




UnJustice
Members
-
Joined
-
Last visited
-
Yeah 5.2 is busted at least with the latest unraid version. 5.1.4-2-01 works fine
-
I'll just be 100% here: I haven't used riven for a while. Over six months if not longer. I've been using decypharr and I've been running DUMB (with plex built in. Seems to work a lot better for me). All that to say, as far as I know the origin issues were related to the IP and/or domain needing to be the same as the host ie the same as your unraid server's local IP. If that IP you posted is the same as the host then... I don't know what the issue is. Maybe it is something related to the port change. I don't remember if riven was super annoying with the port or not. I seem to recall having issues with it myself but that was a while ago and I can't say for certain. I need to go through at some point and "clean up" the xml in any case. At least bring it into something close to a mirror state with the DUMB template. I also need to add some directories, and probably remove some others, to reflect recent additions during updates. I just sort of update my own personal template as time goes on. On the newest DUMB builds I have noticed I no longer need to mess with permissions which is amazing. I don't know if that's a result of using decypharr as well though (vs cli_debrid or riven). In any case it has eliminated many headaches on that end. So I'll go through at some point and clean up dmb. I can try using a different port too just for testing. As far as changing config stuff, it depends what you mean I guess. You mean in the DMB frontend? You can go into services and makes changes. You can also change the files directly, but you have to be careful of syntax. Some changes won't save either unless you aren't running the docker container when they're made. It depends what exactly you're trying to change and how
-
Previous to recent updates (maybe 3 weeks ago or so) I never had both directories destined for Plex set to shared. It worked with just the one directory set. However, I've swapped over to "DUMB" (the difference is it includes Plex in the docker image) since then. Mostly for testing purposes, but also I've just been using it. When I tried run riven in DUMB, I couldn't get it to make symlinks that Plex could use. I basically just gave up and swapped over to cli_debrid, which has been fulfilling all my needs happily. Now I wonder if perhaps the shared situation is why I couldn't get it working. Maybe if I time/feel like blowing some stuff up, I'll give it a whirl. Maybe something got kind of messed up or purposefully changed when the creator (i-am-puid0) recently made changes to the directory structure. He consolidated all the previously disparate symlink directories into one shared directory. By shared there I mean riven, cli_debrid, etc. using the same directory not shared in the r/w shared sense. Anyway, it's possible this changed something. I'll look into it and see if I can replicate it and update the template as required.
-
That looks like the normal Zilean initial setup. It has to grab all the "known good sources" from debridmediamanager (DMM) website. It's just a curated list of media torrents that are already cached on RD's servers. It usually takes like 1-2hrs on a first install for Zilean to update. You don't HAVE to use Zilean btw, but I'd highly suggest it. Torrentio works well too though if you are really opposed to zilean.
-
No. The project has undergone some major changes in the past few months and were pushed to live this month. I haven't had time (or didn't know/had to wait for updates myself) to go through and update all the links yet. For the wiki, here is the link: https://i-am-puid-0.github.io/DMB/ Discord here: https://discord.gg/8dqKUBtbp5 I'll update the wiki link for the repo today. I'll check if the discord link is an old and update that too if needed.
