Goulasch
Members
-
Joined
-
Last visited
-
update
-
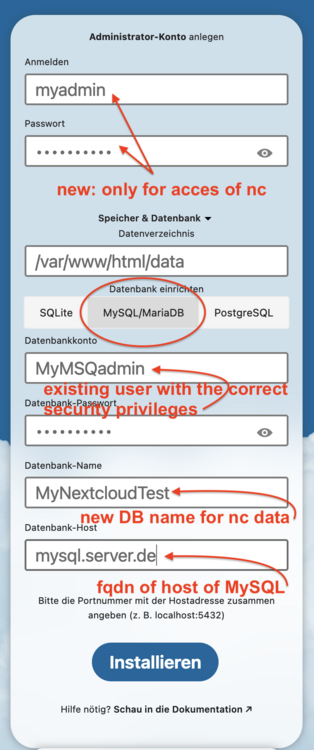
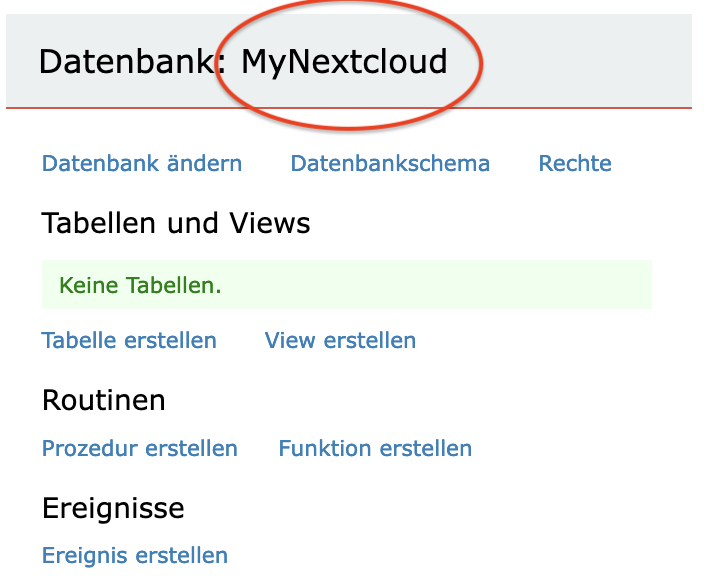
its not possible to create nextcloud database in MySQL/Maria DB Versions: - unraid 6.12.13 - mysql (docker image) 8.4.2 (newer version not possible because of 'native-password' problematic) - nextcloud (docker image) last updated Sep 7, 2024 No problems during fetching image and installing nextcloud itself in /mnt/user/appdata AND /mnt/cachepool/appdata (only here is the "autoconfig" file). 1st run: The information shown has been provided in the installation mask. The result was an "server error". The user "oc_ncadmin" was created as well as the database but no table ! 2nd run: same error as in 1st run. 3nd run: erase "/mnt/cachepool/appdata/nextcloud" (but NOT "/mnt/user/appdata/nextcloud/") and "force update of the docker container". result see screenshot. But again: the updater created "/mnt/cachpool" ... entries. starting nextcloud fails because of access rights. 4th run: remove docker container with out erasing image. remove all nextcloud dirs re-install via "Apps" mode "Re-install froml Previous Apps" webui --> connection error 5th run: remove docker container incl. erasing image remove all nextcloud dirs same as 4th run 6th run: same as 5th run + remove all db-entries from installations before. Remark: If an IP address is used instead of a fqdn, every time a server error occurs. if user exist in the mysql db the installation procedure add new user automatically with the same username+number (counting from 1+) in the db. Is it really wanted ? I specified the user in the templates myself. Why is it not simply adopted or left as is ?:? By-the-way: Manual added vars MYSQL_HOST, MYSQL_ .... + NEXTCLOUD_ADMIN, NEXTCLOUD_ADMIN_PASSWORD ... are NOT interpreted for an "automatic install". Conclusion: Docker image in combination with the installation procedure for MySQL/Maria DB are very buggy in my case. But may be there are some tricks and hints ? Any help is appreciated ...





-
failure 1 --> docker service couldn't (re)start: ---- and failure 2 --> smbd errors (note the different spellings of the FILE_NAME) Attached the diagnostic file. Any help is appreciated ... unraidtower-diagnostics-20240717-0811.zip
-
I didn't find a solution. Therefore I have to switch my raid to XFS or ZFS. What would be the recommendation? Size of the raid is 92 TB - filled with 32 TB - splitted over 7 disks. Any trick to save the data from raid, format the disks and restore the data ?
