




crescentwire
Members
-
Joined
-
Last visited
-
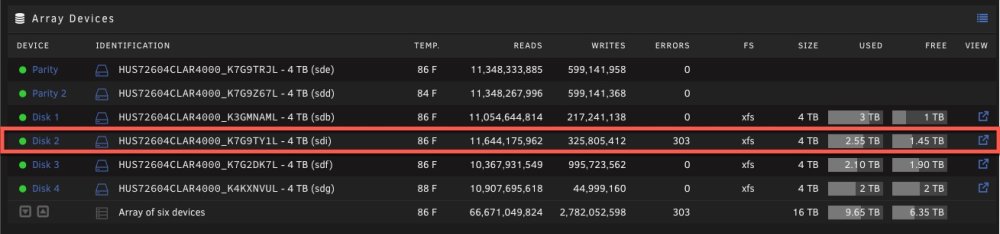
Here's what I see under Main: With that in mind, "/dev/sdi" would be correct. Would you agree? I don't have any other array disks in my server--these are all HGST 4 TB SAS drives. It sounds like I'm unable to run an extended SMART self-test with these drives. Whether that's a limitation of them being SAS or the exact make/model, I'm not sure. Are there any other options I have to assess the health of this disk, given the read errors I'm seeing?
-
Bump
-
Here's what I see running "df -h": root@ih-nas01:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 79G 1.1G 78G 2% / tmpfs 32M 1.7M 31M 6% /run /dev/sda1 7.3G 398M 6.9G 6% /boot overlay 79G 1.1G 78G 2% /lib/firmware overlay 79G 1.1G 78G 2% /lib/modules devtmpfs 8.0M 0 8.0M 0% /dev tmpfs 79G 0 79G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 39M 90M 31% /var/log tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes tmpfs 1.0M 0 1.0M 0% /mnt/addons tmpfs 1.0M 0 1.0M 0% /mnt/rootshare /dev/md1 3.7T 2.8T 932G 76% /mnt/disk1 /dev/md2 3.7T 2.4T 1.4T 64% /mnt/disk2 /dev/md3 3.7T 2.0T 1.8T 53% /mnt/disk3 /dev/md4 3.7T 1.9T 1.9T 51% /mnt/disk4 /dev/sdh1 954G 737G 217G 78% /mnt/cache shfs 15T 8.8T 5.8T 61% /mnt/user0 shfs 15T 8.8T 5.8T 61% /mnt/user /dev/loop3 1.0G 6.3M 903M 1% /etc/libvirt /dev/loop2 50G 16G 34G 33% /var/lib/docker /dev/sdi doesn't exist in this list. But, if I run it anyway, here's what I get: root@ih-nas01:~# smartctl -t long /dev/sdi smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org Long (extended) offline self test failed [unsupported field in scsi command] Sorry if this is super obvious to you and I'm just not getting it... but which device should I run the "smartctl" command on, please? "/dev/md2" represents the physical disk I'm trying to check for errors. Thanks very much for your help on this.
-
Thanks, @JorgeB, but running that command from the CLI gives me this error: root@ih-nas01:~# smartctl -t long /dev/md2 smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org /dev/md2: Unable to detect device type Please specify device type with the -d option. Use smartctl -h to get a usage summary And if I try to specify the device type (like ATA), I get this error: root@ih-nas01:~# smartctl -d ata -t long /dev/md2 smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org Read Device Identity failed: Inappropriate ioctl for device If this is a USB connected device, look at the various --device=TYPE variants A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options. I can run through every single option listed under -d, but I'd love to know if there's one I should be using in particular. (This is a Dell PowerEdge R520 server running with flashed PERC H310 RAID controller, to allow the OS direct access to each SAS drive.)
