




halexh
Members
-
Joined
-
Last visited
-
For the past ~6 months or so, occasionally all my docker containers stop working. I go to the system log and see this. Its resolved by hard resetting the computer, at which point everything works as it did for some indeterminate amount of time. Sometimes its a few days, sometimes its weeks. Seems to be happening more often lately. Just wondering if there is anything in the logs above that might indicate what the problem is. Just FYI, nvme0n1p1 is the only SSD I have in the cache pool. I do monthly parity checks on my array, and currently have 0 errors. Thanks!
-
One of the recent updates to Unraid updated the kernel version, causing this error to appear (more on that in a second). I am running a Intel 12600k, utilizing Quicksync for hardware encoding within Jellyfin. Up until recently, this was working fine for transcoding 4k down to any other resolution. With a recent update to Unraid, this is now broken. See this jellyfin github conversation for more information on the details of the issue, as well as the likely cause. I am currently on the latest stable release of unraid, 6.12.8 (linux kernel 6.1.74) and the issue still appears. I dont expect a resolution to come from this post, but an acknowledgement or agreement that it is something related to the kernel version Unraid is running (or perhaps custom modifications Unraid made to that kernel) would be nice. Also posting this for awareness in case other Jellyfin users of Unraid have this issue.
-
Trying to run the mover to move things off the cache drive on to the array, but I am constantly getting "No space left on device" as seen here in the system log Oct 1 17:17:46 UnraidServer shfs: copy_file: /mnt/cache/data/cameras/recordings/2023-09-25/05/Doorbell/55.32.mp4 /mnt/disk1/data/cameras/recordings/2023-09-25/05/Doorbell/55.32.mp4.partial (28) No space left on device I guess while on vacation my cache drive filled up with security camera recordings. Before leaving Disk 1 was at ~13.5 TB capacity and Disk 2 was ready to be used. But why isnt the mover copying anything to Disk 2? Here is a photo of the share in which the mover is operating on:
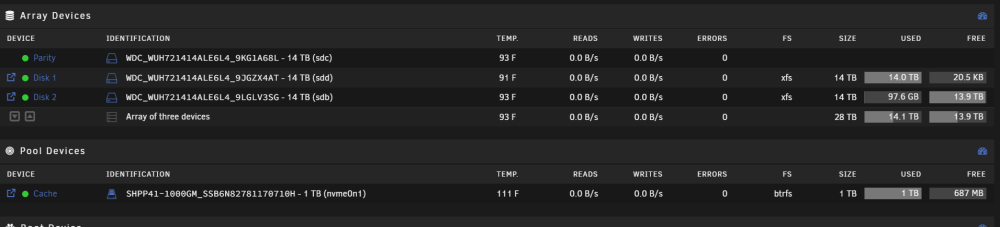
-
-
Thank you for that. I was about to ask, well isn't it going to spend the next 12+ hours rebuilding the new drive without the ability to read from it? Reduced performance is fine with me. I'm assuming I will also be able to write to the array while this new drive is being rebuilt?
-
I have two drives in my array. One is a parity drive, and the other drive is going bad, but still very much usable and technically healthy according to unraid. Is it possible to replace the bad drive with a third, brand new drive without taking the array offline while I essentially clone (somehow) the bad drive's contents onto the new drive? All drives are the exact same size / model. While the array is still online, I imagine new things will be written to the bad drive, which would require potentially running this cloning process (whatever that may be), multiple times, in order to get all of the data to the brand new drive. Thanks
-
