




Alpha.Ars
Members
-
Joined
-
Last visited
Everything posted by Alpha.Ars
-
I'll look into that, thanks I did not find any container with this id nor name, I do have some minecraft servers running.
-
I got the server out of memory error, I saw this a few times already but never looked into it. I do have more than enough memory and never saw it peeked higher than 50%. arialis-diagnostics-20240206-0745.zip
-
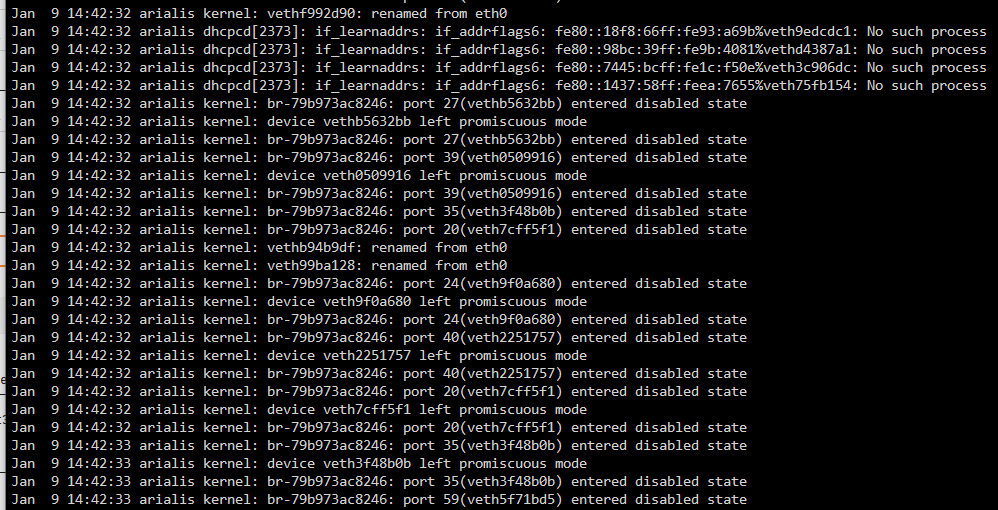
I'm a little lost I noticed one of my docker containers was causing the issue, and ... I think I fixed it but I'm not sure. I still have the issue, Is there any way to know what containers are causing the problem ? I'm not sure what I'm supposed to look into or what I should do. This is still getting spammed: And I'm not sure this would lead to anything but when I use the 'dhcpcd' command it shows info, and like 15 sec later the server just goes down and or is not reachable anymore.
-
Yep the containers are indeed the problem here, pterodactyl includes ipv6 now, I'm looking how to disable this
-
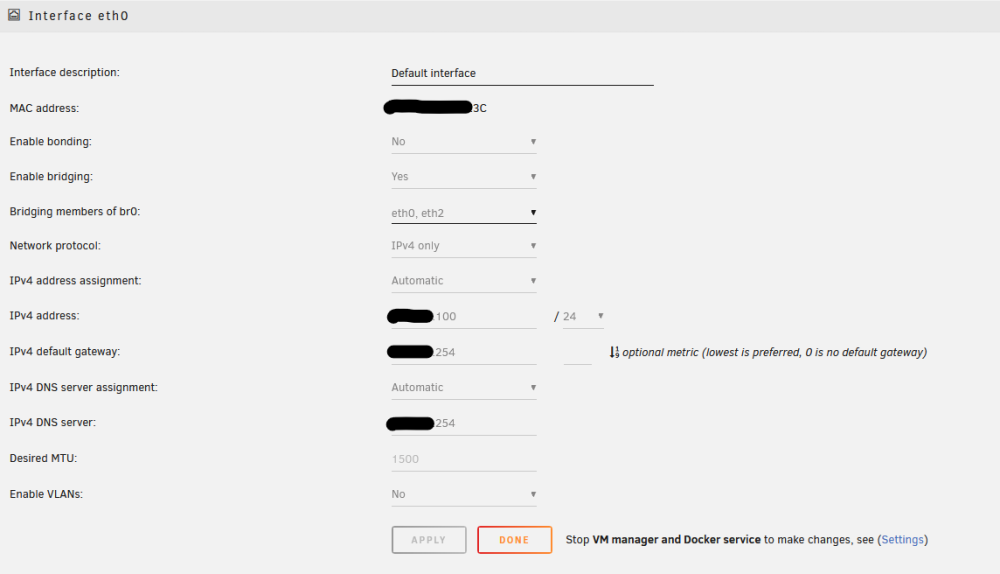
I'm indeed not using it, where can I disable it? I can't find a setting to edit that here: Settings > NetworkSettings I do have this selected:

