




ericswpark
Members
-
Joined
-
Last visited
Everything posted by ericswpark
-
No, it occasionally does this. I will post here if I encounter the same issue on 7.2.0.
-
Hi, I was attempting the upgrade from 7.1.4 to 7.2.0 and encountered this issue while trying to stop the array, after the updater finished expanding the new image onto the flash drive. I decided to stop the array before restarting the server because I've had instances where the array didn't cleanly unmount before, and the built-in timeout caused the reboot attempt to be marked as an unclean shutdown. Sure enough, the array would not cleanly unmount today, with the "Retry unmounting disk share(s)" message printed in the lower-left corner. I checked via SSH and while the main array had already unmounted, Unraid was stuck unmounting the cache pool: Oct 31 23:58:47 dipper emhttpd: shcmd (40096042): umount /mnt/cache Oct 31 23:58:47 dipper root: umount: /mnt/cache: target is busy. Oct 31 23:58:47 dipper emhttpd: shcmd (40096042): exit status: 32 Oct 31 23:58:47 dipper emhttpd: Retry unmounting disk share(s)... Oct 31 23:58:52 dipper emhttpd: Unmounting disks... Oct 31 23:58:52 dipper emhttpd: shcmd (40096043): umount /mnt/cache Oct 31 23:58:52 dipper root: umount: /mnt/cache: target is busy. Oct 31 23:58:52 dipper emhttpd: shcmd (40096043): exit status: 32 Oct 31 23:58:52 dipper emhttpd: Retry unmounting disk share(s)... I checked what was using the cache pool, and found some processes using /etc/libvirt and not allowing the cache pool to unmount. After sending SIGTERM to all of those processes, Unraid proceeded with the rest of the array stop procedure and I was able to stop and restart the server. root@dipper:/mnt# mount | grep cache /dev/mapper/nvme0n1p1 on /mnt/cache type btrfs (rw,noatime,ssd,discard=async,space_cache=v2,subvolid=5,subvol=/) /mnt/cache/system/libvirt/libvirt.img on /etc/libvirt type btrfs (rw,noatime,ssd,discard=async,space_cache=v2,subvolid=5,subvol=/) root@dipper:/mnt# umount /etc/libvirt umount: /etc/libvirt: target is busy. root@dipper:/mnt# lsof /etc/libvirt COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME notify_po 3754678 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf session_c 3754681 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf system_te 3754683 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf device_li 3754688 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf disk_load 3754696 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf parity_li 3754700 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf sleep 3879329 root 31r REG 0,53 547 260 /etc/libvirt/libvirt.conf root@dipper:/mnt# kill 3754678 root@dipper:/mnt# kill 3754681 root@dipper:/mnt# kill 3754683 root@dipper:/mnt# kill 3754688 root@dipper:/mnt# kill 3754696 root@dipper:/mnt# kill 3754700 root@dipper:/mnt# kill 3879329 -bash: kill: (3879329) - No such process root@dipper:/mnt# lsof /etc/libvirt root@dipper:/mnt# umount /etc/libvirt root@dipper:/mnt# I was wondering if this was a known defect? Was there a reason why all of those processes were running in /etc/libvirt? I don't remember running any active VMs at the moment on my server. Attached diagnostics. dipper-diagnostics-20251031-1100-anonymized.zip
-
Thank you @JorgeB! Your diagnosis was right. It turned out that one or both of the Molex plugs had developed an unreliable connection, possibly due to me going slightly above the cable rating when the drives all spun up at once. The server is now running along with all drives restored by temporarily running with the other connectors on the same Molex cable. If anyone is interested I wrote a blog post about it here: https://ericswpark.com/blog/2025/2025-03-04-i-nearly-lost-my-entire-server/ Sorry for the late reply; I just about got everything wrapped up this morning.
