




blacklight
Members
-
Joined
-
Last visited
Everything posted by blacklight
-
It turns out that it was a remnant docker network I created via Portainer. I found this entry: 192.168.0.0/24 dev br-75ff69ec12b1 proto kernel scope link src 192.168.0.254 linkdown with docker network ls Which has the same exact subnet as the one on the bridge. From my understanding I thought the same subnets are possible in isolted docker networks (like the shim-networks), so I can not explain why this error occured. Deleting the network and restarting the service fixed the communcation error.
-
also I just saw the 192.168.0.254 address that I overlooked the whole time, and I have no idea what causes the address. My Unraid address is 192.168.0.10 and the one of the NAS is 192.168.0.116. Custom networks in the Docker page are enabled (ticked br0, br3 and br0.10 with DHCP on all three of them)
-
I just encountered a problem, where my NAS VM isn't reachable anymore and all my depending docker services, which depend on the NAS, went down. I use the main bridge br0 to attach all my VMs to the main subnet and never had bigger problems except my personal macvlan-bug debacle a year ago. Since then the virtual networks ran flawelessly, until I had to restart my machine last week. Since then, if the docker service is enabled, my NAS can not be pinged and also no shares can be mounted. If I disable the docker service the problem remains. I have to restart the machine first without the docker service enabled to be able to mount shares again (and ping the NAS and vice versa / all pings and mounts from Unraid with the Truenas vm as a target) Below you see a ping that is interuppted by the startup of the docker daemon. root@Icarus:~# ping 192.168.0.116 PING 192.168.0.116 (192.168.0.116) 56(84) bytes of data. 64 bytes from 192.168.0.116: icmp_seq=1 ttl=64 time=0.450 ms 64 bytes from 192.168.0.116: icmp_seq=2 ttl=64 time=0.315 ms 64 bytes from 192.168.0.116: icmp_seq=3 ttl=64 time=0.389 ms 64 bytes from 192.168.0.116: icmp_seq=4 ttl=64 time=0.402 ms 64 bytes from 192.168.0.116: icmp_seq=5 ttl=64 time=0.556 ms 64 bytes from 192.168.0.116: icmp_seq=6 ttl=64 time=0.492 ms 64 bytes from 192.168.0.116: icmp_seq=7 ttl=64 time=0.384 ms 64 bytes from 192.168.0.116: icmp_seq=8 ttl=64 time=0.280 ms 64 bytes from 192.168.0.116: icmp_seq=9 ttl=64 time=0.572 ms 64 bytes from 192.168.0.116: icmp_seq=10 ttl=64 time=0.505 ms 64 bytes from 192.168.0.116: icmp_seq=11 ttl=64 time=0.482 ms 64 bytes from 192.168.0.116: icmp_seq=12 ttl=64 time=0.281 ms 64 bytes from 192.168.0.116: icmp_seq=13 ttl=64 time=0.439 ms 64 bytes from 192.168.0.116: icmp_seq=14 ttl=64 time=0.278 ms 64 bytes from 192.168.0.116: icmp_seq=15 ttl=64 time=0.318 ms From 192.168.0.254 icmp_seq=16 Destination Host Unreachable From 192.168.0.254 icmp_seq=17 Destination Host Unreachable From 192.168.0.254 icmp_seq=18 Destination Host Unreachable From 192.168.0.254 icmp_seq=19 Destination Host Unreachable From 192.168.0.254 icmp_seq=20 Destination Host Unreachable From 192.168.0.254 icmp_seq=21 Destination Host Unreachable I will add a syslog later, where I turn on the service. I actually thought I fianally understood the whole macvlan network thing, but apparently not. So here is my configuration: Unraid version: error started in 7.1.2 persisted in 7.1.4 Network: Bonding: OFF Bridging: ON -> creates br0 Bridging Members Of Br0: eth0 IPv4 Address Assignment: Static (I had it on DHCP but to be on the safe side I changed it) Docker: Docker Custom Network Type: macvlan -> with the intention to assigning ip addresses for selected containers Host Access To Custom Networks: Enabled Preserve User Defined Networks: Yes (created by me manually and by Portainer) VM: Default Network Source: br0 The network snippet from the XML of the NAS VM: <interface type='bridge'> <mac address='52:54:00:a4:70:54'/> <source bridge='br0'/> <target dev='vnet0'/> <model type='virtio-net'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/> </interface> I tried a lot of suggestions for troubleshooting general macvlan prboblems like switching to non-bridged macvtaps or creating a custom newtork, but none of the suggestions I found in the forum and the docu helped me to solves this, while keeping the IP and haveing a connection between host and vm. Unfortuantely I can not explain what change from my side caused this, but it worked for over a year, without me changing anything in the network settings or the XML of the NAS (I never touched them after I got it to work). Thanks for any help :)