-
Because using the rsync-daemon on unraid produces the same failures, I checked this problem by using an unassigned XFS formatted disk + rsync --> no problem --> all extended attributes were copied. Same disk formatted with btrfs --> error: rsync_xal_set: lsetxattr... Searching for "btrfs lsetxattr" produces a lot of discussions about this problem - most of them are older. But there are indications that this is a BTRS problem (maybe in combination with the kernel ?). Here is a link for a work-around on SELinux. As a user, I cannot solve such a problem. But perhaps the developers at unraid can take a closer look and give feedback here ? Any help is appreciated !
-
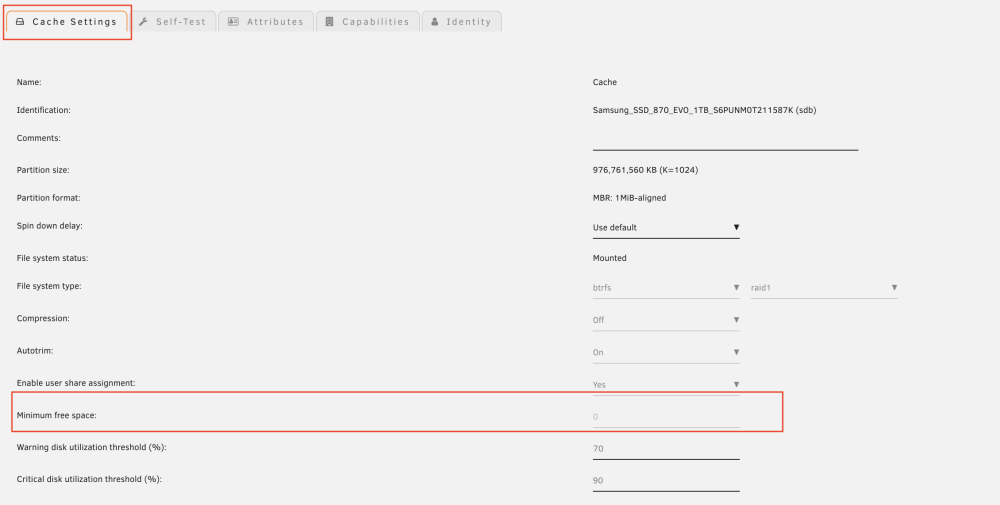
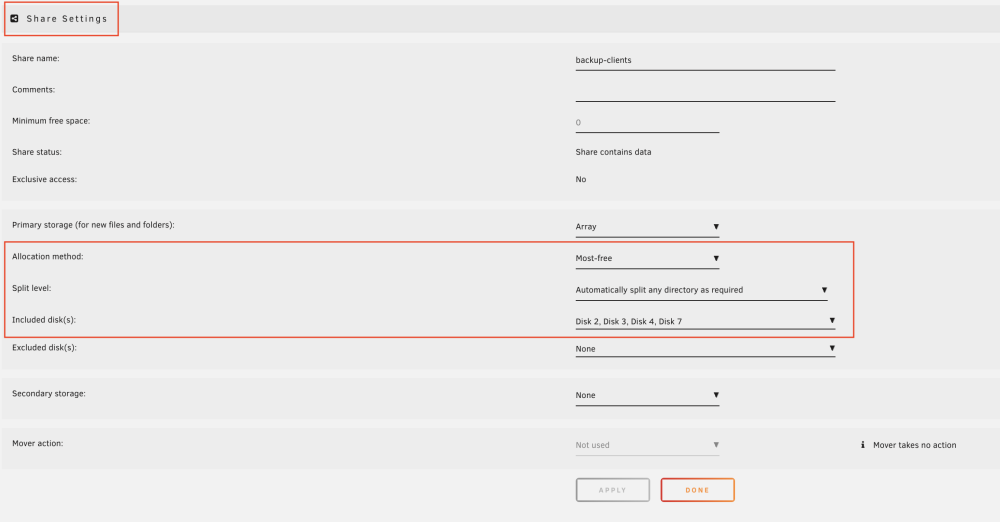
you mean the 1st attached screenshot ? I never received "out of space" errors. like screenshot #2 or for every disk ? On this share you can see that distribution should be made to the assigned disks 2,3,4,7 taking the free storage space into account "Allocation method: Most-free". Strangely, disk 2 is 95% full, disk 3 is 11% full disk 4 is 11% full disk 7 is 40% full. This memory allocation is actually incorrect. I don't think it could have anything to do with the cache setting, right ? Maybe another specialist can take a look at it? There must be more users who back up macOS data with extended attributes on unraid (also with rsync) ?! Don't they all have any problems?
