




obuwunkunubi
Members
-
Joined
-
Last visited
-
Since the "Balance" button isn't greyed out and I am not seeing any balance progress I'm assuming that it isn't running. Thanks for the help and suggestions! I'll take a look at the monitoring script.
-
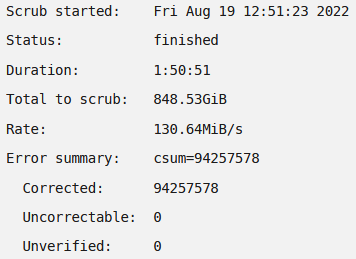
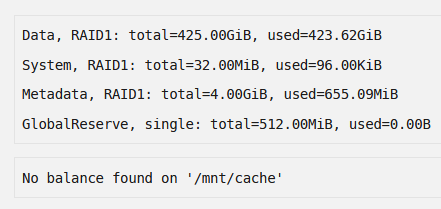
Thanks, that seems to have worked! There were no uncorrectable errors and there were no I/O errors in the logs. There are also no errors in the logs when trying to open a file. Do I have to take any further steps regarding my cache pool or can I use it normally now? It still says "No balance found on '/mnt/cache'", is that an issue or is it supposed to be like that?
-
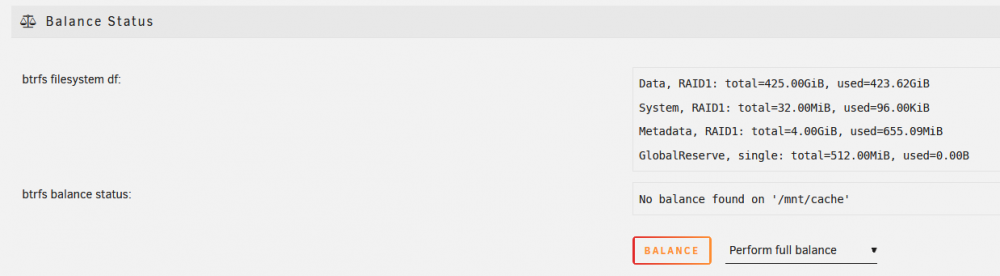
Thanks for the suggestion, I have tried both now. Things such as smart info are still showing for now but my log is still filled with errors of the following two types (in the code box below (sdc is the new drive that has been giving me issues)) whenever I try to access a file that is stored on the cache. The file still opens and plays normally otherwise. Aug 19 11:23:06 Serverina kernel: BTRFS error (device sdb1): bad tree block start, want 1271081533440 have 0 Aug 19 11:23:06 Serverina kernel: BTRFS error (device sdb1): bad tree block start, want 1271081549824 have 0 Aug 19 11:23:12 Serverina kernel: BTRFS info (device sdb1): read error corrected: ino 0 off 1270182952960 (dev /dev/sdc1 sector 944117472) Aug 19 11:23:12 Serverina kernel: BTRFS info (device sdb1): read error corrected: ino 0 off 1270182957056 (dev /dev/sdc1 sector 944117480) So should I try to run another scrub to repair the errors? I have also noticed that it says "No balance found on '/mnt/cache'". Is that also an issue? Should I be performing another balance?
-
Hello, so today I decided to add a drive to my cache pool. It was going normally until the drive temperature randomly stopped showing. But the balance seemed to keep on going. The problem is that after it finished the mover wasn't working. So I decided to shut down the system and try another SATA cable. The temperature and smart details started showing again after starting up again but I decided to run a btrfs scrub to check for errors. It was correcting what seemed like every single sector until it started showing I/O errors (for the new disk) in the logs and subsequently uncorrectable sectors, so I stopped the scrub. It seems that I can still access the files on the pool since the first drive seems to be working normally. The new drive has since stopped showing smart info and temperature again. Is there a way to fix these issues? Is it a problem with the drive, since it doesn't seem to be the SATA cable? In that case can I remove the new drive and only keep the original while I wait for a replacement? Otherwise I have made an appdata backup before doing this and I also backed up some of the more important files before doing this. But I would still like to keep everything if possible (even though they are mostly torrents which I can re-download) I have attached my diagnostics file below. (Sadly I forgot to save one before shutting the system down to switch the SATA cable, so this is just the new one) serverina-diagnostics-20220818-2150.zip
-
I recently changed it to the LSI HBA SATA port, so I'm guessing that's why I wasn't seeing any errors regarding this before. Thanks for the info, I'll change it back asap. Thanks, I'll keep that in mind next time I'm adding a drive.
