




michielvv
Members
-
Joined
-
Last visited
-
Hi! I actually decided at some point to use "Rebuild-DNDC", which works like a charm. There is one catch where restarting the docker containers behind the VPN went orphan: the dockers behind the VPN mostly have ports explicitly configured. However, I have set Network Type to 'None' on those dockers. That is a combination that will not work (Docker will give you an error). The Unraid GUI seems to silently ignore those port settings when choosing the Network Type 'None' and successfully starts when pressing 'Apply'. Rebuild-DNDC will not and so tries to restart the docker with Network Type 'None' AND port configs. That fails. My solution was to remove the port configs from the dockers behind the VPN, so that Rebuild-DNDC successfully restarts those dockers with valid parameter combinations.
-
Thanks so much! I indeed think there may be some kind of race condition between the VPN connection complete and the rebuilding trigger for the VPN dependent dockers. << would this be a bug? The script works like a charm. I have followed the above instructions, renamed the PASSTHROUGHVPNNAME to the containernetwork named 'gluetunvpn'. It does work a little different from your explanation though: it just checks if the VPN container has been restarted based on uptime and container id change (if it cannot get the uptime it assumes a container restart). If so, then it will restart all containers that rely on the network of the VPN container. Simple and clean solution, nice!
-
anyone?
-
Hi all! Since a long time I have been looking for a solution for the following problem: I have several dockers that I want to have behind a VPN. To that purpose I have a GlueTun VPN docker. The other dockers are using the network of the VPN docker by adding special parameter "--net=container:gluetunvpn". This works like a charm. However, when the GlueTun VPN docker is updated or restarted, (obviously) the network of all depended dockers becomes invalid. After the restarting of the VPN docker, the depended dockers show 'Rebuild ready' but are stuck in that state. The only way that I am aware of to trigger the actual rebuilding of those dockers, is by browsing to the /docker overview in de WebUI. Once I do that, all these dockers start the actual rebuild. If I do not visit that URL, none of the dockers gets rebuild and remain stuck in their 'Rebuild ready' state. As such, part of my system becomes unresponsive as those dockers cannot be reached anymore. Is here any solution to this? Thanks in advance! Regards, Michiel
-
Thanks, noticed indeed in a parallel topic this might be the issue. Fixed it for me!
-
All, I have been using UnRaid to much happiness for some time, super! However, I now run into a problem after i did this: I removed my second parity drive and added that drive as new drive (disk clear, format). Then I invoked a manual move to get my cache drives emptied. After that, i can visit any other GUI part except for the Dashboard section. It tries loading and then at some time gives up and looks like this: If I open other 'tabs' of the gui in a separate tab in parallel, those pages give a gateway timeout 504. When the Dashboard section finally stops loading, i can load the other 'tabs' successfully, no problem. All docker, vms run, syslog reports no errors. A reboot did not fix it unfortunately... Diagnostics are attached! Any idea? Thanks in advance, Michiel nasi-diagnostics-20240306-1724.zip
-
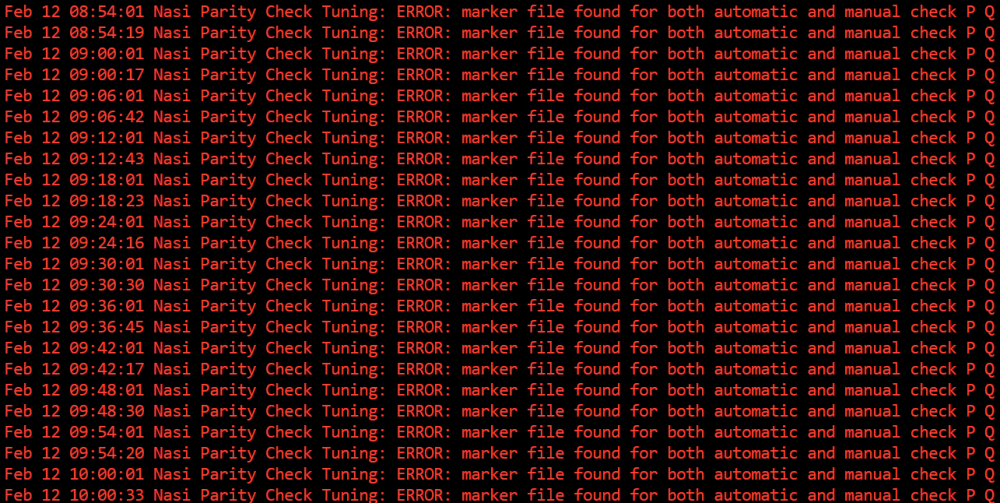
Hi all! After an accidental power outage, Unraid boots and started its parity check. I checked the logs and noted the following: I cannot find any guidance on these errors (I searched at length, though maybe no good enough :)) - should I be concerned about these errors?
-
This worked, thanks! I just tested it by moving /mnt/user/data/test-share to /mnt/user/test-share and indeed all files in this folder scattered over different drives and cache where moved in the background to the destination. Note that apparently SMB will restart, i.e. any SMB connection with the server will be reset.
