

-
Posts
170 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Juzzotec
-
-
Does Xteve VPN have a kill switch configurable?
or
Is it better to use regular Xteve with OPVN_Privoxy if that has a killswitch available?
Everything is currently working for me with Xteve_VPN but worried about disconnect and exposed?
-
3 hours ago, Squid said:
There's currently an issue already reported with the plugin that it will stop working if you have installed an update to the MyServers plugin. Rebooting is the fix
Thank you, rebooting now 🙂
-
Hmmm for some reason... changes in theme park are not changing my UI?
-
16 hours ago, itimpi said:
Never means no automatic spin downs.
Thanks, no wonder my disks are not automatically spinning down.
Is Never the default value? I just changed it to 3 hours and will test and report back overnight.
What does everyone else set this as? 1 hr, 4, hrs...
-
This is something I noticed recently as well... my disks never spin down unless I initiate it manually. Open files shows no shares accessed, only cache... hddtemp disabled from grafana-unraid-stack docker.
I checked Disk Settings and Default spin down delay: is set to Never.
I have not touched this setting at all! does never mean, never spin disk down or 0 mins delay to spin down.
Could that be something enabled by default since 6.9.2?
-
On 5/3/2021 at 12:19 PM, Cold Ass Honkey said:
Changing to the vmxnet3 from virtio worked for me too. Thank you for the fix!!
Change to vmxnet3 worked for me too, thanks for the fix.... for anyone else that finds this thread (take note) 👍 👍 👍
-
-
Hi Guys,
Can someone please look into my diagnostics for issues with my VM? every day I go into my Unraid GUI and notice that my Win 10 VM has crashed. I didn't want to provide brief information so I have attached my diagnostics.
Your help appreciated.
Thanks,
Juzzo
-
13 hours ago, JorgeB said:
Vdisks are sparse files.
Thanks for your reply! How should I manage my disk usage efficiently when I can't see the true reflection of used space? Is there a point where it will give me a population, insufficient space when writing to unassigned drive?
-
6 hours ago, SpencerJ said:
Thanks so much!
-
 1
1
-
-
-
Hi,
Is it possible for me to change my username on the forum please? would like to change it to Juzzotec.
Thanks
-
1
-
-
Hi Guys,
I decided to change up the way I use unnassigned disks by no longer giving my VM the whole Portable Drive but rather assign a secondary Vdisk called "storage.img" and then formatting it in Windows so it can be used.
The remaining space in the drive has then been used as a share called "Portable", my question is... I assigned this storage.img a 1TB space but even though it shows 1.07TB in the details as below... it doesn't take up that space in the stats under unassigned devices? why is that? also this may cause issues in measuring how much space I have left on my portable share.
Screenshots
2TB Drive only showing 659GB used?

Storage IMG size shown here, as you can see... it's larger than used space?

