




Kwakx
Members
-
Joined
-
Last visited
Everything posted by Kwakx
-
After some time, I finally got some error from the pool. Feb 10 03:06:21 HomeLAB kernel: ata1.00: exception Emask 0x0 SAct 0x400 SErr 0x50000 action 0x6 frozen Feb 10 03:06:21 HomeLAB kernel: ata1: SError: { PHYRdyChg CommWake } Feb 10 03:06:21 HomeLAB kernel: ata1.00: failed command: WRITE FPDMA QUEUED Feb 10 03:06:21 HomeLAB kernel: ata1.00: cmd 61/38:50:40:18:18/02:00:07:00:00/40 tag 10 ncq dma 290816 out Feb 10 03:06:21 HomeLAB kernel: res 40/00:01:00:4f:c2/00:00:00:00:00/00 Emask 0x4 (timeout) Feb 10 03:06:21 HomeLAB kernel: ata1.00: status: { DRDY } Feb 10 03:06:21 HomeLAB kernel: ata1: hard resetting link Feb 10 03:06:22 HomeLAB kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 10 03:06:22 HomeLAB kernel: ata1.00: configured for UDMA/133 Feb 10 03:06:22 HomeLAB kernel: ata1: EH complete Feb 12 09:44:00 HomeLAB kernel: ata1.00: exception Emask 0x0 SAct 0x20 SErr 0x50000 action 0x6 frozen Feb 12 09:44:00 HomeLAB kernel: ata1: SError: { PHYRdyChg CommWake } Feb 12 09:44:00 HomeLAB kernel: ata1.00: failed command: WRITE FPDMA QUEUED Feb 12 09:44:00 HomeLAB kernel: ata1.00: cmd 61/58:28:68:cb:b0/02:00:11:00:00/40 tag 5 ncq dma 307200 out Feb 12 09:44:00 