

jcato
-
Posts
76 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jcato
-
-
Not sure when I upgraded to 6.9.2, but it could've been around the time problems started. I do use i915. Seems like there is not a solution except for going back 6.8.3. Not sure what that might break if I do, though.
-
I got the syslog server setup. Just had another crash, but I don't see anything helpful in the syslog.
Dec 3 03:50:20 unRaid5 emhttpd: spinning down /dev/sdn Dec 3 04:40:01 unRaid5 root: Fix Common Problems Version 2021.08.05 Dec 3 05:45:45 unRaid5 emhttpd: spinning down /dev/sdm Dec 3 05:46:43 unRaid5 emhttpd: spinning down /dev/sdk Dec 3 06:08:51 unRaid5 emhttpd: read SMART /dev/sdn Dec 3 07:09:15 unRaid5 emhttpd: spinning down /dev/sdn Dec 3 07:10:00 unRaid5 emhttpd: read SMART /dev/sdn Dec 3 07:36:58 unRaid5 emhttpd: read SMART /dev/sdm Dec 3 08:27:01 unRaid5 emhttpd: spinning down /dev/sdn Dec 3 08:37:00 unRaid5 emhttpd: spinning down /dev/sdm Dec 3 12:20:27 unRaid5 cache_dirs: Arguments=-l off Dec 3 12:20:27 unRaid5 cache_dirs: Max Scan Secs=10, Min Scan Secs=1 Dec 3 12:20:27 unRaid5 cache_dirs: Scan Type=adaptive Dec 3 12:20:27 unRaid5 cache_dirs: Min Scan Depth=4 Dec 3 12:20:27 unRaid5 cache_dirs: Max Scan Depth=none Dec 3 12:20:27 unRaid5 cache_dirs: Use Command='find -noleaf' Dec 3 12:20:27 unRaid5 cache_dirs: ---------- Caching Directories ---------------I can include more from the syslog, but it seems like the issue was between 08:37 and 12:20 when I restarted and nothing was logged then. I'll attach the post-restart diagnostic file, if that helps. What else can I do to get better information.
Thanks
-
On 9/28/2021 at 11:26 AM, hugenbdd said:
There was an Echo in there for that statement. Next release will have it updated to follow the logging settings. (But that may be a while...)
If you want to fix it now.
Line 396 of /usr/local/emhttp/plugins/ca.mover.tuning/age_mover
Change
echo "mover not Needed."
to
mvlogger "Mover not Needed."
I made this change and emails stopped. But, then they started again. I rechecked the file and it's back to an echo statement.
I think it's because I rebooted. Does this change not survive a reboot? If so, is there a way to make it permanent?
-
Just happened to me for first time. Running UnRaid 6.9.2. I caught it with the logs at 77% full. I deleted syslog.1 and dropped to 51%. Can I delete syslog, too, to get usage down more? I restarted nginx and errors stopped. Now replaced with the following error every 2 seconds:
Sep 30 08:41:23 unRaid5 nginx: 2021/09/30 08:41:23 [alert] 12576#12576: worker process 18277 exited on signal 6How to stop this error message? Reboot?
Things I did yesterday that may or may not matter:
Installed shinobi
Stopped openvpn-as docker and installed and setup VPN Manager plugin
I had been using MS Edge on laptop with a pinned tab to UnRaid. Switched to Firefox, also pinned a tab to UnRaid, but both were running at the same time
-
On 3/16/2021 at 9:33 AM, hugenbdd said:
It's because I left ECHO statements in the script. These help me catch bugs for the new release.
I will release a new version in the next few days that will comment out the echo statements.
Hello! Has this happened again? I'm getting emails when the daily cron job runs that say "Mover not Needed." I don't get one every day, I guess only when the mover is not needed.😃
Thanks
-
Thanks! I have that setup now, so I'll check back after the next crash...
-
Over the past 2 weeks Unraid server has crashed 4 times, I think. Each time requires a hard reset which results in a parity check. By crashing, I mean the web gui is unreachable and pings are unanswered.
I suspect a hardware issue, but not sure how to check for one. The log file only contains info since the reboot. I'm not sure how to find out what was happening just before the crash.