VM Assigned Vdisks 1 and 2 is storage.img

Would appreciate help and any advice? This method has saved me from using 2 different 1TB USB slots...
Thanks!
-
12 minutes ago, Rick Gillyon said:
Map /etc/telly to appdata/telly/ and put your m3u there. Reference the m3u in telly.congig.toml as
M3U = "/etc/telly/xxxxx.m3u"If I was starting now I'd use the xTeve docker though.
Thanks Rick, I also found Xteve but as per the post under that docker page.
I can't pass the channels into plex because I cant map them to the correct channel name... do you know what I need to do here?
-
I cant add the channel mappings? none of them match...? confused... configuration went through fine until trying to add channels to plex.
-
On 10/9/2018 at 4:36 AM, Rick Gillyon said:
Set CA to show DockerHub in searches, install from there.
Hi Rick, I have multiple IPTV entries but none start... also no options to put in M3U file port etc as per the original setup?
-
What is one thing that makes you proud and one thing that you look forward to for Unraid?
-
Thank you @John_M fixed both my issues in one post...
")
-
16 hours ago, John_M said:
Yes, your crontab looks good now.
I can't comment on your CPU usage because I don't have enough information. Try monitoring your running processes with htop to see if there's something keeping your CPU busy. Some Docker containers, such as Plex, do a lot of housekeeping in the background. The command you give should be accurate for assessing clock speeds, provided you're running it from an Unraid command prompt. It won't be accurate if you run it from within a VM, for example. If you have the Tips and Tweaks plugin installed you can choose a different CPU scaling governor, such as "Power Save" or "On Demand" if it's available. Yours might be set to Performance, perhaps.
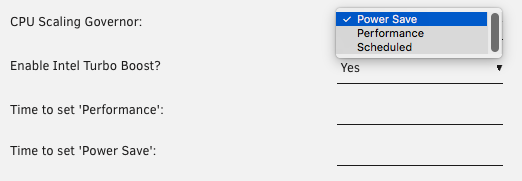
@John_M You are a legend
 I installed Tips and Tweaks and as you said it was set to...
I installed Tips and Tweaks and as you said it was set to...
CPU Frequency Scaling
Driver: Intel Pstate
Governor: Performance
I set it to Governor: Power Save and now the CPU is scaling down to 800mhz when I'm not doing anything.
Every 1.0s: cat /proc/cpuinfo | grep -i mhz HORIZONLAB: Tue May 28 21:48:08 2019 cpu MHz : 800.107 cpu MHz : 800.228 cpu MHz : 800.026 cpu MHz : 800.041 cpu MHz : 800.067 cpu MHz : 800.000I just want to know why this was set to performance by default and also will this affect performance at all?
-
17 hours ago, John_M said:
Do you have the Dynamix Schedules plugin installed? If you do you can reset the schedules by going to Settings -> Scheduler and scrolling down to the Fixed Schedules section. Have you tried rebooting? That might fix it as the crontabs are, I believe, re-created when you boot. You might want to run a disk check on your USB boot device on a separate PC (shut down Unraid before unplugging it) in case it has become corrupt.
Thanks @John_M I reset the Fixed Schedules and my output of crontab -l is below. Is this correct now? I'm not seeing these failed parsing crontab for user root logs as frequent.
root@HORIZONLAB:~# crontab -l # If you don't want the output of a cron job mailed to you, you have to direct # any output to /dev/null. We'll do this here since these jobs should run # properly on a newly installed system. If a script fails, run-parts will # mail a notice to root. # # Run the hourly, daily, weekly, and monthly cron jobs. # Jobs that need different timing may be entered into the crontab as before, # but most really don't need greater granularity than this. If the exact # times of the hourly, daily, weekly, and monthly cron jobs do not suit your # needs, feel free to adjust them. # # Run hourly cron jobs at 47 minutes after the hour: 47 * * * * /usr/bin/run-parts /etc/cron.hourly 1> /dev/null # # Run daily cron jobs at 4:40 every day: 40 4 * * * /usr/bin/run-parts /etc/cron.daily 1> /dev/null # # Run weekly cron jobs at 4:30 on the first day of the week: 30 4 * * 0 /usr/bin/run-parts /etc/cron.weekly 1> /dev/null # # Run monthly cron jobs at 4:20 on the first day of the month: 20 4 1 * * /usr/bin/run-parts /etc/cron.monthly 1> /dev/nullThe only issue I have left is my CPU clock speed is always high even though load is low.
Is the command watch -n 1.0 "cat /proc/cpuinfo | grep -i mhz" accurate?
Every 1.0s: cat /proc/cpuinfo | grep -i mhz HORIZONLAB: Mon May 27 15:06:03 2019 cpu MHz : 3850.181 cpu MHz : 3806.042 cpu MHz : 3893.782 cpu MHz : 3887.109 cpu MHz : 3454.613 cpu MHz : 3889.451 -
40 minutes ago, itimpi said:
That is definitely wrong. My system shows
root@DJW-UNRAID-VM2:~# crontab -l # If you don't want the output of a cron job mailed to you, you have to direct # any output to /dev/null. We'll do this here since these jobs should run # properly on a newly installed system. If a script fails, run-parts will # mail a notice to root. # # Run the hourly, daily, weekly, and monthly cron jobs. # Jobs that need different timing may be entered into the crontab as before, # but most really don't need greater granularity than this. If the exact # times of the hourly, daily, weekly, and monthly cron jobs do not suit your # needs, feel free to adjust them. # # Run hourly cron jobs at 47 minutes after the hour: 47 * * * * /usr/bin/run-parts /etc/cron.hourly 1> /dev/null # # Run daily cron jobs at 4:40 every day: 40 4 * * * /usr/bin/run-parts /etc/cron.daily 1> /dev/null # # Run weekly cron jobs at 4:30 on the first day of the week: 30 4 * * 0 /usr/bin/run-parts /etc/cron.weekly 1> /dev/null # # Run monthly cron jobs at 4:20 on the first day of the month: 20 4 1 * * /usr/bin/run-parts /etc/cron.monthly 1> /dev/null
As you can see your entries are missing the fields that specify the times which explains your error messages. I cannot remember how you can reset these via the GUI.
 Thanks for figuring that out, hope someone has an idea, I need to fix this... the errors are happening every 15mins.
Thanks for figuring that out, hope someone has an idea, I need to fix this... the errors are happening every 15mins.
-
7 hours ago, Squid said:
What's the output of
crontab -lroot@HORIZONLAB:~# crontab -l # If you don't want the output of a cron job mailed to you, you have to direct # any output to /dev/null. We'll do this here since these jobs should run # properly on a newly installed system. If a script fails, run-parts will # mail a notice to root. # # Run the hourly, daily, weekly, and monthly cron jobs. # Jobs that need different timing may be entered into the crontab as before, # but most really don't need greater granularity than this. If the exact # times of the hourly, daily, weekly, and monthly cron jobs do not suit your # needs, feel free to adjust them. # # Run hourly cron jobs at 47 minutes after the hour: * * * * /usr/bin/run-parts /etc/cron.hourly 1> /dev/null # # Run daily cron jobs at 4:40 every day: * * * /usr/bin/run-parts /etc/cron.daily 1> /dev/null # # Run weekly cron jobs at 4:30 on the first day of the week: * * /usr/bin/run-parts /etc/cron.weekly 1> /dev/null # # Run monthly cron jobs at 4:20 on the first day of the month: * * /usr/bin/run-parts /etc/cron.monthly 1> /dev/null -
-
1 minute ago, Squid said:
Any user scripts running hourly?
How can I check this, I haven't played around with scripts before. I have run Unraid for a very long time so maybe I did something a long time ago.



[Support] alturismo - Repos
in Docker Containers
Posted
Thank you very much") I will look into your recommendation.
I will look into your recommendation.
So Xteve automically kills the connection once the vpn drops??