-
Reading through that quickly, it seems like everything is working correctly. As far as your questions go: 1. I would personally recommend *not* combining your previous libraries with the Riven/DMB ones. Why? Because it gets confusing and will likely cause you issues at some point when you're trying to figure out "Ok, so is this media on my server or is it in the WebDAV?" You can do whatever you want, but I'm just speaking from experience. Having two libraries will avoid a headache. I believe you can have two (or more) libraries separated but also show up together. Like one local for movies, one remote for movies, then show as just "movies" but I have check on that. As for getting the library to show up period, you just go into your Plex on each device (yes, it's a little annoying. the arrangement doesn't sync, but it also takes like 3 seconds to change). (In a desktop browser, but all devices are basically the same): Left side you should have a vertical list starting with "Home" then a list like Movies (or whatever) and ending with "More >". Click that "More >" and it will display a bunch of libraries you have access to. Ones you are hosting or ones friends invited you to, whatever. You hover the libraries you are interested in, you go to the right side of the library, you click the vertical 3 dots menu thing that shows up, you click "pin". Do this for each library you want to show up on the main page. You can unpin things you don't want. Click the "< Pinned" at the top to go back to the main section and that's it. They should be showing up now. You can rearrange the libraries if you want by clicking the 3 dots vertical menu on the main page and selecting reorder. 2. The .mkv file is not downloaded...necessarily The way it works is like any rclone mount (zurg is just rclone but specialized to stream from debrid sites. it's just rclone + "ideal settings"). It's like a network drive basically. All the stuff you have added to your RD WebDAV shows up in your WebDAV. rclone provides a way of "mounting" this as a drive. The OS effectively just sees another drive. Again, similar to mapping network drives with samb, ftp, etc. When you play that media in Plex it's just streaming (downloading temporarily) the file. RD has very good servers that can put out high enough upload speeds to maintain 4K media bluray quality (so better than like Hulu, Disney, etc. usually output). Even 4K remux files that can run to like 100GB+/movie if you really hate your ISP. rclone is basically able to create the appearance of a real disk existing locally so Plex scans the files as if they are local. 3. You can use Overseerr. You just have to set up the container and add the required stuff (API key and whatever else). I use trakt, although the dev(s?) recently made some API changes to trakt making the free version less desirable. I've been paying for it, but the limits on the free version seem annoying. You can also setup Riven to grab from your Plex watchlists. This requires the "Plex pass" (I'm pretty sure? I don't keep up to date on the little tweaks this companies make, so you gotta check stuff on your own). I bought the lifetime thing from Plex like... 15 years ago almost, so, again I haven't kept up on what they limit or don't limit. If you can use it for free users though, or do choose to pay for the pass version, that's a good option. You just watchlist something in Plex and riven grabs it and adds it. Overseerr is probably "the best" fully free media request software in that list. I've never used listrr or MDB, so I can't even speak on them at all. 4. For rankings (choosing different resolutions like 2160p then 1080p then 720p... etc.) this website has a lot of info: https://dreulavelle.github.io/rank-torrent-name/users/faq/ You should be able to go under Settings -> Ranking and change the settings right there in the UI (it used to be all in a .json, but it seems the dev added the option to edit it right in the UI! Very nice.) I haven't messed with mine very much, but I set it to "best" and then selected 2160p, 1080p and I think the rest is set to default, but not sure. If everything is default riven grabs 1080p relatively small file sizes like 2GB. Just be careful with ranking to not be overly specific or require things that can't be met otherwise might end up with issues grabbing media. Remember that the newest fastapi branch added the ability to individually control the elements in DMB. Go to http://(your-ip):3005 to see that stuff. You can restart the frontend, edit the jsons, things like that right from there. A lot of this is experimental, and honestly it's built to not need much tweaking, but you can do so there if you wish. Check the GitHub for definitions and explains of variables. https://github.com/I-am-PUID-0/DMB
-
Hello, Just to start, zurg (which uses rclone) seems to be a bit finicky in unraid. By which I mean, if a container mounts a remote WebDAV, http, etc. share using rclone (as DMB does) unraid/rclone doesn't "like" for a bunch of stuff to happen to that mount. Examples of things that I've run into issues over the last couple years with are: trying to modify the contents manually, trying to rename the mounted directory, trying to change owner or permissions of the mounted directory, trying to delete the mounted directory. Probably some others as well. If it gets really "messed up" then you'll see issues such as you described where you straight up can't remove the mounted directory except by a restart (there are other ways, but for brevity sake here, stopping the array and/or restarting is one way. "Lazy unmount" is another you can lookup if curious-- although I BELIEVE unraid has implemented this into the OS now. I might be misremembering.) Long story short, try to absolutely never mess with an rclone mount in unraid. Or if you do, just be prepared to be forced to restart the server. Regarding the cross post stuff, that's always been an origin issue