-
This is sort of a continuation of this post: TL;DR - two hard drives dropped online, replaced them, same errors occurred on the new drive, rechecked connections and discovered what appeared to be a loose Molex connection. Thought the errors were now gone and jinxed myself, because now I'm posting again... Unfortunately since that post, the I/O errors came back. To eliminate more variables, I next replaced the LSI RAID card with a AS1064 4-port SATA card, and got brand new SATA cables to rule out any cabling problems. I replaced the card and SATA cables today and booted up the server and decided to run preclears on the new drives before doing anything with the array. I watched as both of the drives failed the pre-read cycle of the preclear minutes after starting the operation. Now I'm completely lost as to what to do. The only hardware that I haven't swapped out yet is the PSU and the backplane itself built into the NAS chassis. But I don't think it's the backplane because I've tried swapping around the drives and the problems follow, and if the backplane was faulty I think whatever drive was connected to that "faulty" slot would cause issues. For the PSU it's a Lian Li SFX-sized SP750 unit. It's been running fine since June 2022, and according to PSU calculators is completely overkill for this build since the recommended wattage is only at like 380W. I was wondering if anyone encountered anything like this where the software I/O errors persist despite nearly replacing all the components of the NAS. Diagnostics attached. dipper-diagnostics-20250205-0214.zip
-
I decided to take another shot at remote troubleshooting today with a different family member and we found out that one of the Molex power connections had come loose on the backplane, where it was very slightly loose that it made imperfect contact and _appeared_ to power the drives. For context, the backplane has two Molex plugs that splits off into the five disks. I'm not sure how the Jonsbo N1 has the two connectors routed on the backplane PCB, but I believe that it was trying to draw all the current from one Molex connector, and because of the voltage sag it was manifesting as disks dropping off of the array. I am not sure why or how the failures followed the two drives, but perhaps they are the most susceptible to the voltage sag? After firmly seating the Molex connectors and rechecking all connections the server was turned back on and the two new drives immediately showed up. Currently running a parity-swap procedure and it is going well now for half an hour. Previously even a simple parity check would fail after 30 seconds. Knock on wood and all that but I think this problem has been actually fixed this time. If we checked the connections properly it would've saved all the headache (not to mention the cost of the new drives... at least now I have two cold spares?) But troubleshooting remotely with family has limitations and I can't exactly tell if connections are firmly pressed in over a video call and have to take the other person's word for it. So unfortunate but glad it was resolved in the end. Thank you @JorgeB for the troubleshooting help! I've marked your initial reply as the solution because it was indeed a connection problem.
-
Just ordered a new H1110 LSI 9211-4i card with a new SAS-to-SATA breakout cable. I'm really hoping this does the trick because I'd hate for the problem to be the backplane of the case.
-
So I finally got the drives in today and connected them, but I'm _still_ somehow getting the same disk I/O errors on the brand new drives. I'm wondering now if the LSI card that I'm using has died. I'm using a LSI 9240-8i SAS card flashed into IT mode that I bought off of eBay in 2022. Should I try getting a replacement card?
-
Thanks, but are two rebuilds necessary (or recommended) as outlined in the alternate approach I laid out? Or will it cause unnecessary strain and therefore fine to just rebuild in one go?
-
Quick question regarding the rebuild process. When I get the new drives I suppose I will have to do a parity swap procedure as all the drives that I had were 8 TB, and I'm replacing a parity drive and a data drive that were both 8 TB. For parity it's a larger drive so that's fine, but I assume I'd have to move parity 2 to data 3, assign the new 16 TB drive to parity 2 and 1, and start the array. Then UnRAID will offer to copy the parity data over, zero the remaining bits, then reconstruct data 3. Is my understanding correct? Alternatively, I could assign parity 1, leave data 3 blank, rebuild, then do the parity swap procedure (parity 2 to data 3 slot, new drive in parity 2, copy parity data, rebuild data 3). This does mean I will rebuild twice, but it seems less riskier (?) since I can have another drive fail during the second rebuild if I'm understanding it correctly. Which approach should I go for? Both replacement drives are 16 TB.
-
I had a chance today to go over swapping drive slots around and believe that I've isolated the issue down to the drives. The errors followed data drive #3 and parity drive #1 shortly thereafter. I've ordered up new replacements for both. Thank you @JorgeB for the assistance. Very strange that two drives just went like that, but I'm grateful that I went with dual parity now.
-
That's good to know, thank you. So if I swap the drives around in the bay and get similar errors on the other two drives then unRAID will just stop in a safe manner? I'm planning to use maintenance mode so that no further read/writes of data occur while I troubleshoot. The main concern is having four out of five drives go out of sync, since it would be quite the headache to verify that the data is all there and correct. I do have a backup of the entire server if the array completely fails, but that would take even longer since it has to restore over Internet.
-
I've just ordered up a new cable that should arrive in a couple of days. I'll post an update once the cable is swapped and the array starts to rebuild.
-
@JorgeB the issue is the array is already in a degraded state, and the errors don't seem to show up until UnRAID tries to read/write to them. I'd much rather not risk more drives getting disabled.