-
I tried to test what you suggested, but I get the same problem with the docker command in the Unraid CLI as with Portainer. root@Icarus:~# docker network create -d macvlan \ --subnet=192.168.10.0/24 \ --ip-range=192.168.10.40/29 \ --gateway=192.168.10.1 \ -o parent=br0.10 \ base_test_network Error response from daemon: failed to allocate gateway (192.168.10.1): Address already in use Despite the fact that I rebooted the system and turned portainer autostart off (so it didn't start at all during this cycle), the "Gateway already in use" problem remains. From what I understand, this is an additional problem right ? I didn't do anything about the autostart/ipv6 problem. Is this mandatory to be able to create the custom network at all ? The thing is that I am little anxious to start messing around with automatically created network settings in Unraid. I did this in the past and it sometimes took weeks for me to get the system running again, because I am simply not that proficient in networking. I wouldn't mind to create this custom networks in the CLI instead of inside portainer directly, but I want to try to avoid messing with the autostart procedures, if possible. Any idea why I can't create the network in the CLI (assuming your 2 posts are not directly dependent on each other) ?
-
Hello, I am trying to replicate the Unraid behavior of the MACVLAN interface option (picture below), that is listed under each container, inside Portainer. The goal is, to have the same option when deploying a Portainer stack as with Unraid when starting a docker and selecting a Custom adapter, which in my case is Custom: br0.10, so a macvlan adapter that connects to the bride br0.10 which also is a parent of eth0.10 from the tagged VLAN 10. Unfortunately the network creation in Portainer (which is using the same docker socket from my understanding) is not as trivial. In the two step process of Creating a configuration and creating the network itself, I tried multiple combinations for subnet, ip range and gateway. -> The gateway seems to be the main problem: if I set 192.168.10.1 as a gateway, I get the error that the gateway can't be assigned twice. I saw a similar problem here: Link, What is the correct IP to use as a gateway ? It seems to be a virtual docker gateway, but what is it used for in the macvlan scenario and why is it not the same as my network gateway. -> If I set a different gateway, I am able to create a container via a stack, but the container has no internet connection and can't ping other containers even in the same subnet (which the macvlan containers created via Unraid directly can !) Unraid Docker (Portainer as an example): Portainer: My exact configuration in Portainer: - name: examplenetwork_config - driver: macvlan - parent network: br0.10 - subnet: 192.168.10.0/24 - IP range: 192.168.10.40/29 (that is actually the range I want to assign for this stack, Unraid shouldn't assign anything near there with 192.168.10.128/26 set in the Unraid docker settings.) - gateway: 192.168.10.1 And when trying to create the network with: - name examplenetwork - driver: macvlan - configuration: examplenetwork_config I get the following error: "Failure Unable to create network: failed to allocate gateway (192.168.10.1): Address already in use" When changing the config to: - name: examplenetwork_config - driver: macvlan - parent network: br0.10 - subnet: 192.168.10.0/24 - IP range: 192.168.10.40/29 - gateway: 192.168.10.40 I can create the network, but as already mentioned it can not reach anything. What am I doing wrong here ? I also don't understand where my error is in the thought process, because in Unraid directly it works flawlessly. Is "Custom: br0.10" really a macvlan bridge, how else would each container get it's own IP ? Any help or even tips would be appreciated.