in my experience. I haven't seen any errors like it in a while. Are you using a reverse proxy (like NPM, etc.) by chance? That will cause the cross post error. If you are using a reverse proxy, you should enter your https domain instead of the IP. Example: https://dmb.example.com (your subdomain would be whatever you set it to and example.com would be your domain) Besides the above scenario, I BELIEVE (and I haven't checked in many months) you can delete the origin variable and riven will still start as per normal. I think origin just sets the ONLY acceptable web address for saving to be done from. So it's less secure without that setup, but if it's local usage only... it's up to you of course but you could easily restrict access to the address anyway via firewall settings in your router and such. Or by assigning guests to a VLAN that is denied access. Anyway, I suppose I can risk borking my setup and test that "for science." I'll edit in what happens. Edit: Ok, good thing I did that! First thing, the fix: Delete or change the variable "ORIGIN" to "RIVEN_FRONTEND_ENV_ORIGIN" Everything else remains the same. Enter your origin IP as you did before. Once the container restarts, it should work! It's a mistake in the unraid template on my part. This was all updated in the last few days, so I expected a couple speed bumps. This was working previously for me, but now it wasn't after I changed my setup. Maybe I was inadvertently running a slightly older version of the docker image, who knows, anyway I will fix the unraid template. Go ahead and change that variable and let me know if there's any further issues.
-
Yeah, you are looking upon the magic of rclone and how mounting works. That file appears to be local, but it's actually remote (on RD's servers). That's how it "tricks" Plex into scanning it as if it were a localmachine or local network file, but really it isn't, then playing the video. Normally Plex doesn't support streaming from eg Google Drive, etc. It only supports playing files on local to you eg on your HDD, SSD, etc. That's the "magical" part of debrids and this project: As long as the debrid's upload speeds and your download speeds can keep up with the bitrate required for the video playback... then you can stream anything they have their servers as if it was on your server. But you only have virtual mounted drives which take up nearly zero space (minus metadata that Plex collects. which is separate anyway). As far as making a library (I will assume you mean downloading media as in actually trying to have it on your own servers so it does play locally and not streamed from real-debrid) you can absolutely use a debrid service to help with that. I just don't know the most efficient way, personally, because it's not something I have done myself. I'm sure some key word searches can bring you to guides for using it with, perhaps, the "aars" eg radaar, sonaar, etc. Again, if that's your goal. (I can't answer for you if this is your goal or not. Streaming or wanting local downloaded media "to keep" are both valid and lots of people do either or both) Ok, I'm glad to hear it. "Join discord" are two words I also dread hearing any time I find a new neat-looking project and need more info. Unfortunately, it's just the most convenient place to get help. On these forums it's basically just I who will answer any questions. On discord there's a solid dozen people who can answer technical questions, including the person writing the code
-
Hello, So just to start off I need to address one thing you wrote a few times. DMB (and Riven) aren't intended to download media per se. They stream media (which is technically downloading, but not in the way I assume you mean) from "debrid" sites eg real-debrid. Riven accomplishes this by seeking out media you request, grabbing a known-good torrent file, and adding it your WebDAV in your real-debrid account. Similar to someone sharing a video with you on Google Drive or something like that. Then the WebDAV is mounted as a directory in your system using zurg (which is basically just an optimized version of rclone for real-debrid). Next, Riven makes symlinks to that mounted directory in a second directory. (So you have two directories of media: "raw" zurg and "cleaned up" Riven). Riven basically just strips the original torrent file name down (getting rid of the trash part that torrents have. Like group names, etc.) Riven then tells Plex (or Jellyfin, etc.) to scan that symlinked directory. Plex sees new media, scans it, adds it to your library. This whole process takes... not very long. Nothing is downloaded* either. If you're looking for something to gather a large downloaded library- this won't be it. I don't really know what to suggest if that's your goal, although I know a lot of options exist. If you're looking to stream as I outlined above, then I did write a guide 5 months ago. I haven't updated it because I've been busy on other stuff (making Apple hate me, probably). But it should still hold up for the most part. Here's a link to it in my GitHub: link If you follow that and still need help, I'd suggest joining the DMB discord. The creator of it is in there and fairly active. I'd be more responsive in there as well rather than here. I only found this post by pure accident of timing that it was in my emails. In any case, if you need help, reach out again and I'll respond when I see it. I didn't look too much into your setup yet because from the way your post is written I'm not even sure this is a project you will be interested in. But if you are, I (or others potentially in the discord) would be happy to help. Many of us have had DMB running for months now. It's a fairly stable project on unRAID- although not perfect. *No media files are downloaded. However, metadata is downloaded. Sometimes this can be a lot. It's sort of a "Plex problem." People have asked them to find a way to reduce the data usage... they haven't.