-
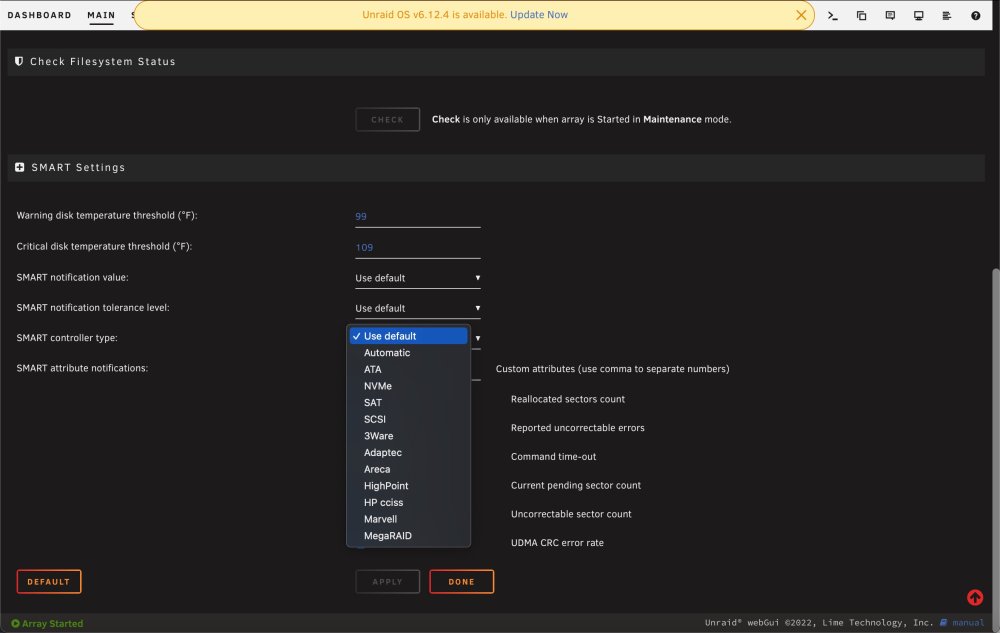
Hi @Squid, here are the settings I see in that drop-down menu: I'm running SAS disks , so I would guess I want ATA. Are there any others you'd suggest I try here? (FWIW, running that "smartctl" command with "-d ata" didn't work, so I'm hesitant to try that same option here.) Either way, it sounds like the approach would be: 1. Set the controller type and apply changes. 2. Re-run the extended self-test to see what the results are. 3. Rinse and repeat previous two steps for other controller types. Let me know if you think I should try any others. Thanks very much!
-
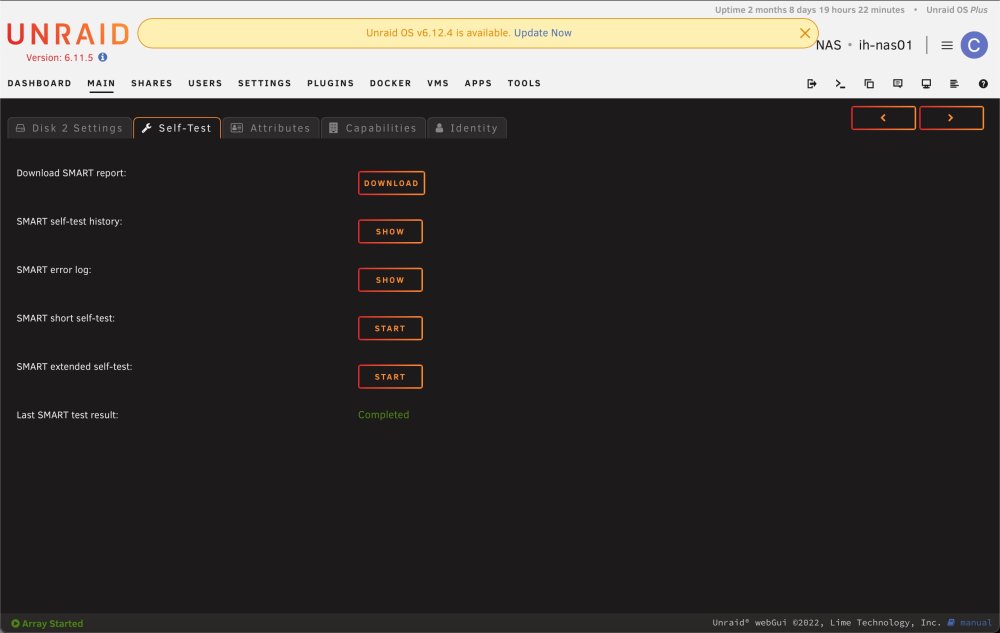
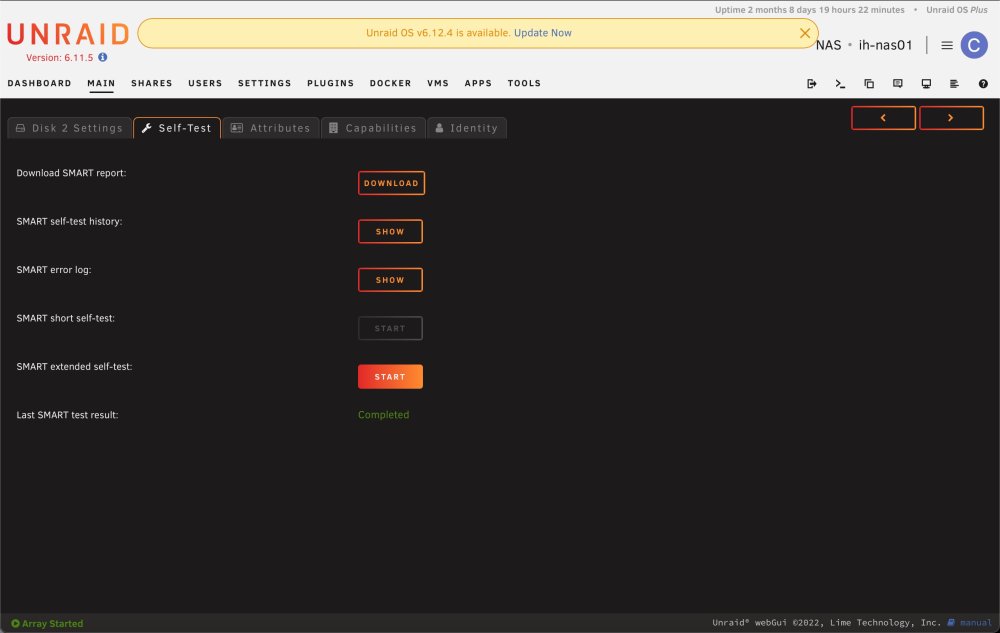
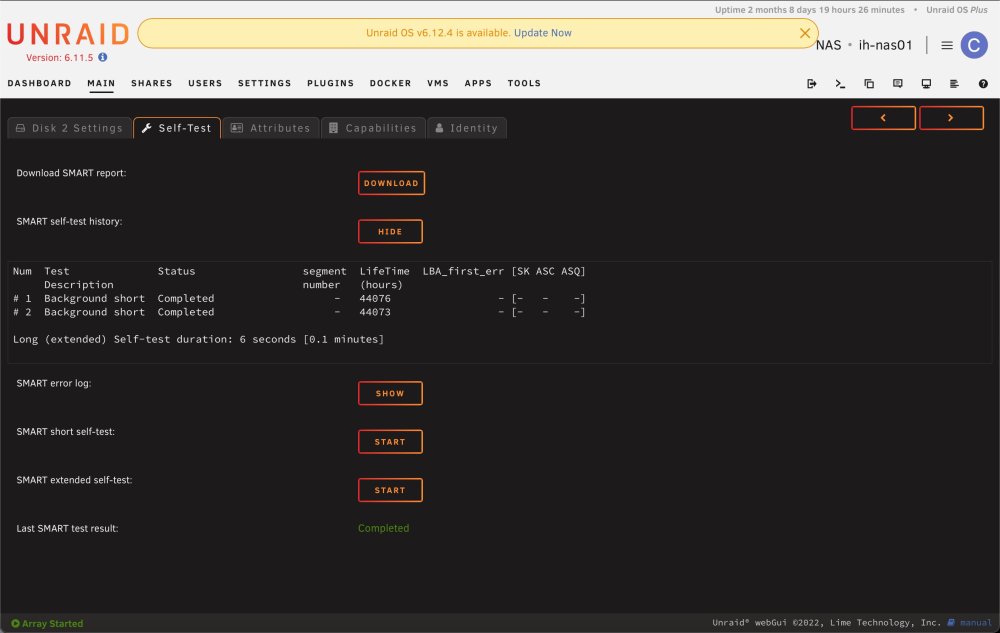
Hey everyone, I am trying to run the SMART extended self-test on a single disk in my array, but clicking the START button immediately changes it to STOP, then back to START again. It's like it's trying to start the test, fails, and then goes back to the starting position again. Disk 2 is showing some read errors, so I want to run the extended test to make sure it's not on the verge of failing I can, however, run SMART short self-tests just fine. Before clicking START: After seeing STOP briefly, then back to START: Here's the report of test results as well: If I try to run what I think is the correct command from the CLI, I get the following: root@ih-nas01:~# smartctl -d ata -tlong /dev/md2 smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org Read Device Identity failed: Inappropriate ioctl for device If this is a USB connected device, look at the various --device=TYPE variants A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options. I'm attaching the diagnostic/support bundle as well. Thank you in advance for any help you can provide! ih-nas01-diagnostics-20231009-1201.zip
-
Thank you, that seems to match with what I'm seeing. I stopped the array, unassigned sdc (the cache pool drive showing errors), but kept sdh. After starting the array, speeds are now in the hundreds of MB/s, which is exactly what I would expect to see. So, sdc is definitely a bad drive. Thank you for the help and confirmation!