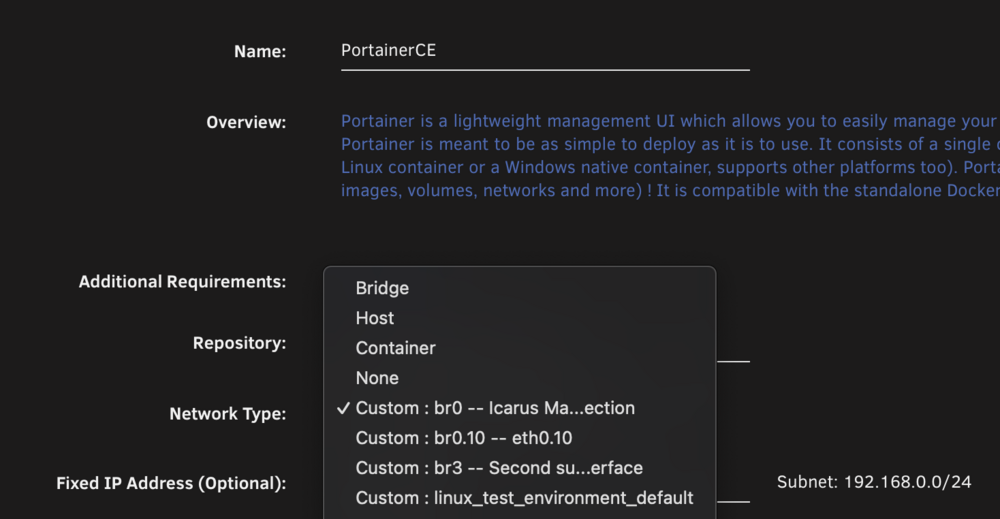
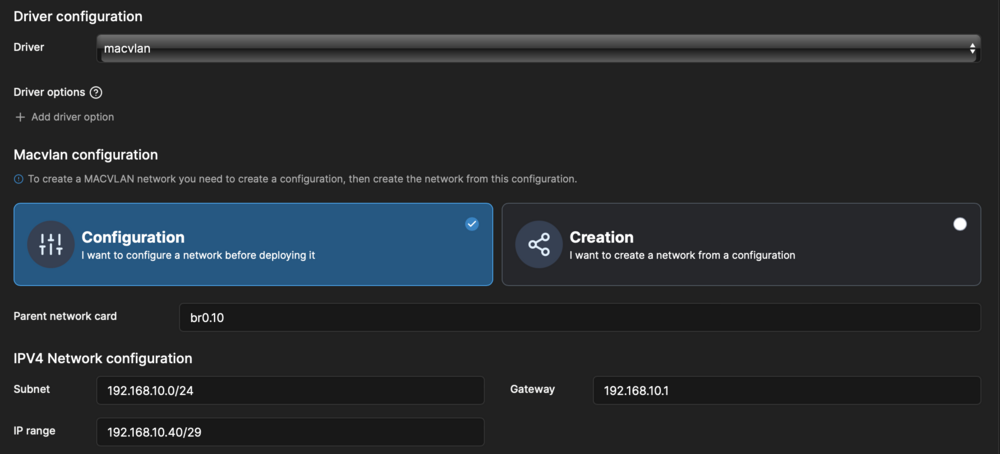
-
That's what I thought, unfortunate. But thanks anyway. The setting is on since years and I never turned it off. The configs are still there and didn't change, only the networks are gone and also the command to restart mentioned something about the deleted docker networks. I will try to recreate the network ones again to see the message and recreate the one missing manually. Okay will do that. It is unfortunate to see that even with backups there is no chance to restore this. I even was able to look inside the db to see my old networks, why is there no chance to restore them somehow ? At least the name,Ip range and which containers were attched ?
-
Hello, is there a chance to restore docker networks from local-kv.db ? I did this ... ... because my br0 was missing and it successfully recovered it but now all my custom docker networks are gone. Can I revert this without risking to loose br0 again in the docker tab ? I have .... : - a backup of the local-kv.db before I deleted it and restarted the docker service - daily backups (the last 100 or so) of the whole USB created with the "appdata backup" plugin - restarted the system and docker Any ideas how to do this the most clean way without me messing stuff up would be awesome. Thanks
-
SOLVED ! See here: The problem was the SMB share !