-
no idears ?
-
no problem ... here it is .... unraidtower-diagnostics-20240107-1725.zip
-
using rsync to backup iMac to unraid. Updated the rsync version on the Mac so it is identical with the version on the unraid server: On MacOS: rsync version 3.2.7 protocol version 31 - Sonoma 14.1.2 On Unraid: rsync version 3.2.7 protocol version 31 - Linux #1 SMP PREEMPT_DYNAMIC Wed Nov 29 12:48:16 PST 2023 After starting the rsync job on the Mac # sudo rsync -M--fake-super -rlatgoDiv --force -h --fake-super --iconv=utf-8-mac,utf-8 --acls --stats -X -q -v -P --perms --inplace --remote-option=--log-file=/mnt/user/backup-clients/log/rsyncd-daily.log --include-from=rsync_include_daily.txt --exclude-from=rsync_imac_exclude.txt --log-file-format='%m %B %U %G %o %8l %n' --log-file=rsyncd-daily-on-macos.log /* / [email protected]:/mnt/user/backup-clients/Backup_iMac_Daily suddenly a lot of errors are noted in the log: and both are nonsense ... When checked extended attribute on macOS: $ xattr -l /Users/testuser/Library/Containers/jp.co.canon.ij.pesp.esplaunchagent com.apple.FinderInfo: com.apple.containermanager.identifier: jp.co.canon.ij.pesp.esplaunchagent com.apple.containermanager.schema-version: 44 com.apple.containermanager.uuid: 13090346-5FB4-4E22-B6EB-83030C9FD044 com.apple.data-container-personality: bplist00? Same on Unraid after running rsync job # getfattr -d /mnt/user/backup-clients/Backup_iMac_Daily/Users/testuser/Library/Containers/jp.co.canon.ij.pesp.esplaunchagent getfattr: Removing leading '/' from absolute path names # file: mnt/user/backup-clients/Backup_iMac_Daily/Users/testuser/Library/Containers/jp.co.canon.ij.pesp.esplaunchagent user.com.apple.FinderInfo=0sAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA= user.com.apple.containermanager.identifier="jp.co.canon.ij.pesp.esplaunchagent" user.com.apple.containermanager.schema-version="44" user.com.apple.containermanager.uuid="13090346-5FB4-4E22-B6EB-83030C9FD044 The extended attribute com.apple.data-container-personality and it’s value “bplist00?“ actually missing When storing this attribute manually on the Unraid server via # setfattr -n "user.com.apple.data-container-personality" -v 'bplist00?' /mnt/user/backup-clients/Backup_iMac_Daily/Users/testuser/Library/Containers/jp.co.canon.ij.pesp.esplaunchagent and check the same file again: # getfattr -d /mnt/user/backup-clients/Backup_iMac_Daily/Users/testuser/Library/Containers/jp.co.canon.ij.pesp.esplaunchagent getfattr: Removing leading '/' from absolute path names # file: mnt/user/backup-clients/Backup_iMac_Daily/Users/testuser/Library/Containers/jp.co.canon.ij.pesp.esplaunchagent user.com.apple.FinderInfo=0sAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA= user.com.apple.containermanager.identifier="jp.co.canon.ij.pesp.esplaunchagent" user.com.apple.containermanager.schema-version="44" user.com.apple.containermanager.uuid="13090346-5FB4-4E22-B6EB-83030C9FD044" user.com.apple.data-container-personality="bplist00?" —> all fine. That means that the BTRFS can store this extended attributes. So what could be the reason that this is not done by rsync during the backup ? Because the error „.. no space left on device“ is noted in the same log : # mount shfs on /mnt/user type fuse.shfs (rw,nosuid,nodev,noatime,user_id=0,group_id=0,default_permissions,allow_other) which is a raid of 7 disks and formatted with btrfs. # df -h /mnt/user Filesystem Size Used Avail Use% Mounted on shfs 84T 28T 57T 34% /mnt/us # df -ih /mnt/user Filesystem Inodes IUsed IFree IUse% Mounted on shfs 0 0 0 - /mnt/user So enough space incl for inodes are availible. No quota installed. Any help is appreciated !