-
Bump
-
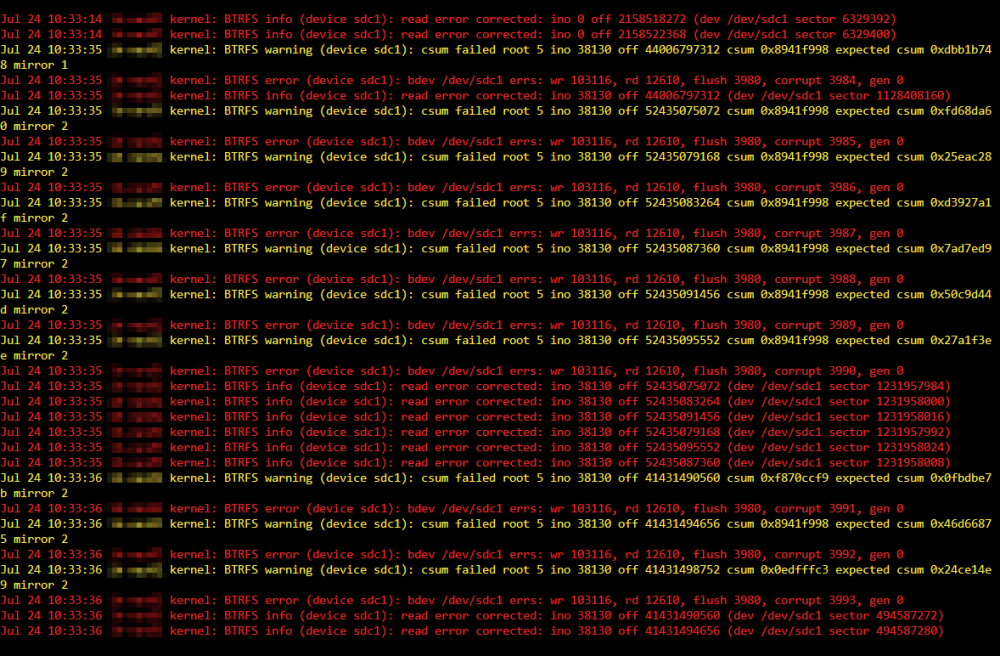
(Cross-posted to Reddit.) Hey everyone, The full story is over on Reddit, but I'll recap here: I have a Dell R520 running unRAID 6.11.5 with: 4 x 4 TB array SAS disks 2 x 4 TB parity SAS disks 2 x 1 TB SSD (SATA) cache disks 2 x Xeon E5-2450 v2 CPUs (32 cores across two physical sockets) 160 GB DDR3 memory In my mind, this setup should be plenty fast for running multiple VMs, Docker containers, and so on. This is all part of a home lab setup, so I have a Linux VM, along with a few Windows Server/Windows 10 VMs. Recently, I upgraded my cache drives from 200 GB Intel SSDs to 1 TB Micron M600 SSDs. I was previously running several VMs on my array and, while performance wasn't great, it was moderately usable. I was eager to move all my VMs on to my cache drives, alongside my Docker containers, for increased speed and room to add even more VMs. Since I've moved the VMs to my new cache drives, read/write speeds are unusably slow. I'm talking 2-3 MBps (bytes, not bits). On the Windows VMs, Task Manager reports 100% disk active time almost all the time, with response times often in the hundreds to thousands of milliseconds. That's really, really bad. If I run one VM (Linux) and try booting three other Windows VMs up, Linux slows to a crawl and almost completely stops responding. After witnessing a RedHat-based VM take 9 mins 44 secs to boot from a powered off state, I opened the logs window just for the heck of it... and saw this: I had already run a BTRFS filesystem check when the array was started in maintenance mode, but didn't see any issues. I also don't see any errors listed next to the cache pool drives: I'm in the process of moving my domains, appdata, and system shares to the array to see if performance is any better there. If it is, then I suppose I'll be replacing these SSD cache drives. Would you (like me) suspect a hardware issue (bad SSD) at this point? ih-nas01-diagnostics-20230724-1048.zip

-
Completely removing, then reinstalling the unBALANCE plugin fix the issue. Thank you!