-
I just wanted to install plex on Unraid after my experience from the Truenas app, but unfortunately it is a real hustle for me. I started with the image from binhex: "binhex/arch-plexpass" and had problems setting the correct permissions from different shares. I used this string for extra parameters: --device=/dev/dri --mount type=tmpfs,destination=/tmp,tmpfs-size=10000000000 --no-healthcheck from this tutorial . After that I set all paths: CONFIG -> /mnt/remotes/Plex_Database (a ssd pool on my truenas vm with a user PUID=GUID=1044 and the mountcommand also mounts with the same PUID,GUID). MEDIA -> /mnt/hyperion/hyperion media/media (my secondary pool on unraid only for media) TRANS_DIR (as a system variable) -> /tmp (as stated in the tutorial above, so that the ram is used as a directory but only with 10gb instead of 20) HW_Encoding -> /dev/dri (I added this one myself to give the docker access to the GPUs for the future) My plex ui isn't able to play ANY titel no matter if movie or tv-show. I converted one title from mkv to mp4 which didnt help. The source of the files are *LEGAL* downloads (of course) and a few rips. If I try to use the settings button during the initial loading I get: "Unexpected errors during playback. Please visit our forum if you continue to experience problems." (translated from German) If I wait I either get : "An error has occurred while playing *movie name*. Error code s1003 (network)" OR: "This server is not powerful enough to convert videos. " ... with and without HW-Encoding turned on ... I am using a 13900KS, Unraid 7.0.0-rc.1, 128GB ram of which 50-80 ist mostly occupied depending on the load. These are a few error I found in the logs: "ERROR - [VoiceActivityDetectionManager] MDE: video has neither a video stream nor an audio stream" and I think this one can be ignored, but I am not sure. "ERROR - [Req#1fc2] XML: Database exception: sqlite3_statement_backend::prepare: locking protocol for SQL " "ERROR - [Req#212a] Unknown metadata type: folder" (The log is not anonymus, that is why I am not attaching it) My SMB layout is very niche, which is why I wanted to use the Unraid forum first before proceeding to the plex forum or reddit. Any ideas what I could have done wrong ? I thought all permissions are set, because plex was also avaible to prepare all the metadata. Could permissions be the problem ? I wouldn't think plex has problems with the mkv format. Thanks in advance
-
Ok you never guessed what it was .... silly me thought the pools work like the array in terms of layout. Apparently you can not have empty slots in a pool ... 🤦♂️ Well I knew it was nothing complicated because I was able to mount and use the disks via console, which made them invisible from the UI. After only using 2 slots it worked like a charm. I don't like that fact the the error message is very abitrary and I couldnt find the fact very easily but now I do undertand Also I am using this pool as a separate media storage, so I disabled all cahcing and moving settings, which completely cuts the pool of from my array (which is only for system data) That beeing said, I am realy looking forward that Unraid adds "Array" as a pool type so one can setup multiple Arrays with potentially multiple cache drives. One main reason I would love that, is because my main storage is on a Truenas vm and I only have system data (docker, small VM images, plugins, etc.) on my array, which gurantees a small resilvering time when one of my 500gb drives fails. Also I could go with double parity on the system files, which I don't need on my movie collection. Thanks anyway
-
I haven't had any problems since I am using 2 subnets. Both DHCP leases work immediately on the router and the switch. I also won't likely change back. Literally everything I used despite the airplay stuff works with ip calls and therefore is simple to use by a user like me. Trust me ... I tried everything, also a DHCP relay, which dind't work ! And most certainly is wrong in this use case because why should there be a relay INSIDE one subnet ? DHCP leases normally propagate in one subnet without problems ... Thanks for the concerns but I dont want to change the network ! I want to solve the issue without pulling out the root and planting a new tree !! nop tested and checked everything 100s of times. Chatgpt ? Guys thanks anyway, but please don't consider my network as a variable but rather as a constant ... I put enough time into networking
-
I also forgot: I successfully ran a pre clear on both disks. They didn't indicate an error.