-
Can you perhaps point me to what you're talking about here specifically? I wrote a lot of the explanations for things a while back and sporadically. If I made mistakes or just straight up said something wrong then I'd like to fix it to make it consistent. Is the issue just that the paths are different between, for example, a Debian/Ubuntu based OS vs unRAID (they tend to use /home/<user>/... whatever else instead of unRAID's /mnt/user...)? Or is it something else? As far as the container pathing regarding dmb -> plex goes, it's a little bit of a quirk of symlinks to my understanding. I'm definitely not that familiar with symlinks and haven't dug too much into the documentation on them, but as you were told and found to he true yes the container mount dir and host mount dir must match between two separate containers. I don't know why it matters, I just know it does. If someday I make an "unraid specific" docker image (ha! Unlikely! But maybe) perhaps I'll change those path names to not be so generic. with the quality ranking stuff (resolution, etc.) I will be 100% honest... I don't know. I messed with it a small amount one time and honestly haven't even checked into it much to see the results. I've watched like 4 episodes of one tv show in the last like 2 months. Which might raise legitimate questions about why I bother working with media docker containers all the time... who knows. But I really don't know. I changed mine to grab remux and other very high quality versions for movies. I'll look into it more at some point and play with the settings and see what might be going on.
-
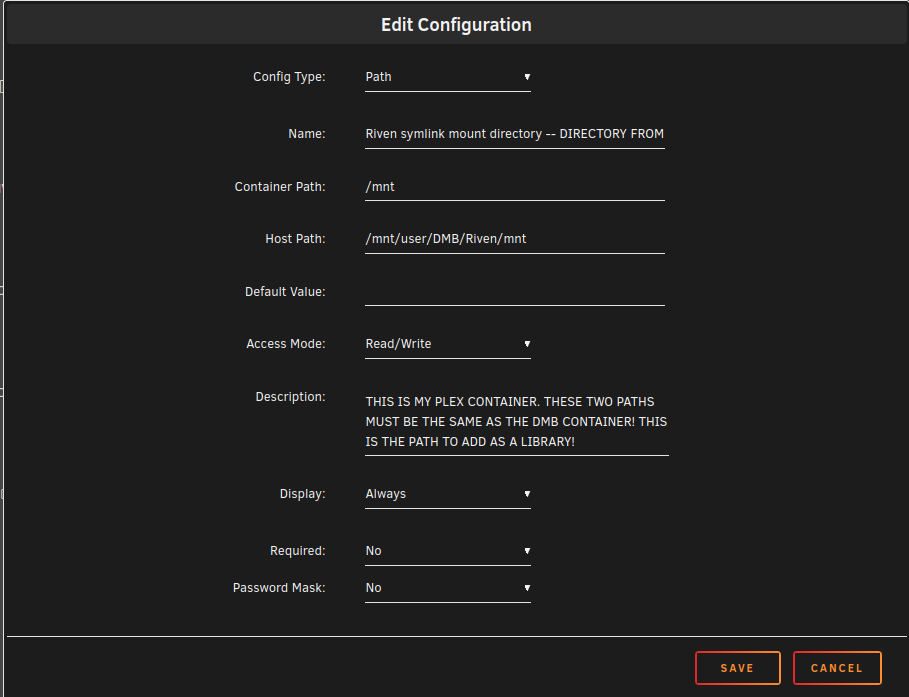
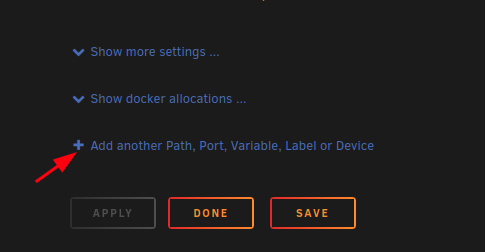
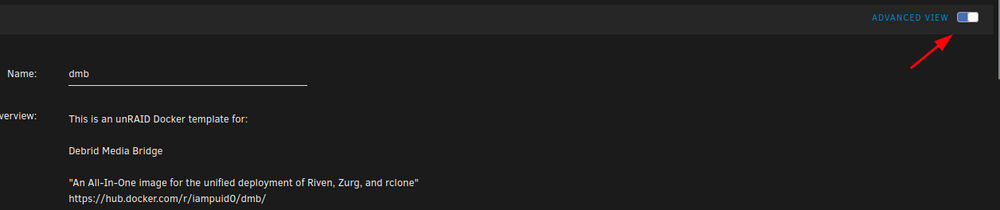
@Chamzamzoo Unless I'm misunderstanding your question here, all you have to do to add new paths/ports/variables etc is edit the template, scroll to the bottom of the webpage, and click the "Add another path... etc" button. You might need to toggle on "advanced view" at the top of the template first, I'm honestly not sure. here's some pics: advanced view toggle: add path, port, etc. (bottom of template) example what it will look like while you are creating it. in case it isn't clear, you can just name it like "riven symlink" my excessively descriptive naming is purely for the purpose of showing people... like right now! You don't need to modify those settings at all. Those are internal paths to the container. So, I would recommend never changing them or messing with them for basically any reason. You can set the corresponding host paths to whatever. But probably not a reason to change those either unless you have another container named dmb So it's important to understand what riven and zurg are intended to do in general and within the context of dmb. Riven's job is to gather together all the media the user wants to view. It gathers it from sources that include (not exhaustive list): the actual riven frontend itself (the nice little webui you've seen already it seems), trakt, plex watchlists, etc. It gathers from the sources you tell it to using the credentials you provide. It doesn't "care" what's in your real-debrid account (all the contents added from ANY source- you can view all of these, btw, on the