-
Sadly I forgot that that was an option while the disk was in the array, even though that's the way I did it last time. Thanks for the confirmation! I thought that was the case, but I just wanted to make sure. Do you by chance also have any advice regarding the BTRFS trim warning/error at the end? Aug 11 23:05:28 Serverina kernel: blk_update_request: critical target error, dev sdb, sector 976773120 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Aug 11 23:05:28 Serverina kernel: BTRFS warning (device sdb1): failed to trim 1 device(s), last error -121 I noticed it for the first time then, but it seems to be showing up daily (at the time my Dynamix SSD TRIM plugin is set to run). Since the issue seems to be regarding the plugin, I guess that I should ask in the Dynamix Plugins thread.
-
Hello, so a couple of days ago I tried adding a new drive to my array. So just like the previous times I did so, I ran 2 cycles of preclear and everything seemed fie with the drive. #################################################################################################### # Unraid Server Preclear of disk XXXXXXXX # # Cycle 2 of 2, partition start on sector 64. # # # # Step 1 of 5 - Pre-read verification: [6:38:01 @ 167 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [6:38:53 @ 167 MB/s] SUCCESS # # Step 3 of 5 - Writing Unraid's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying Unraid's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: [6:38:04 @ 167 MB/s] SUCCESS # # # # # # # #################################################################################################### # Cycle elapsed time: 19:55:01 | Total elapsed time: 39:50:13 # #################################################################################################### #################################################################################################### # S.M.A.R.T. Status (device type: default) # # # # ATTRIBUTE INITIAL CYCLE 1 CYCLE 2 STATUS # # Reallocated_Sector_Ct 0 0 0 - # # Power_On_Hours 0 20 40 Up 40 # # End-to-End_Error 0 0 0 - # # Reported_Uncorrect 0 0 0 - # # Airflow_Temperature_Cel 27 32 31 Up 4 # # Current_Pending_Sector 0 0 0 - # # Offline_Uncorrectable 0 0 0 - # # UDMA_CRC_Error_Count 0 0 0 - # # # #################################################################################################### # # #################################################################################################### --> ATTENTION: Please take a look into the SMART report above for drive health issues. --> RESULT: Preclear Finished Successfully!. After that, I spun down my array and added the new disk. After restarting the array I got the "Unmountable: Unsupported partition layout" error shown next to the drive, so I wanted to stop the array but after waiting for 20 minutes it still hadn't stopped, so I tried using the shutdown button in the GUI and the server shut down. After starting back up I don't remember if I tried formatting the drive again and then starting the array or just starting it. But when it started, I noticed that it had detected an unclean shutdown so it started a parity check with the "Unmountable: Unsupported partition layout" drive in the array and it started showing (and correcting sync errors). Aug 10 14:35:37 Serverina kernel: md: recovery thread: check P Q ... Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=0 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=8 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=16 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=24 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=32 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=40 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=48 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=56 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=64 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=128 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=136 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=144 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=152 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=160 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=168 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=176 Aug 10 14:35:37 Serverina kernel: md: recovery thread: PQ corrected, sector=184 So I panicked and quickly stopped it. After that I used the format unmountable drives in array option which formatted the drive properly this time and it was successfully added into the array. After seeing the previous errors I started another parity check which resulted in 28 errors being corrected: Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509272 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509280 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509288 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509296 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509304 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509312 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509320 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509328 Aug 10 17:10:05 Serverina kernel: md: recovery thread: PQ corrected, sector=1953509336 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018544 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018552 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018560 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018568 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018576 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018584 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018592 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018600 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018608 Aug 10 19:16:51 Serverina kernel: md: recovery thread: PQ corrected, sector=3907018616 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527816 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527824 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527832 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527840 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527848 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527856 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527864 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527872 Aug 10 21:46:07 Serverina kernel: md: recovery thread: PQ corrected, sector=5860527880 So after reading some other posts regarding parity I ran another parity check the next day, just to make sure there was no issues with the hardware and it found no errors. My main question is, should I be worried about any data loss? Or have any of my files potentially been damaged? As far as I can see, everything seems to be running fine now, but I would just like to make sure. I have attached my two diagnostics files (the older one contains the parity checks that found errors and the second one is the one where I ran the second parity check the next day (there was a reboot in between)) Also slightly unrelated: When looking at the parity errors I found the following regarding my cache drive in the logs Aug 10 23:05:21 Serverina kernel: blk_update_request: critical target error, dev sdb, sector 976773120 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Aug 10 23:05:21 Serverina kernel: BTRFS warning (device sdb1): failed to trim 1 device(s), last error -121 Should I be worried about this? I am currently running only a single cache drive, but I was planing on adding a second one of the same capacity which should be arriving next week. serverina-diagnostics-20220811-0118.zip serverina-diagnostics-20220812-1409.zip