HomeLAB kernel: res 40/00:01:01:4f:c2/00:00:00:00:00/00 Emask 0x4 (timeout) Feb 12 09:44:00 HomeLAB kernel: ata1.00: status: { DRDY } Feb 12 09:44:00 HomeLAB kernel: ata1: hard resetting link Feb 12 09:44:00 HomeLAB kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 12 09:44:00 HomeLAB kernel: ata1.00: configured for UDMA/133 Feb 12 09:44:00 HomeLAB kernel: ata1: EH complete "UDMA CRC error count" so I corrected the cables and the problem has not occurred since. However, this does not explain the dependency to all of UnRAID and the inaccessibility of the GUI. Is this some kind of bug?

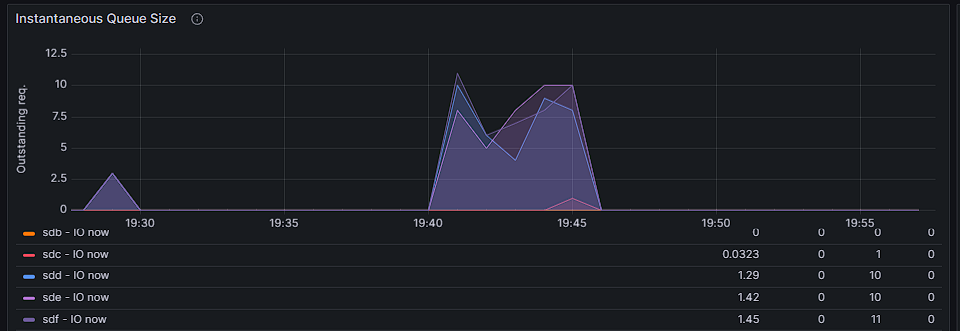
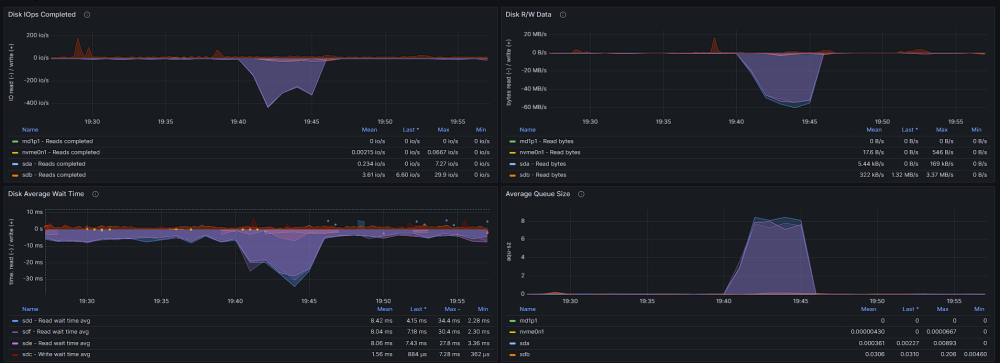
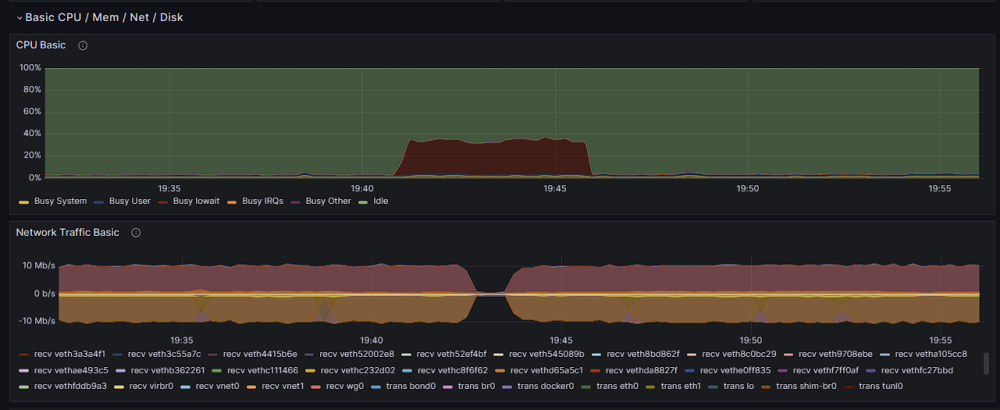
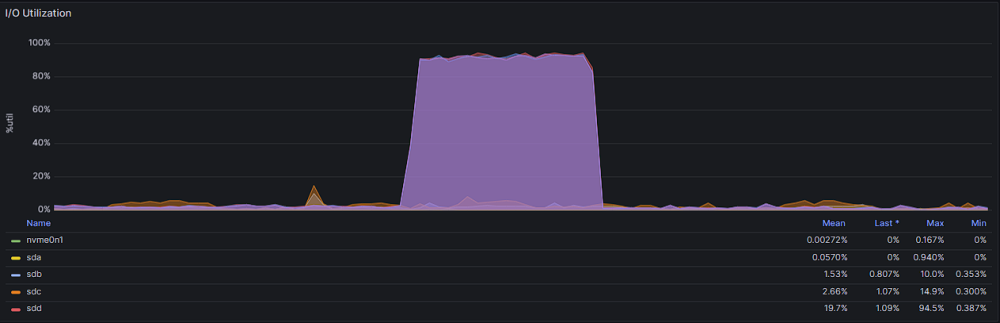
-
BUMP, still happens on a daily basis
-
today it happened again but for literally a few seconds and the gui was unavailable at the time:
-
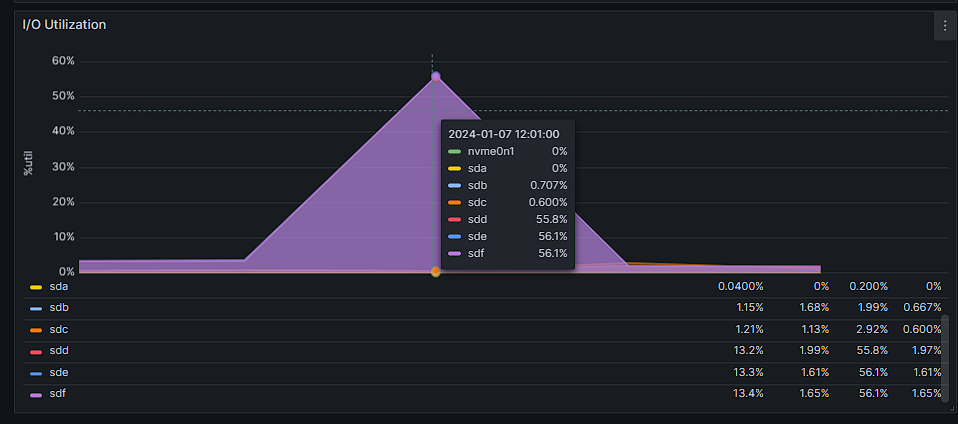
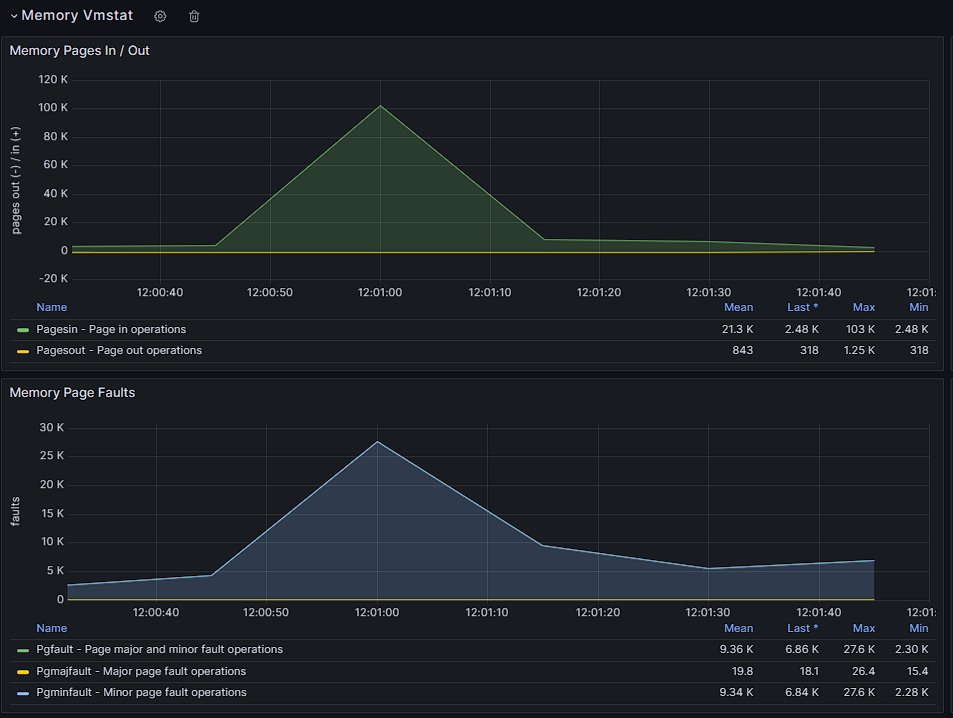
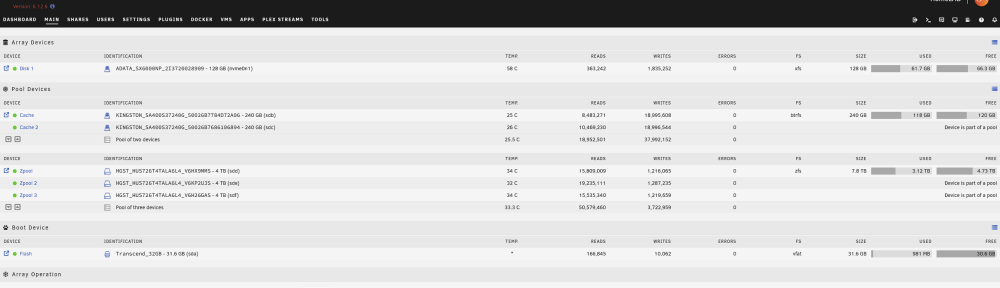
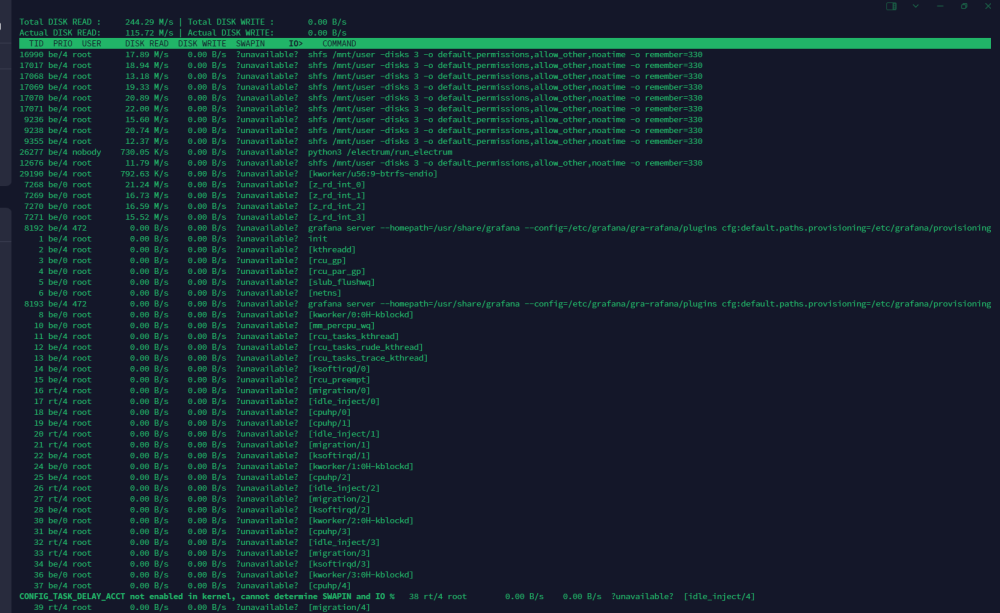
Every now and then i hear that my hdd drives on ZFS "zpool" are working at 100% and when i want to check in gui what is going on i find that it is not available as well as any docker