I have a 14 TB HDD that recently started showing Current_Pending_Sector errors. At that point, was not running a parity drive, and that was the only hard drive in my system. I had a second identical drive, and made it the parity drive. That finished successfully (took about 2 days). At that point it mentioned there were parity errors and that I needed to do a parity check, which I did. That also finished successfully and took around the same time. I documented that in this post. After that I ran a short SMART test and surprisingly, it passed, which you can see in the attached SMART report Since Monday (7/17/23), I have been running an extended smart self test and its been sitting at 90% complete. As I understand it, the actual checking of each sector of the disk doesnt happen until 90%, so that should rightfully take the longest. But I am approaching 4 days here, and not sure if its actually going to complete, or if there is even an issue. So far, there are no errors at all in my system log, since starting this extended smart test. Its also sort of confusing to me that the disk in question lists a number for the "Errors" column when viewing it on the Main Page under Array Devices, yet its still considered healthy? WDC_WUH721414ALE6L4_9JHDH26T-20230721-0939.txt
-
Yep, I will. I figured in the mean time it would be advantageous to add disk 2 as a parity disk though, right? Wonder how I would replace disk 1 in the future though
-
I just decided to turn Disk 2 into the parity drive, and left disk 1 as is. Its currently in the process of creating the parity disk (~1 day total to complete)
-
Attached is the downloaded smart report. When I attempt to run a extended SMART report, I get the following: Kind of surprised to be honest, as this drive only has ~181 days of power on lifetime. Heres the bad part: I never decided to setup a parity drive. Disk 2 is identical to disk 1, and is basically empty (not sure what that 102 GB is tbh). What is the best way to move forward to insure I dont lose all my data? WDC_WUH721414ALE6L4_9JHDH26T-20230715-0852.txt

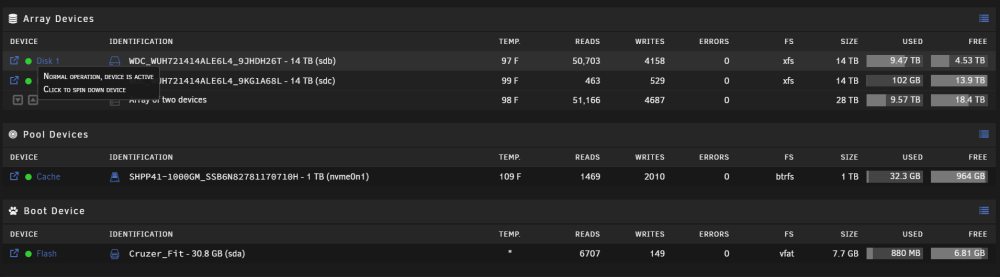
-
I have some potential issues that I am looking for confirmation/resolution on. The first is whether or not I setup my jellyfin container to correctly utilize Quicksync. Within the docker section for jellyfin, when I first configured all of this months ago, for some reason I added both of these lines to the extra parameters section. --device /dev/dri/renderD128:/dev/dri/renderD128 --device /dev/dri/card0:/dev/dri/card0 Looking back at the instructions for linuxserver.io's version of this jellyfin container, it seems only --device=/dev/dri:/dev/dri should be included, as described in the Hardware Acceleration section of https://github.com/linuxserver/docker-jellyfin Restarting the container to pass in the entire /dev/dri folder, then starting something in jellyfin that requires transcoding for the client, running intel_gpu_top within a console of the unraid host pc results in something similar to the following: intel-gpu-top: Intel Alderlake_s (Gen12) @ /dev/dri/card0 - 1257/1443 MHz; 0% RC6; 2.92/45.62 W; 19769 irqs/s ENGINES BUSY MI_SEMA MI_WAIT Render/3D 71.84% |█████████████████████████████████████████████████████████████████████████▍ | 0% 0% Blitter 0.00% | | 0% 0% Video 25.13% |█████████████████████████▊ | 0% 0% VideoEnhance 0.00% | | 0% 0% PID NAME Render/3D