




spall
Members
-
Joined
-
Last visited
-
So I might have solved it. I noticed my shares.ini file was showing hasCfg=similar" instead of 'yes'. I noticed my share 'docker' did not have a docker.cfg, but there was a Docker.cfg. I didn't think that should matter, but the Case-insensitive message was eating at me. I ended up backing up my docker.img, stopped the array, moved Docker.cfg to Docker.cfg.bak, and started the array. After that I have a docker.cfg and I can edit it normally. My containers seem to be working fine. EDIT: Though I wish I understood how it happened.
-
@trurl Thanks for the quick response. Tried it with no change.
-
Hey all, Unraid 7.2.4: My "docker" share wasn't showing a comment so I went to add one. I discovered I cannot modify anything on that share page. At the bottom, I see "Case-insensitive Share name is not unique". Additionally, the share is showing as residing on my Cache pool on the share page, but this is incorrect. My docker image is actually on a pool named Virtualization. I have confirmed the image exists at /mnt/virtualization/docker/docker.img and that no docker.img is on /mnt/cache. Cache is an xfs-encrypted pool of 1 devide. Virtualizaton is a zfs-encrypted pool of 2 devices. I have no idea what to do here. Any help appreciated. Thanks!
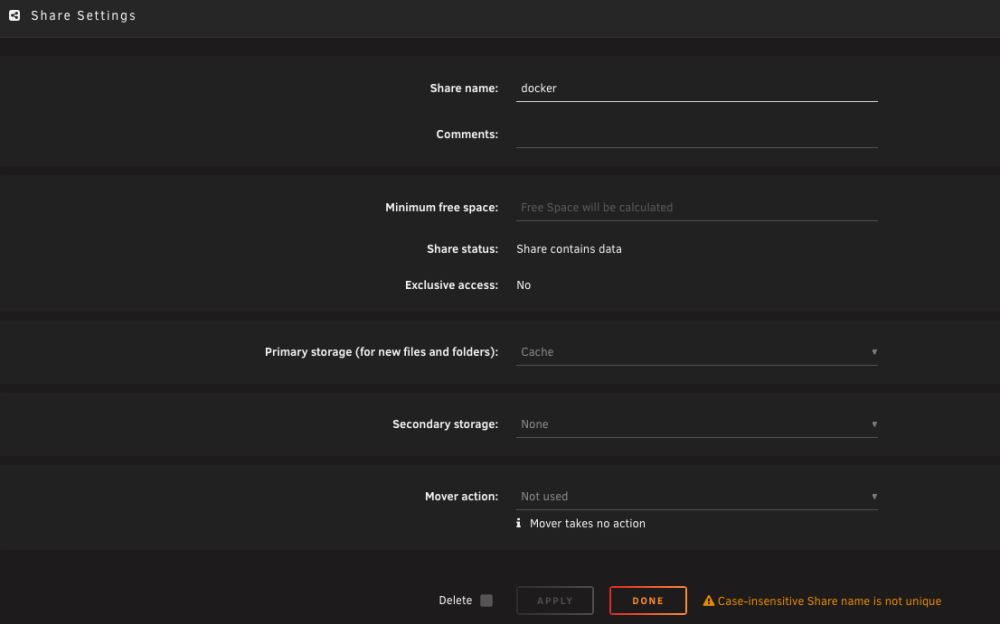

-
@JorgeB @trurl My server rack was powered down longer than I anticipated. Anyway, dual rebuild to two new drives worked like a charm. Thanks for the help! Marking as solved.
-
The second one just finished the extended test. All good on that drive, as well. I have to wrap the rack in about 30 hours. I have a feeling that would be cutting it real close if I started rebuild now, unfortunately.
-
@trurl Everything is thumps up on the dashboard including the two disabled disks. One of the disabled, disk5/sdi, has finished the extended test and is all good except for 1 UDMA CRC error which I believe was a previous error. Disk13/sdg is 90% done with the test. Unfortunately, moving is not an option for me. I have a spinal injury and cannot muscle the 4U upstairs even if I remove all the disks. I'm going to have to wrap and tarp the whole rack. Ok. Sounds like I'll probably rebuild to my spares, but I'll shut everything down when this test finishes and wait until the work is done in the basement. I'm not sure how long it will take to rebuild 2x14TB drives. Thank you.
