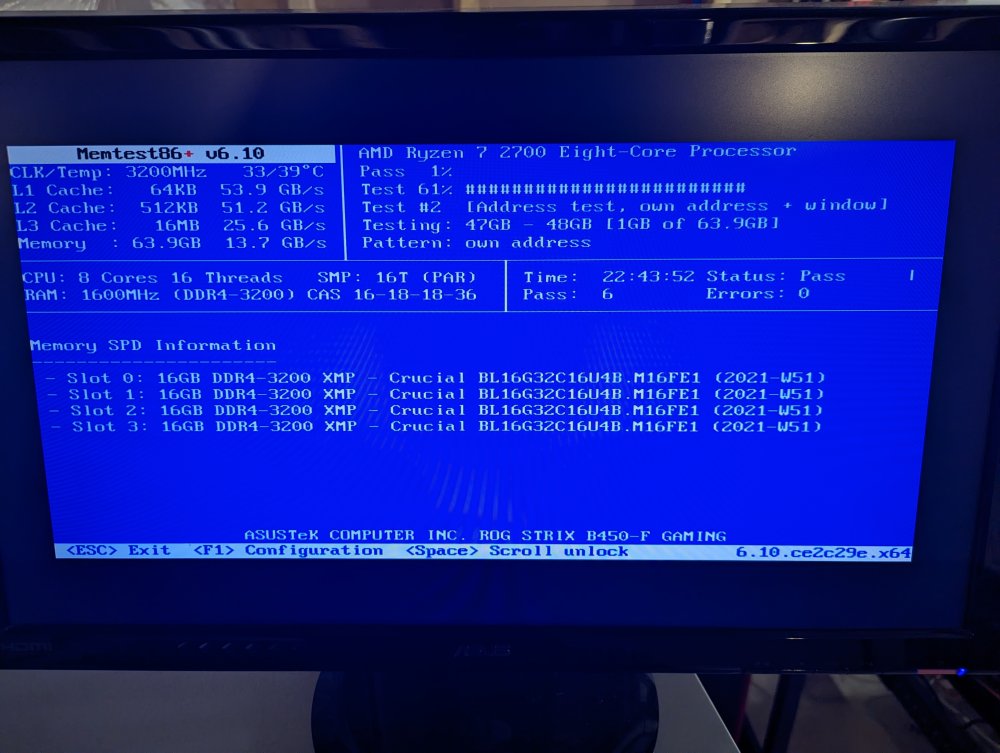
-
Hmm, I wonder if the same issue I was having back in March '22 has reared its ugly head again. I'll fire up memtest and see if anything gets flagged. I'll report back in 24 hours. Thanks trurl!
-
Good morning, I've been having some intermittent stability issues where either my torrent container (both Deluge and qBitTorrent after migrating from Deluge) are unable to be stopped, my server becomes completely unresponsive and no longer shows as being online in my router, or the webUI crashes and the Docker are still available via IP:PORT address. I've recreated the docker.img file to no success, I have disabled C states on my mobo as well. This issue seems to have started after upgrading to ver. 6.11.5 of unRAID. I thought maybe it was related to the LibTorrent 2.X issues that were called out in the Bug forums, but I don't believe that is the case because the the BUG line in my syslog does not match the standard symptoms of that issue. What I always see before a crash in the logs is: Feb 20 23:53:30 Deathstar kernel: BUG: kernel NULL pointer dereference, address: 0000000000000000 Honestly, I'm a bit at a loss right now, haha. I can't seem to pin-point what/why is causing my server to crash like this. Any help would be greatly appreciated syslog_deathstar.log deathstar-diagnostics-20230221-0949.zip
-
Just found the below thread as well. There is a Deluge docker running which I've noticed odd behavior with over the last few weeks. Not wanting to stop/restart. Slow to respond to commands, not starting newly added torrents.
-
Since upgrading to version 6.11.5, my server will randomly become unresponsive. SSH, Web UI, and Dockers all stop responding. I thought it was a C State issue so I disabled Global C States. I've attached the syslog of my server and it shows that a BUG was thrown at 15:24:57 on Jan. 10th. I've made no changes to my server in months outside of disabling C States. I've attached the syslog since I set up remote logging on the 8th. Definitely stumped on this one as I said, I had no crashed when running 6.9.4 but this is the third one since being on 6.11.5 Here is my hardware list as well: Ryzen 2700 Asus B450-F 16x4 64GB of Crucial Ballistix DDR4 3200 MHZ (running at 1866 per AMD recommendation) Dell Intel PRO 1000 VT PCI-E NIC 650W EVGA B3 PSU HBA LSI 9211-8i card Array: 2 14TB WD Reds (one parity, one data) 2 8TB Seagate Barracuda 1 8TB HGST drive 1 8TB Toshiba drive Cache Pool: 1 1TB Samsung 980 NVMe 1 1TB Hynix P31 Gold NVMe unraid.log
-
I'm struggling to upgrade my parity from an 8TB drive to a 14TB drive. I followed the instructions on the Parity Swap Procedure guide but when I got to step 14, I noticed that I did not have a copy button. Not sure what I'm doing wrong here to upgrade my parity drive or if I'm over thinking it. My goal is to drop in the new drive and not lose any of the data on my other 3 disks. Thanks!