Blitter Video VideoEnhance 19689 ffmpeg |█████████████████▊ || ||█████▋ || | They key part that had me worried that I set it up incorrectly is the fact that it lists /dev/dri/card0 instead of /dev/dri/renderD128. I would imagine renderD128 should be listed here, because thats what Jellyfin is utilizing to transcode. If I go to the logs of jellyfin, the ffmpeg command to transcode the content looks like this: [2023-07-08 10:33:07.636 -04:00] [INF] [16] Jellyfin.Api.Helpers.TranscodingJobHelper: "/usr/lib/jellyfin-ffmpeg/ffmpeg" "-analyzeduration 200M -init_hw_device vaapi=va:,driver=iHD,kernel_driver=i915 -init_hw_device qsv=qs@va -filter_hw_device qs -hwaccel qsv -hwaccel_output_format qsv -c:v h264_qsv -autorotate 0 -i file:<redacted> -autoscale 0 -map_metadata -1 -map_chapters -1 -threads 0 -map 0:0 -map 0:1 -map -0:s -codec:v:0 h264_qsv -preset 7 -look_ahead 0 -b:v 292000 -maxrate 292000 -bufsize 584000 -profile:v:0 high -level 41 -g:v:0 72 -keyint_min:v:0 72 -vf \"setparams=color_primaries=bt709:color_trc=bt709:colorspace=bt709,scale_qsv=w=426:h=284:format=nv12\" -codec:a:0 libfdk_aac -ac 2 -ab 128000 -af \"volume=2\" -copyts -avoid_negative_ts disabled -max_muxing_queue_size 2048 -f hls -max_delay 5000000 -hls_time 3 -hls_segment_type mpegts -start_number 0 -hls_segment_filename \"/config/data/transcodes/af3ec090ed41953b9acce436bf7903c3%d.ts\" -hls_playlist_type vod -hls_list_size 0 -y \"/config/data/transcodes/af3ec090ed41953b9acce436bf7903c3.m3u8\"" I am assuming that the inclusion of confirms that it is indeed utilizing quicksync? Still curious why intel_gpu_top lists /dev/dri/card0 though. For the second issue, I am trying to understand exactly what is happening with the following. I have 4k content, and if I decide to say set the quality in jellyfin to something ridiculous, like 4k @ 120Mbps the cpu struggles, resulting in big slow downs on playback, especially after seeking. I noticed a pattern that during the slowdowns, intel_gpu_top will look like this: intel-gpu-top: Intel Alderlake_s (Gen12) @ /dev/dri/card0 - 1246/1446 MHz; 0% RC6; 1.08/19.48 W; 0 irqs/s ENGINES BUSY MI_SEMA MI_WAIT Render/3D 0.00% | | 0% 0% Blitter 0.00% | | 0% 0% Video 50.00% |███████████████████████████████████████████████████▏ | 50% 0% VideoEnhance 0.00% | | 0% 0% PID NAME Render/3D Blitter Video VideoEnhance 24614 ffmpeg | || ||██████████████▉ || | The video portion is just capped at 50%, during the entirety of the playback being paused due to not transcoding quick enough. According to jellyfin, this Video section represens the QSV decoder/encoder workload, as described in Jellyfin's documentation here: https://jellyfin.org/docs/general/administration/hardware-acceleration/intel/#verify-on-linux Any ideas why it would be capped at 50% and utilizing 100%? Lastly, shouldnt I expect the VideoEnhance section to be utilized somewhat? My Jellyfin playback seciton looks like this: Motherboard: ASUS TUF GAMING Z690PLUS WF D4 CPU: Intel i5-12600k Thanks!
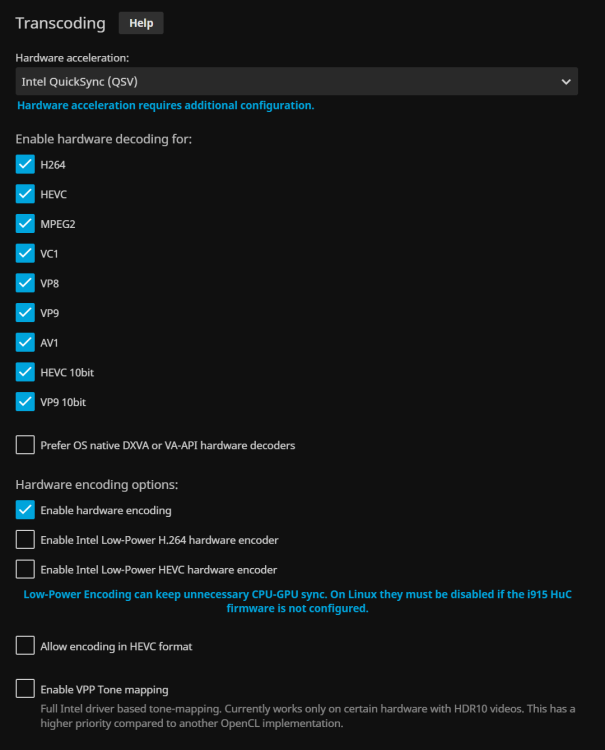
-
Its going into a power saving state, causing a write/read failure? Just curious on your thinking as to how that could be the issue
-
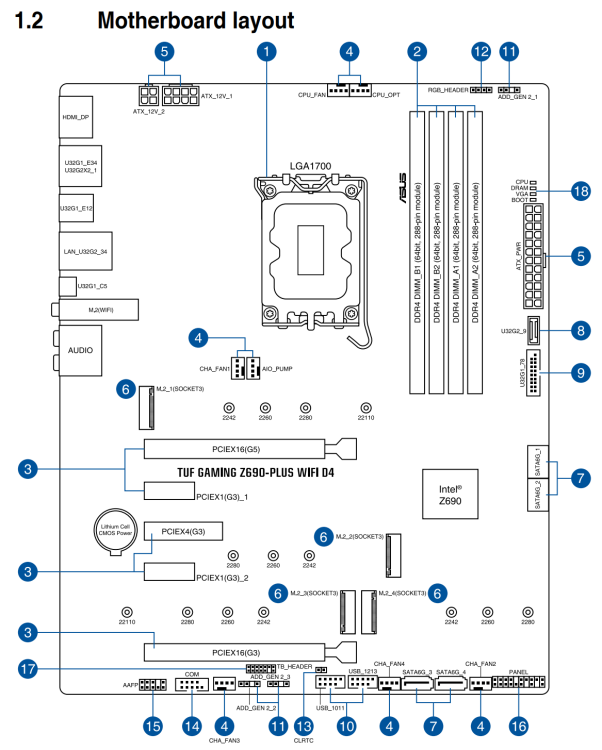