-
@trurl @JorgeB Great. I appreciate the help. A few questions since I'm still waiting for the long S.M.A.R.T. to finish: 1) Do I unassign/reassign both drives at the same time? Or is this a rebuild one and then the other? 2) Since I keep two spares, would it make more sense to swap in the spares for the rebuilds? I'm assuming I could mount the existing drives via Unassigned Devices or in another server and still get to the data. They could become my spares after rebuild. 3) I am in the unfortunate spot of having drain tile work in my basement starting Friday morning. I don't know that I can pull of a 14TB rebuild in that amount of time. Am I better shutting the server down until the work finishes? Or can I stop/resume a rebuild? EDIT: I should add that for question 3, the basement work is going to require me tarping over and wrapping my server rack, so they need to go offline. Thanks again, guys.
-
@trurl I didn't think it relevant as the cause is known because the drives were severed from their SATA connections. I'll attach both diagnostics. One prior to taking the server down to reinsert the drives, and the other as it is now. I'm trying to figure out the proper procedure to get the array back online. The long S.M.A.R.T. tests are about 40% through at this point. As I said, I expect the drives will come back fine. Thanks! spock-diagnostics-20260421-0146.zip spock-diagnostics-20260421-2248.zip
-
Hey all, So far it hasn't happened again which makes sense since I asked for helped. Gremlins. However, I did encounter a new problem unrelated to this over at: https://forums.unraid.net/topic/198385-two-disks-disabled-need-clarification-on-proper-procedure-to-get-them-back-online/ if anyone has any helpful advice, it is much appreciate. Once I correct that issue, I'll be monitor this one to see if it pops up again. Thanks.
-
Hi all, So, briefly, I had people doing work in by basement and someone slid a table over which hit the latches on two Supermicro sleds causing the drives to slide forward enough to break their connection. Unraid 7.2.4, Supermicro 846, BPN-SAS2-846EL1, dual parity- Last night I noticed two drives with grey balls and would not spin up. Log showed the following: Syslog Once I discovered the physical issue, I shut the server down and reinserted the disks. Once coming back online the disks are disabled and being emulated. I am currently running long S.M.A.R.T. test on both drives, but I expect them to be fine. There should not have been any write options during when it happened and my discovery of the physical cause this morning. I immediately disabled Mover when I noticed the situation. However, I cannot be 100% certain. What is the proper procedure here to get the drives back online into the array? Do I stop and start the array again? Or do I unassign those drives first, start/stop, and then reassign? Will a data rebuild be necessary? I've never encountered this situation before. Any help is appreciated. Thanks for reading.
-
@Veah Yeah. I'm still waiting on that small switch I ordered to isolate the devices from the rest of my network.
-
@JorgeB That was my thought, too. I was just surprised seeing a hiccup at two different end points. Even if it was a drop at the network level, Unraid would throw something in the syslog, yeah?
-
@JorgeB Thanks for the response. I'll try and do that next time it happens. I have looked in the system log and couldn't find anything. Are there other places I could poke around and try to diagnose?
-
Hey everyone! So, I was running on standby generator power the other night and (probably coincidentally) I started having videos (Kodi connected to Unraid) just stop playing and go black. Since then it has been happening at some point while watching videos almost 100% of the time with no pattern I can detect. I was assuming it was an issue with my Kodi box, and I've been mostly trying to analyze that. However, I noticed today when sitting at my Mac that a few shares I had mounted just dropped randomly and then reappeared. It then happened again when I was moving some files around. This made me think the problem could actually be my media server and not my Kodi box. I'm trying to figure out the best starting point to see if my server is the issue. I don't think it's anything between Unraid and the Kodi box as I don't have any issues when using my AppleTV for Netflix, etc. Unless it's a specific port on the switch having issues. I do have a small switch I needed anyway on order so I can isolate the network between those two when that shows up. Obviously this is super annoying when trying to watch stuff. Any help appreciated. Thanks!
-