Happy to provide additional info, just not sure what is needed.
Any suggestions much appreciated!
-
Thanks! But, I had to get it ordered to get here quickly. I went with a Seagate IronWolf 8TB. A little better price and delivery time. It's 7200 rpm, so maybe that will give a little better performance. Probably not noticeable, though. Anyway, hopefully it lasts awhile.
Rebuilding parity now. After about 15 minutes, running at 122MB/s with a estimate of 18hrs to finish.
-
No luck with the cable. When I booted I could hear one of the drives grinding and stopping. Unplugged it and that noise went away. Seems like a truly dead drive.
Except for one, my other drives are also WD Red ERFX. I see those in a lot of setups. Should I still trust them and get another one or is there a consensus on a better drive for unRaid?
-
After reboot, parity is unassigned and the drive formerly know as parity is not visible. I'm going to shut it down and switch out the sata cable, maybe I get lucky.
I checked warranty status and, of course, it is out of warranty (since 8/2019).
-
Well, this just happened. I did parity check a couple of days ago with no errors. System is still running, but no parity is obvs not good. What should be my first step? Reboot and hope it works until I can get a replacement disk?
Thanks
Partial log file when it happened. Full diagnostics attached.
Jan 5 13:00:08 unRaid5 kernel: ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0
Jan 5 13:00:08 unRaid5 kernel: ata1.00: irq_stat 0x40000001
Jan 5 13:00:08 unRaid5 kernel: ata1.00: failed command: READ DMA
Jan 5 13:00:08 unRaid5 kernel: ata1.00: cmd c8/00:48:f0:a4:00/00:00:00:00:00/e0 tag 0 dma 36864 in
Jan 5 13:00:08 unRaid5 kernel: res 51/40:48:f0:a4:00/00:00:00:00:00/e0 Emask 0x9 (media error)
Jan 5 13:00:08 unRaid5 kernel: ata1.00: status: { DRDY ERR }
Jan 5 13:00:08 unRaid5 kernel: ata1.00: error: { UNC }
Jan 5 13:00:17 unRaid5 kernel: ata1.00: qc timeout (cmd 0x27)
Jan 5 13:00:17 unRaid5 kernel: ata1.00: failed to read native max address (err_mask=0x5)
Jan 5 13:00:17 unRaid5 kernel: ata1.00: HPA support seems broken, skipping HPA handling
Jan 5 13:00:17 unRaid5 kernel: ata1.00: revalidation failed (errno=-5)
Jan 5 13:00:17 unRaid5 kernel: ata1: hard resetting link
Jan 5 13:00:22 unRaid5 kernel: ata1: link is slow to respond, please be patient (ready=0)
Jan 5 13:00:26 unRaid5 kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
Jan 5 13:00:35 unRaid5 kernel: ata1.00: qc timeout (cmd 0xef)
Jan 5 13:00:35 unRaid5 kernel: ata1.00: failed to enable AA (error_mask=0x4)
Jan 5 13:00:35 unRaid5 kernel: ata1.00: revalidation failed (errno=-5)
Jan 5 13:00:35 unRaid5 kernel: ata1: limiting SATA link speed to 3.0 Gbps
Jan 5 13:00:35 unRaid5 kernel: ata1: hard resetting link
Jan 5 13:00:40 unRaid5 kernel: ata1: link is slow to respond, please be patient (ready=0)
Jan 5 13:00:44 unRaid5 kernel: ata1: SATA link up 3.0 Gbps (SStatus 123 SControl 320)
Jan 5 13:01:04 unRaid5 kernel: ata1.00: qc timeout (cmd 0xec)
Jan 5 13:01:04 unRaid5 kernel: ata1.00: failed to IDENTIFY (I/O error, err_mask=0x4)
Jan 5 13:01:04 unRaid5 kernel: ata1.00: revalidation failed (errno=-5)
Jan 5 13:01:04 unRaid5 kernel: ata1.00: disabled
Jan 5 13:01:09 unRaid5 kernel: ata1: link is slow to respond, please be patient (ready=0)
Jan 5 13:01:13 unRaid5 kernel: ata1: SATA link up 3.0 Gbps (SStatus 123 SControl 320)
Jan 5 13:01:13 unRaid5 kernel: sd 1:0:0:0: [sdb] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 5 13:01:13 unRaid5 kernel: sd 1:0:0:0: [sdb] tag#0 Sense Key : 0x2 [current]
Jan 5 13:01:13 unRaid5 kernel: sd 1:0:0:0: [sdb] tag#0 ASC=0x4 ASCQ=0x21
Jan 5 13:01:13 unRaid5 kernel: sd 1:0:0:0: [sdb] tag#0 CDB: opcode=0x88 88 00 00 00 00 00 00 00 a4 f0 00 00 00 48 00 00
Jan 5 13:01:13 unRaid5 kernel: print_req_error: I/O error, dev sdb, sector 42224
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42160
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42168
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42176
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42184
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42192
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42200
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42208
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42216
Jan 5 13:01:13 unRaid5 kernel: md: disk0 read error, sector=42224 -
Back in April I started getting emails from this plugin. hugenbdd replied with a fix that worked. Here's a link to my post, followed by his replies.