-
backup local desktop disk to unraid btrfs formatted disk with rsync (unraid pro 6.11.5). Rsync stopped with following error: At the time of the crash, a DMS (Devonthink) is being backed up. An analysis shows that there are various files on the (unraid) target disk in the corresponding directory with file size = zero. What all these files additionally have in common is that the name contain the three special characters "\|\" (without the quotes). Example name of a file stored on the btrfs-disk (anonymized): Could this be the reason that Unraid is sending an (io) error to rsync ?
-
found a workaround: instead of using # rm -rf /path/to/delete/complete/directory split it into # find "/path/to/delete/complete/directory/" -name "*.*" -exec rm -rf {} + # rmdir "/path/to/delete/complete/directory" since then no (not erasable) ".FUSE_HIDDDEN<hash>" files were created.
-
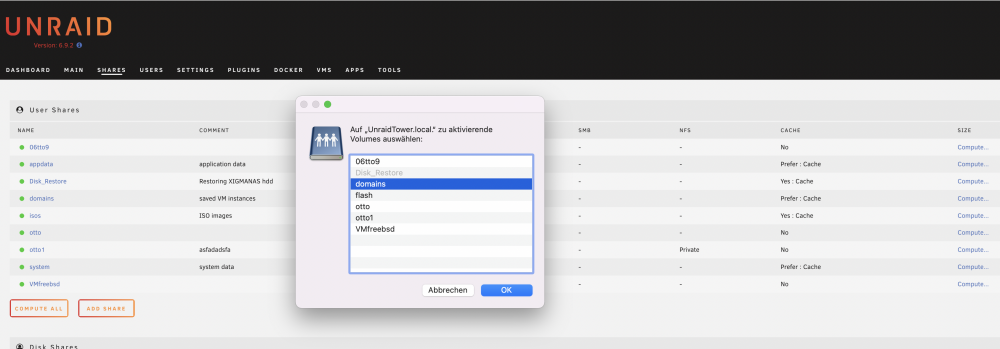
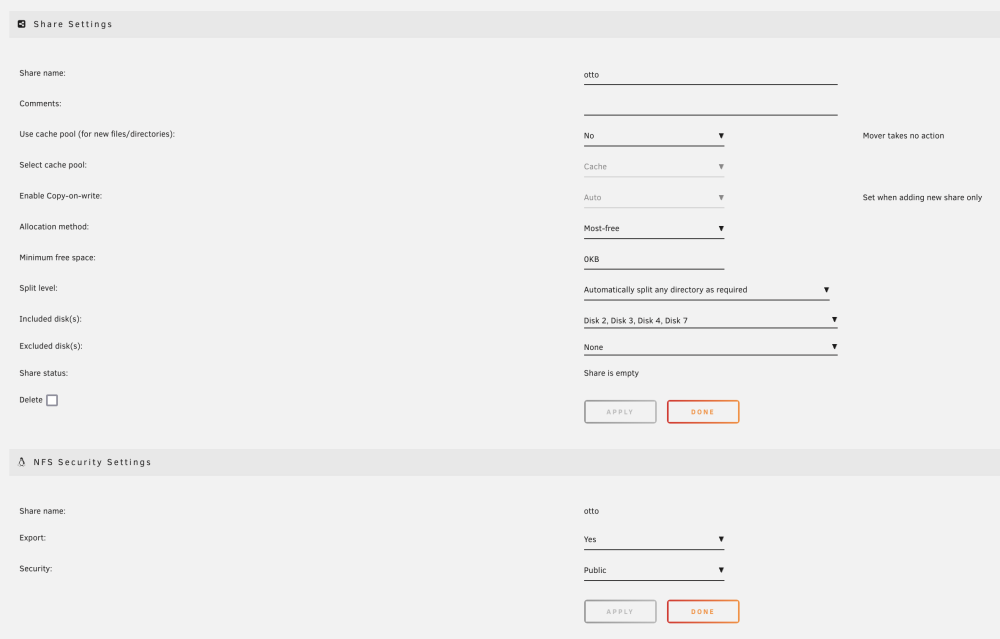
backup VMware images to an UNRAID Nfs3 share. The cache pool (uses) was originally definied as "Prefer" but I ran into trouble with the "Mover" (similar problems as here). So I switched to "No" and the backups were crated as exspected. After 3 backups, the backup procedure should delete the oldest backup with # rm -rf /ntfs/share/vm/directory/oldest But this fails So I checked with "lsof" if any other task are using files in this directory (see this topic). But without luck. That was the reason to create a new share "otto" and shared it by Nfs3 (no SMB) for testing under Unraid to isolate the problem (see attachments). I was able to narrow down the problem as follows: 1. create new dir from console of ESX server # mkdir /vmfs/volumes/otto/Unraid_new_backup_dir # ls -lah /vmfs/volumes/otto/Unraid_new_backup_dir total 0 drwxr-xr-x 1 24117299 24117360 0 Mar 4 17:12 . drwxrwxrwx 1 24117298 24117299 0 Mar 4 17:12 .. 