-
@JorgeB I just made sure that the cables were firmly connected while reseating them. I'm using the Jonsbo N1 case that has five drive bays and a backplane that has two Molex power ports and 5 SATA connections. 1 SATA cable goes direct to MB, while the other 4 are connected via 1 SAS-to-SATA right-angle cable that is connected to an LSI RAID card in HBA mode. Unfortunately I do not know which cable goes to which HDD, but I think it's safe to guess that both failing HDDs are to the HBA card. The SAS-to-SATA cable was replaced 6 months ago with a right-angle one because I found that the straight one fails after a while because of the tight bend that the case necessitates. Even though it no longer has a bend, I'm now wondering if either the cabling or the HBA card itself is dying. Cable itself is from AliExpress since that's the only marketplace where I could find a right-angle cable. Right now I'm planning to order another SAS cable, and test the drives on another machine with something like a SMART long to make sure the drives themselves aren't faulty. Please let me know if this is a good idea (and any recommendations on better sources for good quality SAS cables...)
-
Parity just dropped offline again as well. Attaching new diagnostics: dipper-diagnostics-20250113-0630.zip
-
@JorgeB Unfortunately I spoke too soon I followed the rebuild instructions, but as soon as the sync started disk 3 dropped offline again with the exact same issue where SMART stopped reporting. The sync is currently in a paused state because of this. Is that drive toast? I can order up a replacement for it, but in the meantime am wondering whether I should resume the sync so that the parity drive is rebuilt. Attached diagnostics: dipper-diagnostics-20250113-0559.zip
-
Great, thank you so much!
-
@JorgeB my bad, I thought array start would instantly kick off the rebuild process. Here are new diags after starting the array: dipper-diagnostics-20250113-0532.zip
-
Thanks for the reply @JorgeB. I was able to reseat all connections and the server now shows SMART for all drives. Here are the new diags: dipper-diagnostics-20250113-0522.zip Am I clear to start up the array and begin the rebuild? Should I disable Docker/SMB to minimize writes to the array during the rebuild? Thanks again!
-
Bump; would appreciate any pointers on next steps as I'd like to get the array out of the degraded state as soon as possible to prevent data loss.
-
I've had some time to sit down with a laptop and properly go through the WebUI. Seems like the Parity device is back and detected -- while it is still marked as disabled I can see the SMART attributes. None of the values are different from the last time I checked, in particular the UDMA CRC error is at 0, so I'm guessing at least the connections are okay. What is more worrying is disk 3 not showing up at all. On the SMART tab it just says: "Smartctl open device/dev/sde failed". I don't know if it's because the device hasn't come back yet so the kernel hasn't assigned/re-assigned it to a drive name, or if it's actually the drive not reporting SMART. Looking through the drive logs, it seems like the two drives failed in a different way. Now I'm really lost and don't know what to do. At least I have two parity drives so I haven't lost data so far, but I'd like to know what's the safest way to proceed. Can I get away with reseating drives and checking cable connections, or is one or both drives faulty and I should replace them ASAP?
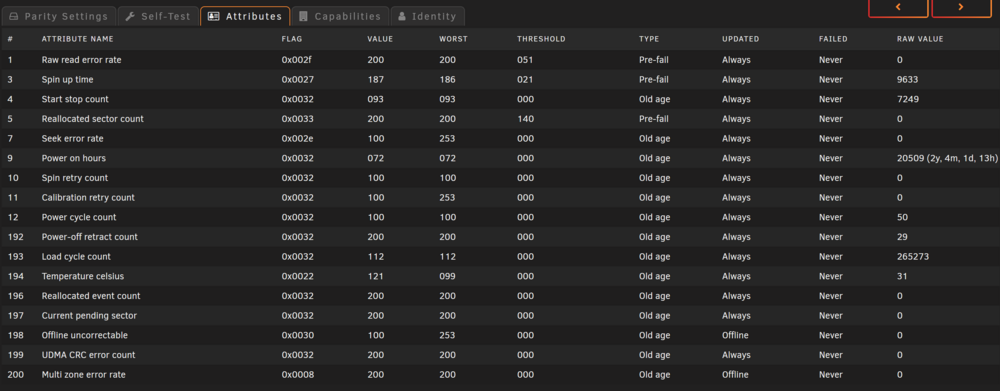
-
I got a notification stating that one of the data drives had a read error and was disabled. Not even 30 seconds had passed before I got another read failure and drive disabling, this time the parity drive. Server has been running fine since 2023, so the only hypotheses I have right now are: - Recent upgrade to stable v7 - Dusted out server a couple of days ago, perhaps one of the connections got knocked loose over time? - Or I was extremely unlucky and the drives happened to both fail. What should I do here? Making matters complicated, I currently am overseas so only have remote access/assistance with family members. Is it safe to try a reboot and see if the drives come back? Thanks. Diagnostics attached. dipper-diagnostics-20250112-1023.zip
-
I see, I thought the `unraid-r8168.plg` file was the loader for all the files within the `r8168-driver` folder. Just removed all the files you mentioned and now the server is back up fine and I can curl sites through the terminal. Thank you!