Well, the emails are back. They're address to root with a bcc to my gmail address. The subject line (cron for user root /usr/local/sbin/mover force 2>/dev/null) is the same, but the content is a little different:
Complete Mover Command: find "/mnt/cache/Backups/" -depth -mtime +5 | /usr/local/sbin/move -d 0
Complete Mover Command: find "/mnt/cache/Downloads/" -depth -mtime +5 | /usr/local/sbin/move -d 0
Complete Mover Command: find "/mnt/cache/Emby/" -depth -mtime +5 | /usr/local/sbin/move -d 0
Complete Mover Command: find "/mnt/cache/TV/" -depth -mtime +5 | /usr/local/sbin/move -d 0It's been doing this for awhile. I'm a little surprised no one else has posted about it. I must have something setup different than others. Any ideas?
-
I'm having issues, too. Recordings from HDHomerun (*.ts files) give a playback error (No compatible streams available). Emby is set to use quicksync, but in Settings, Transcoding, switching to Advanced doesn't show any hardware encoders/decoders available.
I rolled back to linuxserver/emby:4.5.2.0-ls59, as suggested above. Hardware shows back up and recordings play again.
-
Ok, thanks! So is there a way to tell if Sonarr is going through the vpn or not?
-
I've been struggling with this too. I downloaded the strong files and dropped them in (Toronto). Before editing the opvn file, I restarted just to test and it worked!
My problem now is that Sonarr isn't going through the proxy. I tested this by opening the console and typing curl ifconfig.io and get my IP from my ISP. Doing the same with SAB's docker I get an IP in Toronto. If I change my browser to use the proxy it works. Any idea why?
Thanks
-
Well, I guess running it for the past 20 hours was a bit of a waste of energy!
One other thing I forgot to ask about...When I plug a network cable into the IPMI LAN socket, nothing happens. The activity lights don't light up and it doesn't get an IP address. If I plug into one of the other LANs, it works and IMPI works. I looked through the BIOS, but didn't find a setting I thought would help. Did I miss something? Or is that port maybe not working?
Thanks!
-
I've finally have this setup in a test server. I've flashed the BIOS to L2.21A that was provided a couple of pages back. Only BIOS setting I changed was to Onboard graphics. Is there anything else that needs changing?
Did anyone run memtest86+? Since it's ECC, do I need to change any settings for it to be effective? I guess I'm wondering how ECC plays into this test.
-
Thanks, Hoop and wreck (BTW, I'm a BSIE '92, Go Jackets!). The iGPU is important, so the SM bundle is out. I do use Emby and it currently has access to the 1 GPU in the system. I definitely want a GPU for Emby and another for VMs, so an iGPU is important and probably the easiest way to go.
-
 1
1
-
-
So, I think it's time to upgrade my 7-year old server. Currently running an E3-1230v3 on a Supermicro X10SL7-F with 16GB of ECC memory. I was late to upgrading to v6, but, boy! has it increased my usage of the server. That increased usage, though is exposing the limitation of my cores and memory. Unfortunately, I don't think I can upgrade the processor to anything with more cores, just more MHz. So, this bundles looks pretty good. Two questions:
1. I want to add a gaming VM, would this be a good start to that? I'd think so, but is there anything I'm missing in differences between Xeon and desktop cpus?