-
I tweaked some network stuff, I tried a reboot and I'll see how it does. It cleared everything which is normal so I'll just have to wait and see I guess
-
The Fix Common Problems Plugin gave me a warning telling me that "/var/log is getting full (currently 51 % used)" I looked a little into it and found this log in dhcplog repeating over and over: Dec 28 17:48:57 [2443]: drained 279 messages Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: ::1%lo: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::50e4:f2ff:feb8:107c%veth001d396: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::6c11:c8ff:fe1a:d02c%veth26918b6: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::d8d2:16ff:fe92:c18e%vethe860eb7: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::58ad:8dff:fe94:2e44%veth69741e8: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::d805:2aff:feed:6cf7%veth1a751b8: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::c85f:baff:fefb:a625%veth0432f54: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::64a7:a8ff:fe01:bb8f%veth0da4f36: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::b46a:48ff:fe91:4b8%veth45a127b: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::9031:b9ff:fe58:c0a8%veth748ff88: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::78eb:76ff:fe52:9348%veth28898b4: No such process Dec 28 17:48:57 [2322]: if_learnaddrs: if_addrflags6: fe80::280e:6cff:fe8a:6f17%veth854f2bb: No such process Dec 28 17:48:57 [2322]: route socket overflowed (rcvbuflen 106496) - learning interface state I don't know exactly why this is, but it might be because I configured my SFP+ port recently and I might not have done it correctly. I tried first plugging in only my SFP+ port, but then my server had no connection. So, I plugged my Ethernet cable back in and then I had a connection again. I watched the video by Spaceinvador One where he configures a 1 gig port and a 10 gig port separately, which I'm not the biggest fan of. I would rather just have one IP pointing to my server and access everything through it. So, after tinkering a bit, I found this configuration that achieved what I wanted. It's been working fine until now, but it might be causing some issues. This is the config: eth0 is the 1gig port And eth2 is the 10gig connection arialis-diagnostics-20240108-1035.zip

-
Hi, sadly I did not find a way to do that. I looked a little online and only found people saying it was not possible because of the kernel version or something like that. So the way I worked arround it is using a vpn docker container, (or a torrent installer + vpn docker container) and setting the network for the other containers to point to the vpn container. At first I did not want to go this way but this is the easiest way.
-
I got the out of memory error with the 'Fix Common Problems' plugin. At first sight this seems really weird because I'm far from my max memory use. Is there anything I can do to fix that? arialis-diagnostics-20230718-1717.zip
-
Hey did you find anything to make it work ? I'm in exactly the same situation
-
I have a setup where I have a network leading to my main external ip being on br0 and trough a vlan a secondary extrenal network that I will use for some apps (being br0.1200) NETWORK ID NAME DRIVER SCOPE 1921e1b644da br0 ipvlan local d89713dz571b br0.1200 ipvlan local I made a custom network using: docker create network my-custom-network Which work and the data exists trough ip on br0 But no I want to create a new custom network that will exit all the data trough the vlan on br0.1200 I tried several commands with (-o parent=br0.1200) but it did not work. What I aim to have is that the container port being on a subnet and the host ip to be the ip that br0.1200 get. (I think the correct term is bridged)
-
I see some mistakes, you've indicated a network that you're not using. I've send you a dm to give you further help.
-
A restart fixed it.
-
Its not always super obvious and the steps are a little weird so follow the documentation really well (use the same file path's). If you have any question or problem I'm here to help you, I installed this one several times and know how to fix most of the problems with it.
-
Mine is running perfectly directly on unraid If you're interesed there is a great post to guide you: https://docs.ibracorp.io/pterodactyl-docker-1/ (but I do sugest to follow the written version and not the video) as for the error, I think it might be related to a firewall blocking the port on the vm, I'll look a bit into it
-
Is there any reason you are using it in a vm and not directly on unraid docker system ?
-
I removed the posts I made about the location of the files, because those were not your problem att all. I just misinterpreted the error.
-
Usually this means one of your running docker services allready uses the 25565 port. It can be another minecraft server or any app you run on the same vm
-
I was setting up a debian VM, while doing that I had to go away for some time. When I came back I noticed the vnc got disconnected tried to reconnect but it wasn't working, and I wasn't able to get on the vm page. I disables/enabled tha vm manager and then I got the "Libvirt Service failed to start". Those are the logs: 2023-01-21 15:03:15.122+0000: 14279: warning : qemuDomainObjTaintMsg:6602 : Domain id=2 name='Home Assistant' uuid=f1aed52f-1a57-fc99-ce68-5b3bcb4c7bcb is tainted: custom-ga-command 2023-01-21 15:03:15.353+0000: 14278: error : qemuDomainAgentAvailable:8610 : Guest agent is not responding: QEMU guest agent is not connected 2023-01-21 15:03:15.441+0000: 14278: error : qemuDomainAgentAvailable:8610 : Guest agent is not responding: QEMU guest agent is not connected ---- lot's of repeating the same thing... (that isn't a log) --- 2023-01-21 16:57:24.469+0000: 44507: warning : qemuDomainObjBeginJobInternal:909 : Cannot start job (modify, none, none) in API remoteDispatchDomainShutdown for domain Dynmap webserver; current job is (query, none, none) owned by (14279 remoteDispatchDomainGetBlockInfo, 0 <null>, 0 <null> (flags=0x0)) for (749s, 0s, 0s) 2023-01-21 16:57:24.469+0000: 44507: error : qemuDomainObjBeginJobInternal:944 : Timed out during operation: cannot acquire state change lock (held by monitor=remoteDispatchDomainGetBlockInfo) 2023-01-21 16:58:19.749+0000: 51164: error : qemuMonitorIORead:440 : Unable to read from monitor: Connection reset by peer arialis-mserver-diagnostics-20230121-1829.zip
-
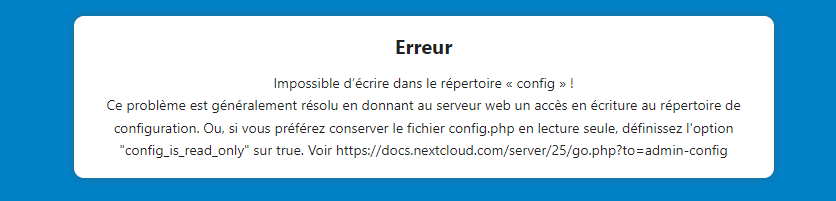
I'm realy struggeling with the permissions for the Nextcloud cron. Can't run with the nextcloud basic config. When I run this command "docker exec -u root nextcloud chown -R 33:users * " the cron works... but then I'm unable to access nextcloud Unable to write to the "config" directory! This problem is usually solved by giving the web server write access to the configuration directory. Or, if you prefer to keep the config.php file read-only, set the "config_is_read_only" option to true. See https://docs.nextcloud.com/server/25/go.php?to=admin-config when I run: "docker exec -u root nextcloud chown -R 99:users * " I do have access on nextcloud but the script can't access (just like in the begining) I was able to fix it once in the past but then I had no access to the nextcloud appstore. Do you have any hint ?