I have had my unraid server running for about 2 months now, and this has happened once in the past. The solution then was just to restart and everything was fine. Now that it has happened again, I am more concerned. root@UnraidServer:~# btrfs device stats /mnt/cache/ [/dev/nvme0n1p1].write_io_errs 1 [/dev/nvme0n1p1].read_io_errs 1046565 [/dev/nvme0n1p1].flush_io_errs 1 [/dev/nvme0n1p1].corruption_errs 0 [/dev/nvme0n1p1].generation_errs 0 This issue manifests itself through the fact that almost all of my containers become unresponsive, no longer function, and then will not restart/start. In the container's logs, I get errors like these: grep: (standard input): I/O error /usr/bin/wg-quick: line 50: read: read error: 0: I/O error Sonarr failed to start: AppFolder /config is not writable The nvme in question is a SK hynix Platinum P41 1TB. It is installed in the M.2_1 slot, as seen in the image below (taken from my TUF GAMING Z690-PLUS WIFI D4 manual): I have attached my system log / diagnostics zip file. As you can see, there is no SMART log for the nvme in question. I rebooted the server, and then attached it. Again, everything is back to normal now that I have rebooted. The syslog.txt is no longer being flooded with BTRFS error (device nvme0n1p1: state EA): bdev /dev/nvme0n1p1 errs: wr 1, rd 519402, flush 1, corrupt 0, gen 0 like it is in the attached syslog.txt (within the diagnostics zip file), and all my containers are running again without issue. After rebooting, I did a scrub on the nvme drive: UUID: 7579a732-bdd9-4dac-b182-f01dbb08f3c7 Scrub started: Tue Feb 21 08:19:52 2023 Status: finished Duration: 0:00:32 Total to scrub: 143.52GiB Rate: 4.48GiB/s Error summary: no errors found and reran this: root@UnraidServer:~# btrfs device stats /mnt/cache/ [/dev/nvme0n1p1].write_io_errs 0 [/dev/nvme0n1p1].read_io_errs 0 [/dev/nvme0n1p1].flush_io_errs 0 [/dev/nvme0n1p1].corruption_errs 0 [/dev/nvme0n1p1].generation_errs 0 I feel like in another week or so, this issue is going to pop up again. Any ideas on what I can do to resolve this so I don't get these errors anymore? Thanks unraidserver-diagnostics-20230221-0720.zip SHPP41-1000GM_SSB6N82781170710H-20230221-0812.txt
-
Yea I am restarting qBittorrent container each time I rebuild gluetun. Tried it again with the firewall set to false. Still having the same results as before. For comparison, I went and setup binhex's delugevpn container, and that worked like a charm on the exact same torrent. Both gluetun and delugevpn claim they are up and running, and the results of curl -sd port=<Port Mullvad Provided> https://canyouseeme.org | grep -o 'Success\|Error' are successful on both containers. Wish I could get gluetun working though - seems better, and I like that I can use it with any torrent client. I also have a Nordvpn account, and I initially setup the nordlynx container with qbittorrent. When I run that, it works quite well, and I dont get the same firewalled icon. I figured obtaining a VPN that was capable of port forwarding would improve things further, so I gave Mullvad a try, which led me to Gluetun.
-
In this case, <listening port from qBittorrent> is the same value as <Port Mullvad Provided>. I believe that is what you would expect, right? In any case, I still get the same results - one connection and the icon implying I am firewalled.