2. There are now bundles with Supermicro X11SCL-F motherboards. I haven't seen much talk of that one. Of previous buyers, would you still go with the Asus if this had been available (or maybe it was)? I think SM board only has 6 SATA ports compared to 8 on Asus. Any other major differences?
Thanks!
-
On 4/7/2020 at 10:09 AM, hugenbdd said:
jcato
Please try this file.
/usr/local/emhttp/plugins/ca.mover.tuning/age_mover
permissions (755)
-rwxr-xr-x 1 root root 5302 Apr 7 09:58 age_mover*
If this works I'll release an update.
Sorry for delay, but I just did this. I'm not super linux-fluent, but I think I did it right. I updated cron job to run now. I think it did, as my used space on the cache went down. I didn't get an email.
I also see there is an update available. I assume this includes the changes in the this file and I can update like normal?
Thanks
-
Hello, I've been running this since it came out, but the last couple of days, I'm getting an email about the cron job. Not sure why. Any idea?
Subject: cron for user root /usr/local/sbin/mover force 2>/dev/null
No Size Argument Supplied
Share: /mnt/cache/Backups/
Doing Find for Age Only
Age 5
Share: /mnt/cache/Downloads/
Doing Find for Age Only
Age 5
Share: /mnt/cache/TV/
Doing Find for Age Only
Age 5
Share: /mnt/cache/appdata/
Share: /mnt/cache/domains/
Share: /mnt/cache/system/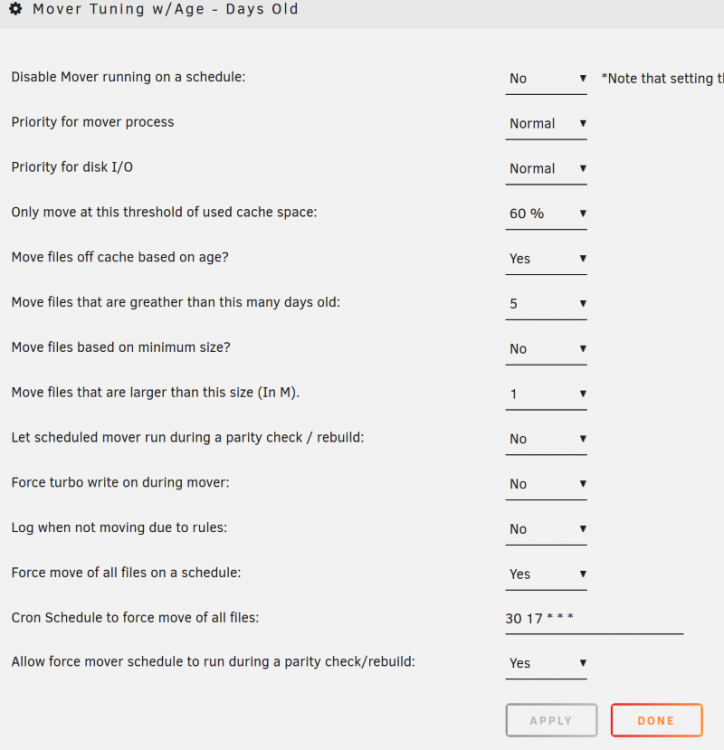
-
I'm installing and using this for the first time and have a question. You've talked about a breaking change to the file structure. Since I have no existing backups is there a way use this new structure from the start? Or is it not implemented yet?
Also, I want to use compression, so is Zstandard the recommended setting?
Thanks!
-
On 2/8/2019 at 5:42 AM, thostr said:
@binhexI now tried to install Emby's own docker container, and here I get the expected results (see screenshot).
Only extra variable I added was GIDLIST=18 by referencing this post. (it didnt work by adding it to your docker)
So somehow your docker isn't working as expected.