container. My configuration looks like this: Disk1 (nvme): VM's space Cache pool (2x sata ssd) : docker + docker volumes Zpool (3x hdd): media for plex, nextcloud data and backups At this time ssh is working so I took ss of iotop: I do not know what causes such a large pool consumption at random moments, but it certainly should not affect the operation of the entire unraid and docker. CPU usage at this time is at a maximum of 20%. Monitoring data and here you can see that only hdd sdd, sde, sdf drives are used. here you can see when the gui stops being available: Anybody have an idea what could be the reason for such unavailability and zpool usage? [EDIT] I found this: https://github.com/openzfs/spl/issues/276 But I have scrub set to cycle weekly on Tuesday 1:50 and the data above is from 05/01/2024 19:40 and the problem occurs at random times. pool: zpool state: ONLINE scan: scrub repaired 0B in 02:47:37 with 0 errors on Tue Jan 2 04:37:39 2024 config: NAME STATE READ WRITE CKSUM zpool ONLINE 0 0 0 raidz1-0 ONLINE 0 0 0 /dev/sdd1 ONLINE 0 0 0 /dev/sde1 ONLINE 0 0 0 /dev/sdf1 ONLINE 0 0 0 errors: No known data errors And zpool history: 2023-12-12.01:50:04 zpool scrub zpool 2023-12-19.01:50:03 zpool scrub zpool 2023-12-19.22:21:17 zpool