-
Actually it is not that simple ! There is reason for multiple subnets, because it is not possible to use a 10gbe managed switch as just an unmanaged one connected to a fritzbox. For some reason DHCP calls vanish, I wasn't able to get it to work that way. For example Truenas was able to communicate a static IP with the fritzbox over the mikrotik (only one subnet), but DHCP didn't work. Unraid wasn't even able to even communicate the self set static IP with my router so it just assigned 169.XXXs.Trust me, maybe you haven't ran into problems with one subnet but I have ! Maybe my setup is weird, but at that point I thought a 10Gbe switch is enough (which in my set up was) but I will upgrade my router in the next year to a mikrotik box too.
-
I think I was able to get it to work. I tinkered around a little bit with this docker image and I found out that I had to create bridges over the physical networks. Also I had to use macvlan, which I dont have experience with but my guess is that ipvlans won't work, BUT again, I am not 100% sure. So I dont have the docker running on my router or switch but on my server. So I connected the server to both the subnets I wanted to bridge. So 192.168.100.0/24 (my router/wifi network - only 1 Gbit) and my switch/server/LAN subnet 192.168.0.1/24 (10 - Gbit duplex, main Unraid connection) are on two different server ports eth0 & eth3. I created, or rather I had to create 2 bridges (br0 & br3) to get it to work. But before that I also configured eth3 on Unraid as a standalone port -> bonding=off, bridging=on, static IP inside fritzbox. I the created two docker networks with the macvlan type like in the repo, but slightly changed: "docker network create --driver macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.XXX --opt parent=br0 physical" and "docker network create --driver macvlan --subnet 192.168.100.0/24 --gateway 192.168.100.XXX --opt parent=br3 physical" Then I could give the docker the two macvlan networks via docker compose or in my case a portioner stack and used the avahi image from above as the image the stack has to pull. After that I was able to: - stream audio from my workstation tower (192.168.0.XXX - lan subnet) to a firetv stick (192.168.100.XXX - router/wifi subnet) - stream audio from my iPhone (wifi subnet) via airplay to workstation tower to Shairport4w (lan subnet) - start iTunes Sync/Backup of my iPhone wirelessly, which unfortunately fails ... I am currently working on this, but I was unfortunately not lucky. It transferred 10s if not 100s of GB wirelessly but always fails at the end. I used a windows10 vm with iTunes on my server, but I will try libImobiledevice inside a docker in the future. Maybe this works, I will write an update. This was also my intended use case, because I am sick of having iTunes backups scattered over multiple devices. Unfortunately I have a fritzbox as a router and a mikrotik switch. So no options there, that is why I wanted my server to do this job, which it does now. I did 0 configuration of Avahi, if you have suggestions to solve my iTunes problem I would be glad ! But for all other airplay/cast applications it just worked. Can Avahi be counted as one ? Is there an alternative ? I couldn't find much. I take that as a prerequisite for all my network device All use DHCP and critical ones get a static lease from either my mikrotik or my fritzbox. There is an apple router I didn't know that ... No only Mobile devices and Macs. And I want to backup all of the wirelessly ... ! Thanks for your answer ! Glad about any future advices