-
Label: none uuid: a6dcc4fb-21bc-4244-9872-dc35d278e2f1 Total devices 2 FS bytes used 166.30GiB devid 1 size 232.88GiB used 176.02GiB path /dev/sdf1 *** Some devices missing array is stropped and this is the situation right now:
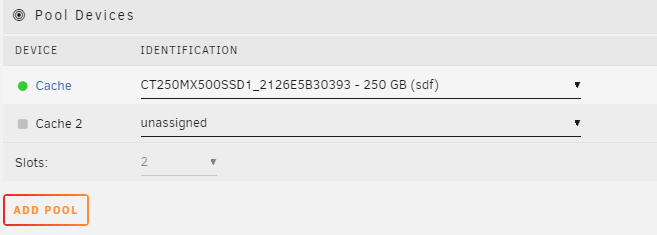
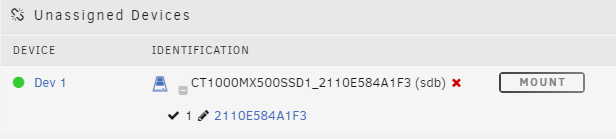
-
Yes I did. I got confused with a text I read before posting my question.
-
Sorry, I did not see I got a reply. I went for an old backup I had laying somewhere and thought is was good enough. Thanks for your help!
-
When trying to add a new caching drive I did not look it up at first. There was my first mistake. I just added a second pool, lauched the array, stopped it again and added my drive into the empty pool. Then I noticed I had one 900 or so GB of space on my cache. I stopped the array and removed the drive from the cache and started it again thinking it would somehow revert to normal. (it did not) Now my cache is in following state: and I do not know how to fix it. I do still have the drive I added and removed (non formatted nor touched) and I rebooted to safe mode. So to be clear I would like to go back and have my cache being only the sdf drive and I will follow a tutorial to replace it with de sdb drive since I found plenty of documentation. arialis-mserver-diagnostics-20221219-2130.zip


-
docker exec -u root nextcloud chown -R 33:users * was the correct command. Thanks for you help!