-
That did fix it--thank you!
-
Thank you, this is very helpful. This is the exact directory I write the new certs to. If there's a cert change, does unBALANCE reload this file during startup? Or is it kept the same as long as the filename is identical? (My filename remains the same during each renewal, but the file's MD5 hash and cert fingerprint is obviously different.) Thanks very much!
-
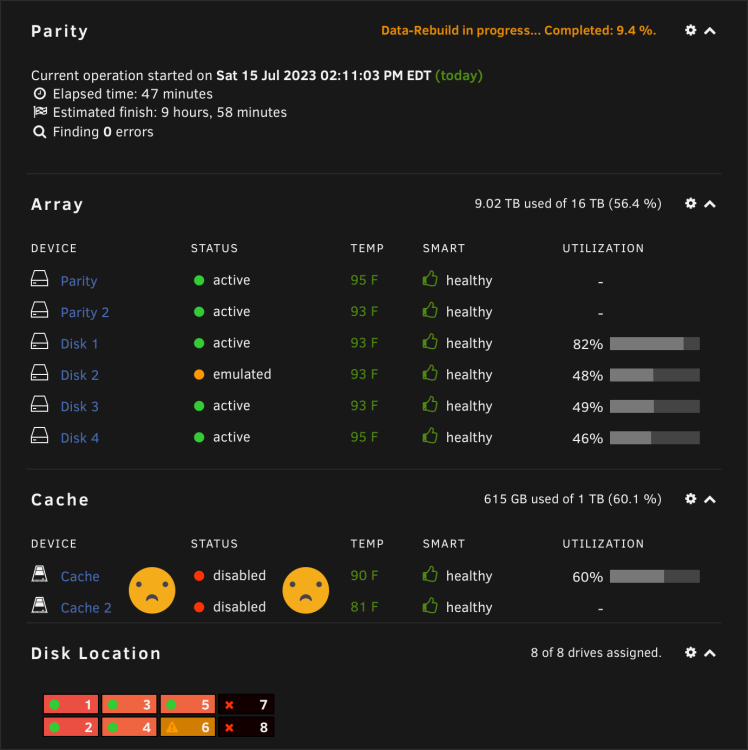
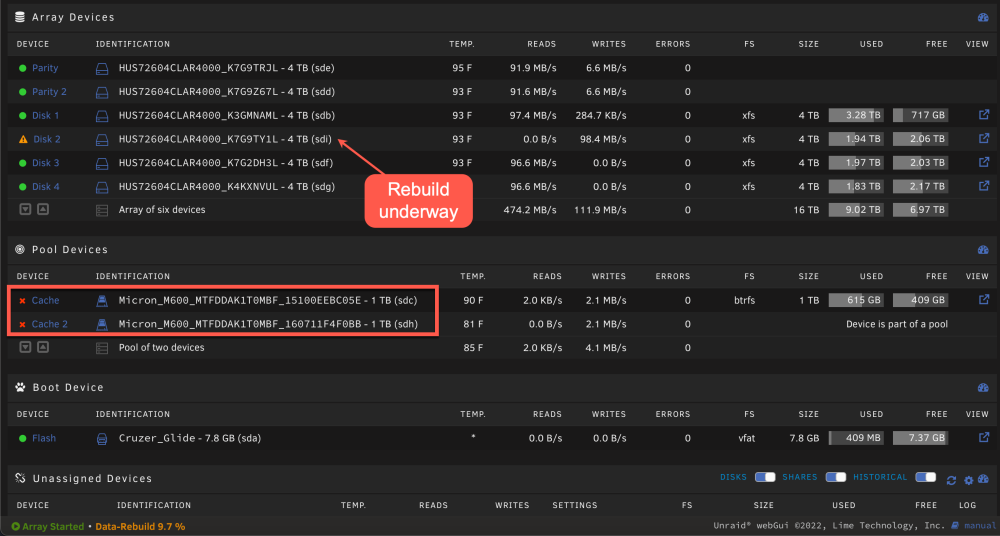
Hello friends, I'm hoping you can help me diagnose an issue I'm having with my server. I just finished pre-clearing a replacement disk and stopped the array to add it back in. (I previously physically removed the failing drive while the server was powered off, and inserted the replacement disk in the same slot.) After stopping the array to add the replacement disk, and then starting it again, I now see both my cache drives with red X's. The error "disk wrong" is listed for both, but I have no idea why. I didn't mess with their config or modify them in any way. Here's the exact error notification I received: Event: Unraid Cache 2 error Subject: Alert [IH-NAS01] - Cache 2 in error state (disk wrong) Description: Micron_M600_MTFDDAK1T0MBF_160711F4F0BB (sdh) Importance: alert Here's the full list of steps I took: 1. Realized disk 2 was failing, so began copying contents off on to disks 1, 3 and 4 in the array. 