-
Same issue as @BurningSky -- updated to 6.12.14 and my WebGUI stopped showing up. Had to use KVM to remove the plugin from the plugins directory and reboot. Now the WebGUI comes up, but it is still pretty unstable. I still get the `NETDEV WATCHDOG: eth0 (r8168): transmit queue 1 timed out` messages in dmesg, and the server acts like it can't connect to the Internet -- can't curl github.com, UnRAID Connect plugin says it's offline, etc.
-
@itimpi thanks! Found the diagnostics that UnRAID saved before rebooting (attached below). Note that while the timestamp is newer, that's because the diagnostics in the OP was generated and downloaded from my browser which has an earlier time zone. This is the diagnostics captured before the one in OP. I did skim through the logs but I don't understand what it means: Dec 3 01:15:55 dipper root: rmdir: failed to remove '/mnt/user': Device or resource busy Dec 3 01:15:55 dipper emhttpd: shcmd (1343364): exit status: 1 Dec 3 01:15:55 dipper emhttpd: shcmd (1343366): rm -f /boot/config/plugins/dynamix/mover.cron Dec 3 01:15:55 dipper emhttpd: shcmd (1343367): /usr/local/sbin/update_cron Dec 3 01:15:55 dipper emhttpd: Retry unmounting user share(s)... Dec 3 01:15:58 dipper root: Status of all loop devices Dec 3 01:15:58 dipper root: /dev/loop1: [2049]:12 (/boot/previous/bzfirmware) Dec 3 01:15:58 dipper root: /dev/loop0: [2049]:10 (/boot/previous/bzmodules) Dec 3 01:15:58 dipper root: Active pids left on /mnt/* Dec 3 01:15:58 dipper root: USER PID ACCESS COMMAND Dec 3 01:15:58 dipper root: /mnt/addons: root kernel mount /mnt/addons Dec 3 01:15:58 dipper root: /mnt/cache: root kernel mount /mnt/cache Dec 3 01:15:58 dipper root: /mnt/disk1: root kernel mount /mnt/disk1 Dec 3 01:15:58 dipper root: /mnt/disk2: root kernel mount /mnt/disk2 Dec 3 01:15:58 dipper root: /mnt/disk3: root kernel mount /mnt/disk3 Dec 3 01:15:58 dipper root: /mnt/disks: root kernel mount /mnt/disks Dec 3 01:15:58 dipper root: /mnt/remotes: root kernel mount /mnt/remotes Dec 3 01:15:58 dipper root: /mnt/rootshare: root kernel mount /mnt/rootshare Dec 3 01:15:58 dipper root: /mnt/user: root kernel mount /mnt/user Dec 3 01:15:58 dipper root: root 1142 ..c.. rpcd_mdssvc Dec 3 01:15:58 dipper root: root 2998 ..c.. rpcd_mdssvc Dec 3 01:15:58 dipper root: Active pids left on /dev/md* Dec 3 01:15:58 dipper root: Generating diagnostics... Dec 3 01:16:00 dipper emhttpd: shcmd (1343368): /usr/sbin/zfs unmount -a Dec 3 01:16:00 dipper emhttpd: shcmd (1343369): umount /mnt/user Dec 3 01:16:00 dipper root: umount: /mnt/user: target is busy. Dec 3 01:16:00 dipper emhttpd: shcmd (1343369): exit status: 32 Dec 3 01:16:00 dipper emhttpd: shcmd (1343370): rmdir /mnt/user Dec 3 01:16:00 dipper root: rmdir: failed to remove '/mnt/user': Device or resource busy Dec 3 01:16:00 dipper emhttpd: shcmd (1343370): exit status: 1 Dec 3 01:16:00 dipper emhttpd: shcmd (1343372): rm -f /boot/config/plugins/dynamix/mover.cron Dec 3 01:16:00 dipper emhttpd: shcmd (1343373): /usr/local/sbin/update_cron Dec 3 01:16:00 dipper emhttpd: Retry unmounting user share(s)... I'm guessing PIDs 1142 and 2998 of the process `rpcd_mdssvc` is responsible for not allowing the unmount, but I don't know what that process is. Google says it's related to Samba, but I thought UnRAID was supposed to terminate Samba before trying unmount. Any ideas why this didn't happen here? dipper-diagnostics-20231203-0115.zip