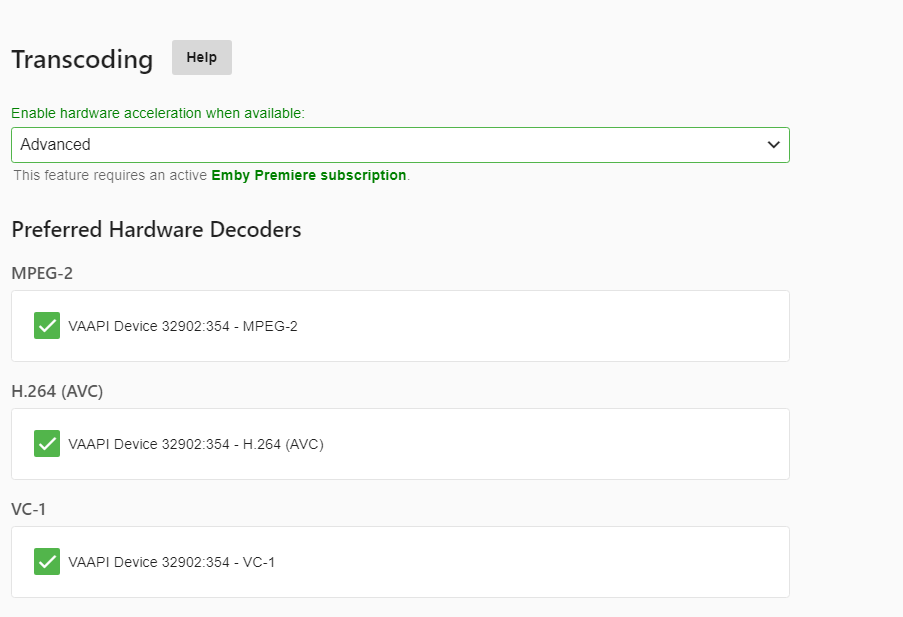
Was this ever sorted out? I'm having the same issue.
Thanks
-
So, I was going to be patient and wait for some responses. I went to watch a show and Kodi would play for 10 seconds and stop. I tried on my laptop and VLC couldn't play any video files. I tried to copy a file to my laptop and that failed too!
So, the flash being borked was obviously a bigger deal than I thought. I telneted in and ran powerdown. I removed the flash drive and put in the laptop. It worked and I made a backup. Put flash back into ESXi server and powered up unRaid. It came up and started a parity check. So, I don't think I shut it down cleanly. Stopped the parity check and started the preclear. It's resuming from where it was. Yes! And I can watch videos again.
All is great now except that I don't know why I lost the flash drive from the vm. Probably has something to do with this:
From log, this keeps repeating:
Jun 14 15:37:52 unRaid5 kernel: sd 0:0:0:0: [sda] 15237120 512-byte logical blocks: (7.80 GB/7.27 GiB) Jun 14 15:37:53 unRaid5 rc.diskinfo[5970]: SIGHUP received, forcing refresh of disks info. Jun 14 15:38:32 unRaid5 kernel: usb 1-2.1: reset high-speed USB device number 5 using xhci_hcd Jun 14 15:38:38 unRaid5 kernel: usb 1-2.1: device descriptor read/64, error -110 Jun 14 15:38:54 unRaid5 kernel: usb 1-2.1: device descriptor read/64, error -110 Jun 14 15:38:54 unRaid5 kernel: usb 1-2.1: reset high-speed USB device number 5 using xhci_hcd Jun 14 15:39:00 unRaid5 kernel: usb 1-2.1: device descriptor read/64, error -110 Jun 14 15:39:16 unRaid5 kernel: usb 1-2.1: device descriptor read/64, error -110 Jun 14 15:39:16 unRaid5 kernel: usb 1-2.1: reset high-speed USB device number 5 using xhci_hcd



Anyone got Idrive working on Unraid ?
in Plugin System
Posted
Thanks, everyone, for the great info on setting this up. It appears to be working, but not without a couple of issues.
I backed up a small folder and it said files backed up successfully, but on the iDrive website, under UnRaid, there are no files.
Trying to connect to UnRaid is very slow and unreliable. If it connects, it disconnects before I can change any settings.
When I do get the remote connection to work, it shows CDP is unchecked. But, it is running in the container. I don't see a way to stop it, only options are start and restart. I think, maybe it runs all the time, it just doesn't do anything if it's not checked.