2. create a file in that dir # echo "xx" > /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt # ls -lah /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt -rw-r--r-- 1 24117299 24117360 3 Mar 4 17:15 /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt 3. remove file # rm /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt # ls -lah /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt ls: /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt: No such file or directory 4. remove directory # rm /vmfs/volumes/otto/Unraid_new_backup_dir # ls -lah /vmfs/volumes/otto lrwxr-xr-x 1 root root 17Mar 4 17:19 /vmfs/volumes/otto -> eb67bacf-771b242d # ls -lah /vmfs/volumes/eb67bacf-771b242d/ total 0 drwxrwxrwx 1 24117298 24117299 0 Mar 4 17:20 . drwxr-xr-x 1 root root 512 Mar 4 17:20 .. So far OK ... but when use the command "rm -rf ...." in the same situation # mkdir /vmfs/volumes/otto/Unraid_new_backup_dir # echo "xx" > /vmfs/volumes/otto/Unraid_new_backup_dir/only_a-textfile.txt # rm -rf /vmfs/volumes/otto/Unraid_new_backup_dir resulted When I cancel the task, then no files resides inside and the directory itself can be deleted with "rmdir". For completeness: # exportfs -v /mnt/user/otto <world>(async,wdelay,hide,no_subtree_check,fsid=109,anonuid=99,anongid=100,sec=sys,rw,insecure,root_squash,all_squash) Any idears to solve that problem are appreciated !

-
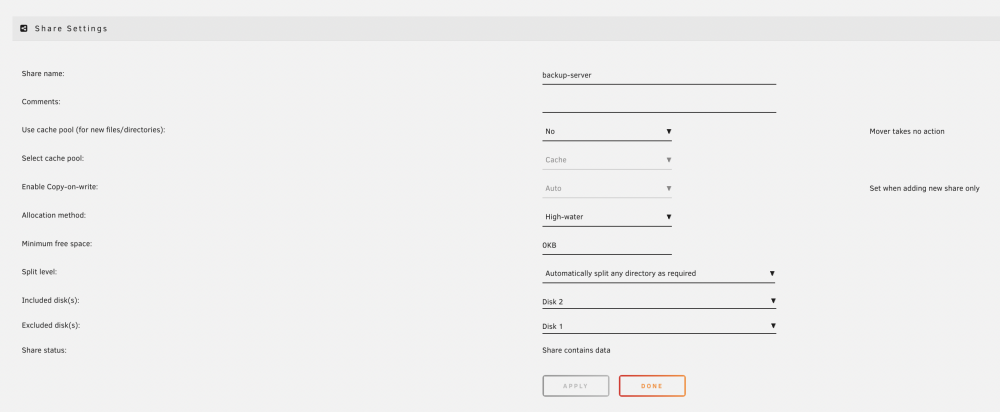
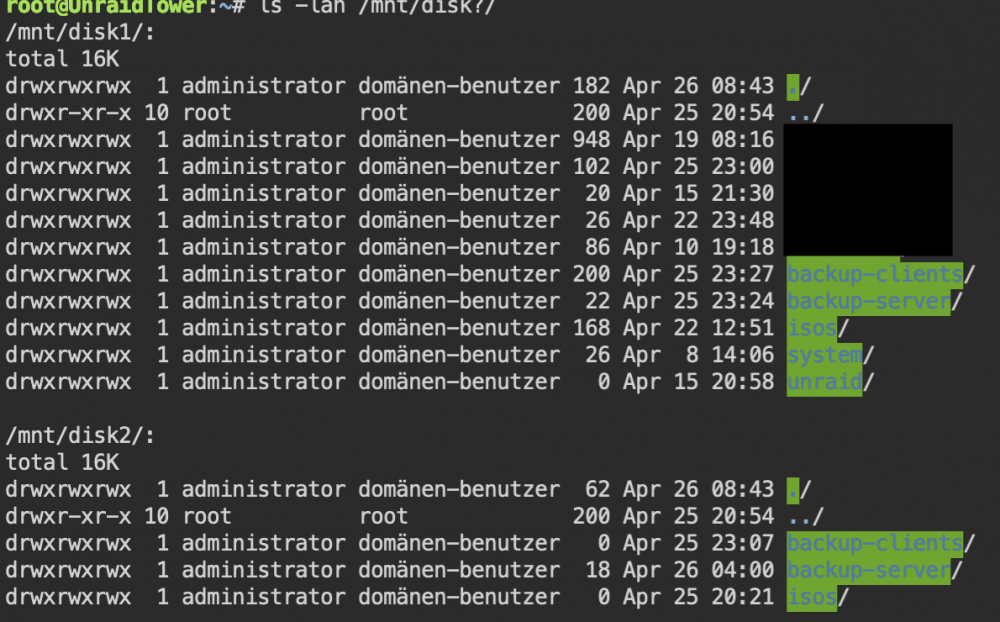
am still a newbie in dealing with unraid. Maybe that's why I still have the following problems in understanding. Here is the basic config for the actual array: This relay will be expanded with a lot of other disks (unassigned devices) which have to be restored beforehand. This is the reason why I don´t want to split the created shares on more than 1 disk: With this configuration, the share "backup-server" would have to be created exclusively on Disk2 ? In fact, however, it is created on Disk1 and Disk2: Note: user+group are created from Unraid (App is member of AD). At the