website directly or by logging into your RD webdav. go to their site for instructions if you want to mess with that. you can delete unused or unwanted stuff that way though... just an FYI). It's only looking for relevant media that matches what it has been told to seek out. So if it isn't added on trakt, or in the riven frontend, etc. to include all the possible sources for lists of media... then it doesn't care. It ignores it. Some people enter into trying to use riven and see this as a negative because they have to import lists and stuff. I understand that viewpoint, but it's a one time thing (hopefully anyway!) and after that it's actually very nice to have a hard division between "random stuff you add to your RD" and "stuff for riven." Just imagine all the junk that could be in anyone's RD account... but it won't show up in your plex because riven ignores it. Or maybe you don't care. Either way, you gotta add media for it to search for. Zurg's job is to mount the media that riven seeks out. It's just rclone but specifically customized to work well with real-debrid's webdav and make mounting it, etc. painless So, add some stuff to riven (you can just click a movie and click add right there in the frontend for the easiest test). Check the logs. You should see it basically instantly add the movie to it's database, search, find it, add, then plex has to update. It's not an instant thing, but it's pretty quick. If you're looking for "instant" I could point you towards a project like stremio. If you're looking for "add a bunch of lists of stuff and it will be viewable quickly but necessarily instantly" then dmb can do that. more a preference type thing. Plex is also much easier to share, imo, if that's something you consider important. btw 500 server errors are basically always caused by lack of communication between riven and plex OR riven's origin IP is incorrect. it depends where and when you get the error. So, check the origin IP (set it to your unraid OS's IP http://<local-unraid-IP>). Add the other path to your plex container. restart DMB, restart plex, see what happens
-
Forgot to reply here, but I asked over in i-am-puid-0's discord the day you asked here. He said it's likely related to zilean as it's the only service within DMB that uses dotnet update he pushed today (might) fix it for you. https://github.com/I-am-PUID-0/DMB/releases/tag/5.3.1 update your container, see if the issue is fixed
-
Many possibilities here. 1. First try this command to see the owner of your directories ls -l /path/to/file For example ls -l /mnt/user/appdata/DMB and ls -l /mnt/user/DMB In my case, which is just the default I also set the container to use. Config files in the /appdata directory. Mounts, symlinks, etc. in a directory I named DMB which could be on the array or a cache or whatever. You should get something like this ls -l /mnt/user/appdata/DMB total 0 drwxr-xr-x 1 nobody users 8 Oct 8 21:11 PostgreSQL/ drwxr-xr-x 1 nobody users 8 Oct 8 21:11 Riven/ drwxr-xr-x 1 nobody users 4 Oct 8 21:11 Zurg/ drwxr-xr-x 1 nobody users 26 Oct 8 21:11 config/ drwxr-xr-x 1 nobody users 116 Oct 10 13:14 log/ ls -l /mnt/user/DMB total 0 drwxr-xr-x 1 nobody users 6 Oct 8 21:11 Riven/ drwxr-xr-x 1 nobody users 6 Oct 8 21:11 Zurg/ drwxr-xr-x 1 nobody users 18 Oct 10 16:40 transcoder-temp/ drwxr-xr-x 1 nobody users 8 Sep 23 17:47 zilean/ The key thing being the user should be "nobody" and the group "users" for all of the directories. 