-
For the first time I tried to create a secondary pool (not a cache) on Unraid. The process is either stuck at formatting or mounting, depending on if I format & create the filesystem via console (stuck at mounting) or inside the Unraid GUI (formatting). The attached part of the syslog shows the error "emhttpd: error: mkmbr, 2307: Is a directory (21): open: /dev/" and "kernel: emhttpd[22405]: segfault at 628" consistently when I try to format either btrfs or zfs on my 2x20TB Exos. I don't know if I am doing something wrong, but I want to use this pool as my media pool for movies and series - not as a cache. My main pool is inside a TruenasVM and my array is only 500gb on 2 ssds for system data (iso's, docker images, selected VM images). I wanted to use the btrfs (Raid1) pool for ease of use compared to my ZFS pool and because I don't want the RaidZ2 redundancy of my main pool. Any ideas what I am doing wrong or if this is a bug ? I was able to mount the formatted filesystem via console ... so my guess is this should work flawlessly inside the GUI ? Thanks for any help. log1.txt log2.txt
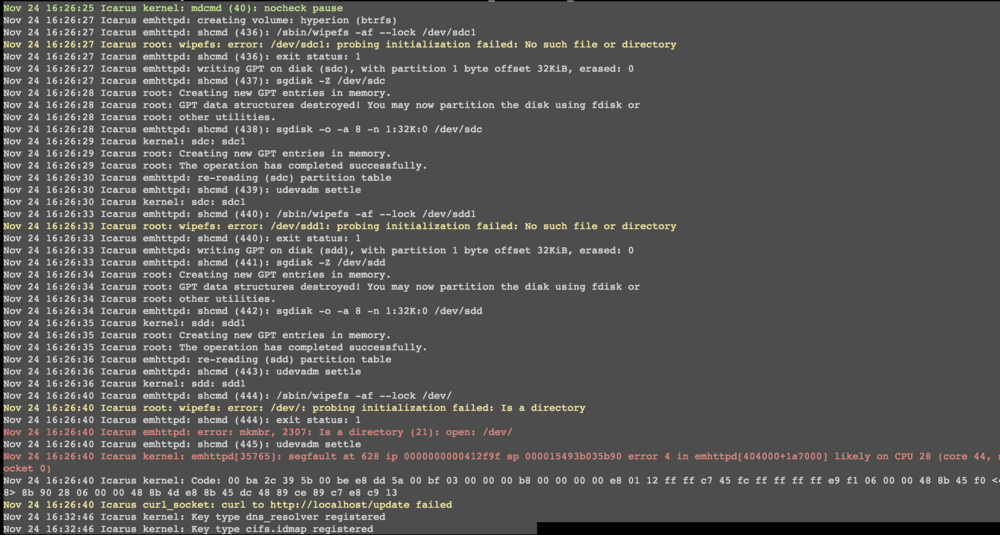
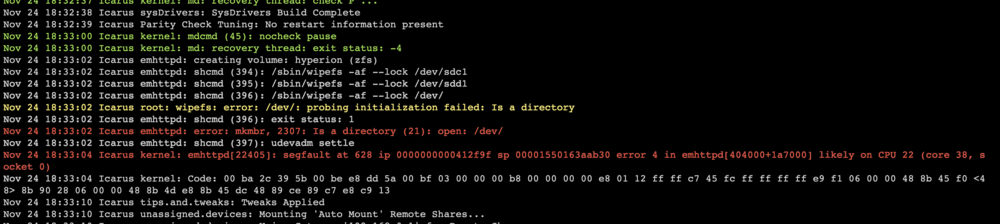
-
Hey there, I am interested in using a docker on my unraid server to deploy a Bonjour gateway/reflector. I have the problem that I want to integrate apple services on my unraid server and most of the network communication doesnt work across subents. I found this guide: bonjour across VLANs but I am not using any VLANs and I dont have the knowledge/experience with them. I tried to chatgpt through the problem but without success. My main goal is to use mDNS reflector from my Router subnet (192.168.100.1/24) to my server subnet (192.168.0.1/24). I have a main connection for the server to 192.168.0.1/24 as 192.168.0.10 (my unraids gui ip) and a seperate port just for a connection to the router subnet. What type of docker network should I use macvlan,ipvlan ? I have no idea. I would prefer to use a separat ip than my unraoid machine to avoid troubleshooting. Is that even a good idea with docker conatiners or should I use a vm ? I would be glad about any advice, tutorials etc. because I really didn't find much about deploying bonjour refelctors. Thanks
-
What Unraid version are you on 7.x beta ? I am on 6.12.13. Maybe it only works reliably for all VMs on the beta ... but I saw a few in this post who are on the same version and proceeded further into the installation process. I only changed the location because my Unraid pool is very small (500Gb). I am using a Truenas vm with an NFS share: no problems with hosting Winbdows 10, Ubuntu and freebsd from a external nfs share. Maybe mac doesn't like it ?