moment it is not clear to me why this is happening. I also don't quite understand why Unraid creates two shfs links (user + user0): Both points to the content of Disk1. In addition, I cannot understand why when creating a new share via the GUI, the content of the actually existing directory with the same name is simply deleted (/mnt/Disk2/backup-server) ! As a result, 44 GB of backup data has been lost and must be backed up again. If Unraid wanted it that way, then you could never share an existing directory afterwards? Attached the diagnostic file. Any help is appreciated. unraidtower-diagnostics-20220426-0920.zip

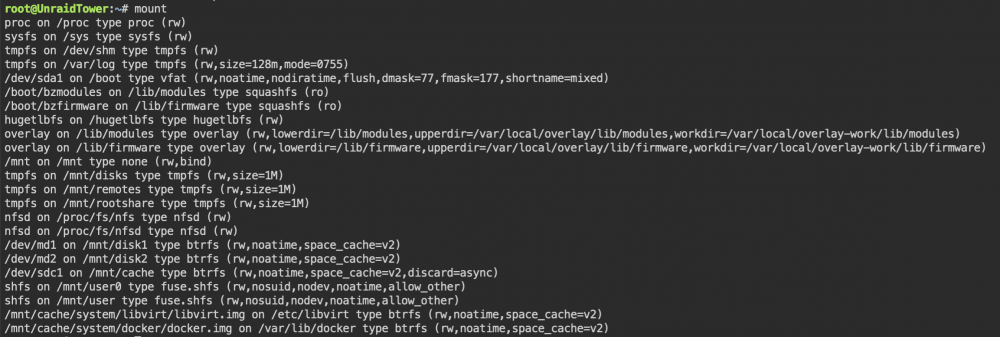
-
that means: If I understand this correctly the system will overwrite my backups (created with rsync) with the default permissions ? That would be no solution. So far I could see, that´s only possible in the console ?
-
All entries under /mnt are owned by "administrator:domänen-benutzer". I haven't changed anything myself - not even via the terminal. But in global SMB settings this user & group are entered as default groups. I thought that this would be changed after joining to the domain ? That is understable but Unraid doesn´t work as exspected. That's the only reason I manually created a subdirectory. So I changed now the owner of ONE subdir: this is the result (all subdirs are changed) : I exspected that only the subdir "/mnt/user" will change ? After that I created a new share via Webgui --> a new page is displayed where the values for NFS and SMB security can be entered. Exactly at this point of time the owner are changed (again) from Unraid ! This doesn't change if the export for NFS and SMB is then released via Webgui. Nevertheless, all shares are now suddenly displayed via the webgui under "User Shares" and can also be accessed from the clients 🙂 BUT including internal subdirs from Unraid: "appdata", "domains", "isos", "system" ... which is certainly not intended, is it ?