import -N -o autoexpand=on -d /dev/sdd1 -d /dev/sde1 -d /dev/sdf1 7285799706976465626 zpool 2023-12-19.22:21:17 zfs set mountpoint=/mnt/zpool zpool 2023-12-19.22:21:17 zfs set atime=off zpool 2023-12-19.22:21:17 zpool set autotrim=on zpool 2023-12-19.22:21:17 zfs set compression=on zpool 2023-12-26.01:50:04 zpool scrub zpool 2024-01-02.01:50:04 zpool scrub zpool [EDIT2] homelab-diagnostics-20240106-1208.zip
-
Since the rc3 version, after restarting I get an alert: "VM Autostart disabled due to vfio-bind error", on rc4.1 is the same. On rc2, nothing like that happens homelab-diagnostics-20230430-2344.zip
-
This has happened to me twice. The first time during the first boot after upgrading to 6.12.0-rc2 and today the second time during a normal reboot. During the process the system is not responding and i have to force reboot again to boot, I tried the keyboard but nothing. It was naver a case before update. homelab-diagnostics-20230401-1428.zip
-
- Get rid of "array" and "pool", make one consistent with a choice of type and file system - Get rid of the requirement of one device in the "array", it just wastes licenses in my case - Make a real cache e.g. for ZFS, wants to make use of my one nvme drive without compromising data











