




muxelmann
Members
-
Joined
-
Last visited
Everything posted by muxelmann
-
A quick follow-up: I kept getting errors despite my efforts of updating the disks' firmwares and disabling EPC using the Seagate tool discussed on a separate thread, but with no luck. After swapping my HBA for a LSI 9300-8i and now everything seems to work fine. If I had read the forum more thoroughly, I could have saved myself a lot of trouble.
-
Bezüglich der Netzwerkprobleme, da habe ich mit dem e1000 unter Windows 11 grade Erfolg gehabt. Denn das Setup konnte so fortgesetzt werden ohne zusätzlich Treiber installieren zu müssen. Ich denke mal, dass man dann unter Windows selbst wieder auf virtio oder virtio-net zurück wechseln kann, falls nötig. Aber falls es mit e1000 weiter stabil läuft, lasse ich es vielleicht lieber so.
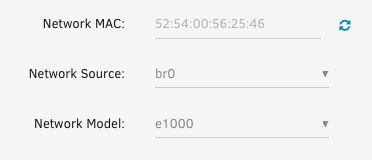
-
I am using a flashed Fujitsu D2607-A21 and I guess it's behaving like a SAS2008 (please correct me if I'm wrong). Anyway, I also had issues with Seagate drives and was made aware of this thread (my original submission here). Long story short: I originally considered the issue to be insufficient cooling of the D2607 SAS-card. After channeling airflow and reducing data load by plugging more disks directly into the mainboard than the SAS-card, it subjectively seems that disk failures became fewer. In any case, I also followed the instructions to disable EPC. It was enabled for four drives, three of which failed before when rebuilding the failed drives. So maybe that was the actual fix to my issue. I also noted that for two of my EPC-disabled drives there is a new firmware available from Seagate (link - use e.g., S.N. ZA217TFG). So it may also be worth trying updating the firmware instead/in addition to disabling EPC.
-
Thanks for the reference to the different thread. I did check with `SeaChest_Info_x86_64_xxx` and it turns out four of my drives have EPC enabled. It's now been disabled. I also discovered that two of my drives are running firmware version SC60, yet there is SC61 available for download from the Seagate website (link) (e.g., search for Serial Number: ZA217TFG). The card is installed in a 2U server case, into which I installed a bodged airflow channel (made from cardboard) such that air flows across the heatsink from two fans. That should keep it cool and prevent failure. I also reduced the number of disks connected to the D2607 to four (the remaining six are connected to the mainboard). Maybe this is no longer necessary with EPC disabled, but if it works in either case, I'm happy. So far, the array has been running with no issues. Thanks for the help!
-
Thanks for the quick reply. I only once updated firmware on a drive, so I have very little experience therewith. In any case, I checked for the two drives in question on the Seagate website (link). According to their SMART entry "Power on hours", they appear to be less than two month old only. And the website (as expected) does not show any updates. Also thanks for the information regarding 9300-8i cards! Due to the unraid hardware compatibility page, it was my assumption that the flashed Fujitsu D2607 is a good (and cheap!) choice. But I will now keep an eye out for a different card. In the meantime, I swapped the connections of the two troubling disks from the SAS card to the mainboard. I must admit, after editing my original post regarding cache, I realized there are unused SATA ports on the mainboard left. So my thinking is, if the SAS card cannot handle high load without overheating, maybe I can distribute the load? I will report back on whether this re-distribution of drives (appears to have) changed anything. Worst comes to worst, I will replace the SAS card...
-
Greetings from Bavaria! I started building and running an unraid server about 1 to 2 months ago and noticed that one of two drives keep failing whenever a parity check is started. Specifically, drives 3 and/or 4 show errors in the Main menu, and become disabled/emulated. I checked the SAS to SATA connections several times and even replaced the hard drives, but had no luck so far. Moreover, it appears that irrespective of which drive I plug into the drive's physical tray/slot it it is likely to fail. The strange thing is, that whenever I rebuild a failed disk (i.e., by following this procedure: stop array > deselect e.g., disk 4 > start array in maintenance > stop array > select disk 4 again > start array) the disk rebuilds completely fine and without any errors for several hours (17h for a 10 TB disk). Yet only minutes after starting a parity check, disk 3 or 4 fails. Hence my guess that the HBA PCIe card that is connected to the 8 drives is overheating due to the heavy load when performing a parity check - yet I would have guessed that the load is just heavy (or worse) when performing a full disk rebuild. The card I am using is a Fujitsu D2607-A21 RAID controller flashed into IT-Mode. It does get hot, so I channeled air to flow across its heatsink (which looks pretty tiny i.m.o., hence supporting my assumption). According to the table provided on the hardware compatibly page, the Fujitsu D2607 should work and is even recommended, but I'm not sure if the "should" implies it will work stably (also, maybe the guy who previously flashed it into IT-mode did an upsy-daisy). Since I have little to no experience with unraid, I wanted to ask for help and whether my assumption seems plausible, that it is not the drive/s, but the HBA card that is failing. If that appears to be the case, do you think the best course of action may be better cooling (louder fans ) or a different/better (dedicated) HBA card? Or is my assumption incorrect and the problem lies somewhere completely different? Many thanks in advance! EDIT: There are two SATA cache drives connected directly to the mainboard, making the system a 10-drive system (2x parity, 2x cache and 6x data). zerver-diagnostics-20230227-1722.zip