-
What am I doing wrong if I don't see the macOS image ? I basically went through the new spaceinvaderone tutorial step by step but in my case the image is not displayed. Only difference I have: the ISOs and the images are on a share of my NAS, but the rest is pretty much the same ... I am out of ideas
-
So I am tinkering around with VMs on Unraid for quite a while now, but I still can't figure out a simple way how to work with the change to macvlan (instead of ipvlan). I changed th macvlan because I am actually using a fritzbox router and I wanted to avoid problems with the network and the system stability (as descibed here: Unraid Doc MACVLAN It took me quite a while to get everything back online as I wanted it to be, but there is one thing I can't fix: Truenas Jails. So my main storage is Truenas inside a Unraid VM and that works pretty well for me. To access this storage I use mutiple ways like smb, nfs and also sftp. Sftp is a little special in this case because the mainstream way to access part of the storage is to create a jail with the sftp user as a root user (group wheel). That makes accessing via sftp/ssh easier than managing the access inside Truenas itself. With that solution a part or a whole pool can be mounted into the jail, to restrict access to certain shares. After changing from ipvlan to macvlan I can not reach the jails anymore from outside the VM despite the fact that I can still reach Truenas. The jails obtain IPs by my mikrotik switch's dhcp (of the local subnet) but can not be pinged from there ... I even added a separate virtual network adapter inside the VM xml in Unraid: <interface type='direct' trustGuestRxFilters='yes'> <mac address='52:54:00:a4:70:55'/> <source dev='vhost1' mode='bridge'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x09' function='0x0'/> </interface> Selecting the second adapter doesn't change the behavior and from my understanding it also shouldn't because both virtual adapters are bridged together with the host. I understand that the virtual bridge of Unraid is closed from the outside but I never had problems reaching the Truenas UI. During research I found plenty of tutorials for docker networks but for VMs in unraid it feels like a forest the 'usual' Unraid expert just knows how to navigate. My guess is, that the problem relies on the Unraid side, because I noticed it after changing to macvlan. Next to this I can ping the jail from truenas and vice versa with success. I would be glad about any explenation because I am trying for several days now without really understanding what the problem is. I have to rely on these sftp access jails fo photo backups of mobile device (and no unfortunately SMB/NFS is not an option, because it is just not as versatile). Thanks
-
Hey there, I just wanted to let you know that I finally solved it after all the time. It was quite an odysse with the system because I unfortunately was also affected by the overvoltage bug from Intel Raptor-Lake. I dont know what caused the vfio dma map -22 error, but it was definietly something unresolved from qemu @SimonF. Setp by step I fixed the problems over months: vfio dma map -22: I researched through qemu documentations and found a simple trick through try-and-error. My guess was that TrueNAS was causing a problem, if virtualized on Raptor-Lake, because it wouldn't run on the newest generation CPUs bare-metal (at least CORE wouldn't). By using older hardware with older CPUs I wouldn't have ran into that problem, but unfortunately when I began the project I did the mistake and avoided older Xeons and chose a newer i9 in the same price range with more performance. Not ideal but qemu allows for CPU emmulation so that is axactly what I did. I basically emulated an older CPU on top of the i9 with the <model name='Cascadelake-Server'/> entry. So my xml entry looks like this initally: <cpu mode='custom' match='exact' check='none'> <model name='Cascadelake-Server'/> <topology sockets='1' dies='1' cores='6' threads='1'/> <cache mode='passthrough'/> <maxphysaddr mode='passthrough'/> </cpu> However this initial xml entry was changed automatically by Unraid to: <cpu mode='custom' match='exact' check='full'> <model fallback='forbid'>qemu64</model> <topology sockets='1' dies='1' cores='6' threads='1'/> <feature policy='require' name='x2apic'/> <feature policy='require' name='hypervisor'/> <feature policy='require' name='lahf_lm'/> <feature policy='disable' name='svm'/> </cpu> I don't know, if the automatic change was set by Unraid or the switch between XML