2. Was taking forever (10 MB/s), so I canceled the moves and decided to just rely on a rebuild instead. 3. Simultaneously working on upgrading my cache drives from 200 GB SSDs to 1 TB SSDs. Physically moved appdata and system to other disks on the array using unBALANCE. 4. Stopped the array, unassigned both SSDs from my cache pool, and the failing disk (disk 2). 5. Powered off the server and swapped in the replacement disk 2. Also swapped in the new 1 TB SSDs while I was at it. 6. Powered on the server and re-assigned the new 1 TB SSDs to the cache pool. Note that disk 2's data is now being emulated thanks to parity. 7. Began pre-clearing new replacement disk 2. 8. Moved appdata and system to cache pool drive. 9. Though, "hey, I have TONS of space now on cache! I can move domains there too!" (previously, domains was on array) 10. Copied domains from array to cache drive (including emulated data from disk 2, thanks to parity). 11. Pre-clear finished, and stopped array to add disk back in and begin rebuild. 12. Started array, rebuild began, and that's when I saw the error states on the cache drives. I'm wondering if you can help me figure out why I'm seeing these errors. FWIW, read/writes are still happening on these cache drives, but the status has me concerned. Can you help, please? Diagnostics and a few screenshots (below) attached. Many thanks for your help in advance! ih-nas01-diagnostics-20230715-1447.zip