2. If the owner:group is correct, it's possible GitHub and/or your connection and/or a connection between you and GitHub was having issues earlier. Try manually restarting DMB and then check the log .txt file for the error. 3. If that doesn't work, try this command in unRAID terminal curl https://api.github.com/repos/debridmediamanager/zurg-testing/releases/latest It should give a huge pile of text/URLs as a reply and not any sort of connection errors. The text will contain all the links to the zurg releases. (This command isn't downloading or changing anything, btw, it's just so you can see what your server can see). If there's a connection error you'll just have to troubleshoot that. Something like DNS filter might be catching the API request. Try running the curl command in your router's terminal if you have access and can. Try it on other computers. I can tell you that the URL works for me at the moment. If you're still having issues, take a screenshot of your DMB template filled-in (redact any API keys or anything sensitive). If the container is just straight up not starting (red square) then post the docker run output. And post the logs for the latest run. Thanks.
-
The easiest way (to my mind at the moment) to have what you're saying there, is yes everyone who uses it gets their own Plex account and whatever is added to an individual Plex account's watchlist will be grabbed. Their watch history and place in the show/movie will be saved to that user. I haven't tested (yet) if using the Plex home feature (like people *in your actual home* can piggieback sort of on your Plex account) works as far as dividing up history and resuming watching, etc. Maybe it requires totally separate Plex accounts. Not sure. I'll test it at some point or find the answer if someone else did. I get busy or otherwise distracted with other projects far too often... but I am committed, if only for personal reasons at this moment, to testing and helping people debug DMB or Riven generally. So, I'll add updates here and in my unRAID templates GitHub. Try to help people use it and get what they want from it. This type of project has a ton of growth potential in my mind and I want to see it grow all the way
-
no problem. The origin issue is related to CORS and the browsers preventing cross site posting. btw if you ever reverse proxy the frontend web UI page: 1. SECURE IT (API keys can be unmasked since it's essentially running as admin for the container) 2. You can delete the origin variable. This will allow users of the proxied url (https://riven.yourdomain.tld) to save settings. This may or may not be desirable behavior, but, just letting people know for the future (it's also in the Riven Wiki) With symlinks: just make sure if DMB restarts, you *MUST* restart Plex too. DMB and Plex won't communicate until you do so. You can change and add an dependency on the DMB container being healthy. Or, what i do is just watch the DMB logs and when it says starting riven backend and frontend, I restart Plex, bam, it should be fine.