-
All, I am re-arranging my user shares from: data (< user share) Movies Series [whatever] into: Movies (< user share) Series (< user share) [whatever] (< user share) I have done extensive searching, but failed to find solid advise if this is as simple as mv command in /mnt/user/data to move all subfolders to /mnt/user/ which would *magically* align the (underlying) cache and disks folder structure? Reason to do it this way (instead of making new shares and moving data from the subfolder to the new shares) is that there is a lot of data to move. If I can prevent moving actual data by just changing the folder pointer, it could be done in a second. Maybe I need to manually change each folder structure on the cache and disks as well...? Anyways, I am afraid I somehow will wreck the disk/share framework Unraid is using and lose data, so looking for guidance. What would work? regards, Michiel
-
Solved all of this: bottom line was that i implemented the wrong way of getting dockers to use the vpn docker's network instead of their own: 1. I made a custom network via the command line pointing to the VPN docker 2. in each of the docker's pull down lists I selected this network to use. This causes problems when updating (custom network does not seem to be refreshed with the new docker ID of the VPN docker) and portmapping problems somehow. Instead, I should've done the following: 1. for each docker, set network to 'none' 2. for each docker, add extra parameter "--net=container:[your vpn dockername - only lowercase allowed!!!]" And bingo: updating the vpn dockers refreshes the relying dockers automatically and portmapping is transparently working without errors. super!
-
Thanks again for the help. Restarting of containers is then clear. The only challenge remaining is installing an update, which seems to apply the default template (with port mapping) rather than the one installed (without port mapping). Any clue how to solve that?
-
Thanks for taking the time to debug this one! If i do what you suggest, it does solve the problem of the network restart loop (question b) indeed. The problem i do not solve is question c : how to update the other containers without port mapping (ie. this is what breaks restarting the updated container, it seems)? If i update the container, it will update, but fail to restart (due to the default port mapping). I have to remove the orphaned docker and reinstall the app from the docker templates section. There should be a way to update the container without the default port mapping....?
-
any thoughts?
-
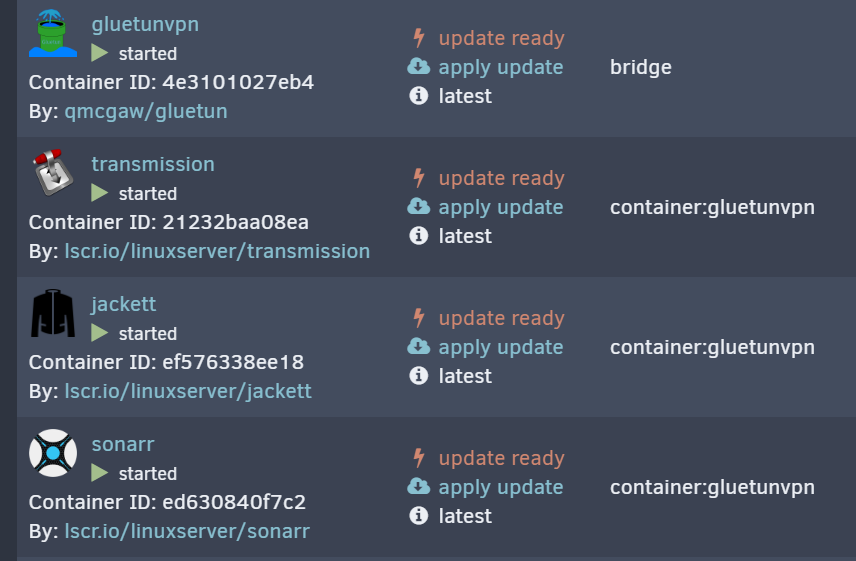
Hi all! First of all: unraid rules. I enjoy using it every day and most 'challenges' I solve myself (and learn more tech as a bonus). Not so this one. I have setup gluetunvpn for a vpn connection. Then, I have configured a couple of containers to use the gluetunvpn network, so that all traffic will only flow through the gluetunvpn connection (ie. through the actual VPN connection). I have two challenges: 1) When i update the gluetunvpn container, the container:gluetunvpn networks used by the other containers become invalid. As a result, those other containers get stuck in a restart loop. I can understand that, as the container ID of gluetunvpn will change (hence, I assume, so does the network reference for each of the containers). 2) When i update any of the other containers that use the container:gluetunvpn they fail to restart, because by default there is a port mapping implemented, meant to be used in bridge/host network mode, but not in the case of container:gluetunvpn it seems. This is part of my setup: Three questions: a) I may not use the right implementation of networks to get what i need? is this the case and if so, what would be the preferred way? b) how to update gluetunvpn without getting the other containers in a restart loop? c) how to update the other containers without port mapping (ie. this is what breaks restarting the updated container, it seems)? Most grateful for your help!
-
Thanks, i know. Just want to be absolutely sure i do not somehow screw up the Nextcloud database, so used the docker convenience to separate those databases as much as possible