-
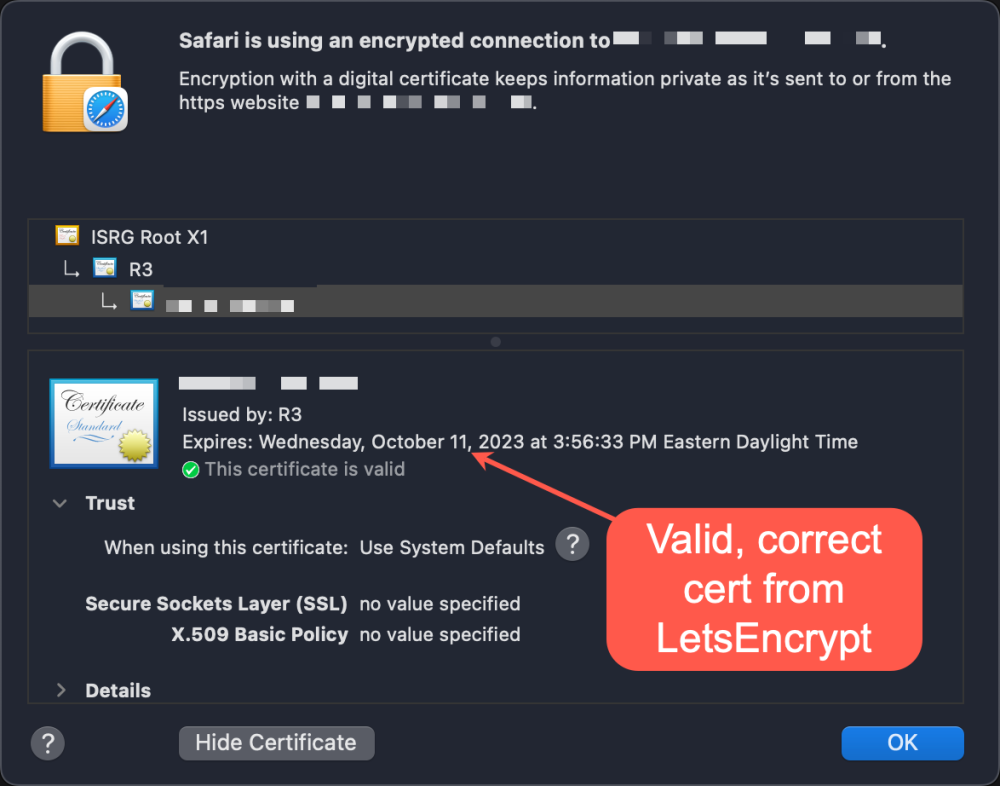
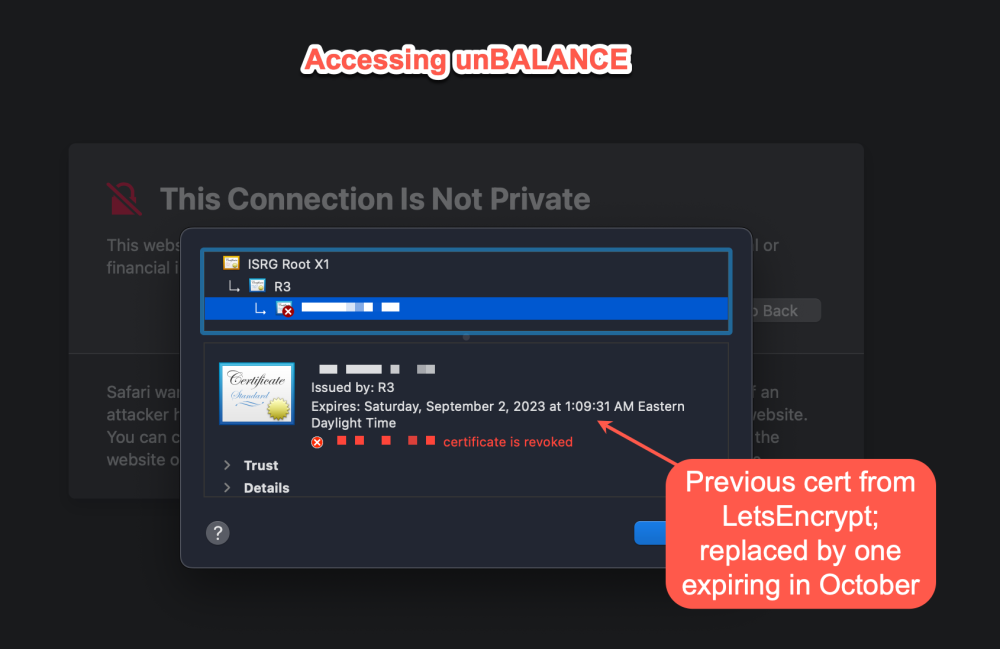
Hi @jbrodriguez, I've been using unBALANCE successfully for several weeks as I grow my disk capacity across my array. I have a certificate applied to my unRAID server using LetsEncrypt, and every so often it's renewed automatically when it approaches the expiration date. I access my unRAID server using https://my-server.my-domain.com, so when I access unBALANCE, the full URL is https://my-server.my-domain.com:6738. Recently, I renewed the certificate through LetsEncrypt. However, it seems that unBALANCE continues to use the previous cert (which is now revoked). Safari on macOS throws an error, stating this. Here's the cert details when accessing unRAID (working normally): And here's what I see when accessing unBALANCE (throws revocation error): My guess is there's a reference to the certificate that unBALANCE uses--or at least how it inherits what's already there under unRAID. Is there a directory or config file I can check to make sure I'm also updating this when I renew my cert from LetsEncrypt? Let me know if you'd like any other info. Thanks very much for your help on this in advance!
-
Thanks very much, @Squid. I'll run some hardware diagnostics to see if I can figure out which one is bad. Thanks again!