and form view and I also don't know if the XML change reverted anything but it works for me right now and the system is now error free for 3 weeks and the log is clean since then 🥳 Definitely check out the qemu documentation and also their channels on the website. They are very helpful ! Freezing Unraid UI: So this was automatically resolved with the change of the xml and since there is no VFIO_DMA_MAP error, the UI never bugged out. But from my point of view this is definitely a UNRAID/qemu problem and not a user error, because from what I saw/think, a bugged out VM should not have such effects on the hypervisor even more so when the VM is initally running normally. If the hypervisor crashes with the VM and logs the error or kills the VM to protect system stability, that would be a behavior I could interpret. But if such an unconnected UI bug happens I would never have guessed that this is connected to something like CPU incompatibility ... I am not a developer and I really appreciate the work put into Unraid but this simple bug did cost me months, because it forced me to restart the hypervisor and it made troubleshooting a VM so much more painful ! System not SHUTTING down: So this was my fault, because I implemented ugly start & stop user scripts, that mount and unmount shares of the NAS vm and the NFS shares weren't actually unmounted properly ... oops well what helped here is correcting the user scripts and using the plugin "Tips and Tweaks" to shut down any opened consoles. Anyway it feels weird, that Unraid is not suceeding a force shutdown just because a NFS was buggy during unmount. Any tips here for a global unmount would be appreciated, I still add them manually into a user script that looks something like this: #!/bin/bash sleep 150 # Wait for TrueNAS boot mkdir /mnt/remotes/mnt01... mkdir /mnt/remotes/mnt02... mkdir /mnt/remotes/mnt03... # # mount -t nfs 192.168.0... /mnt/remotes/mnt01... mount -t nfs 192.168.0... /mnt/remotes/mnt02... mount -t cifs -o username=...,password=... //192.168.0.... /mnt/remotes/mnt03... # # docker start *dockername* # delayed docker that depend on NAS Same goes for unmounting. The user scripts are then set to be either executed on startup or shutdown ... works the best for me. Also ...: -> ... I obvisouly updated the MB Bios for the new Intel microcode. Just wanted to mention it here. I think that wasn't the reason of any of the above mentioned probelms, but better safe than sorry. -> ... I switched from a 9300 LSI HBA to a 9500 LSI HBA with a SAS-Expander to have all drives in one IOMMU group for the VM (Alle errors persitet afterwards, I double checked !). Same here: I don't think that should be a problem for Unraid, but it was one of the variables I also changed/eliminated. Hope that helps someone.
-
it seems that I was not informed enough and KVM is in fact a Type 1 hypervisor. https://ubuntu.com/blog/kvm-hyphervisor Correct me if wrong .... I saw both over different sources. Still the question is Xen still out there for Unraid ? no idea ...
-
Hey there, I hope that is not a silly question, but I am currently solving problems on Truenas virtualization when I got a reply on the TN forum that the OS actually prefers Type I virtualization with passed through PCIe devices. https://forums.truenas.com/t/truenas-core-cant-execute-smart-check-not-capable-of-smart-self-check-resulting-in-bug/681/5 Because of that I wanted to ask if it is still possible to use the Xen based (Type I) virtualization in Unraid that Limetech used years ago or is that gone for good ? I saw there was a version 8 years ago that allowed both. How did that work back then ? Did you just switch the machine type ? Or was there a different template (like Windows 11, FreeBSD, etc.) ? Also has someone experience with virtualizing Truenas Core & Scale comparing them both ? Does it make a difference for the compatibility from KVM if my Guest OS is different than the Host (Core with FreeBSD) or if there is a same Guest Hosts systems (Scale with Linux base) performing better/ creating less problems (Considering PCIe passthrough) ? Thanks
-
Bug/Error persists after BIOS Update (which resets BIOS entries) and Unraid update (6.12.10) + I swapped the HBA to one of the BIFUR x8 slots to have full bandwidth. Unfortunately it didn't solve the problem. I noticed two things: 1. the qemu log stopped at one day but the VM was running for another 3 days, so I also couldn't see any shutdown command in the qemu log. Is it because the log overflows with the VFIO DMA MAP errors ? Can I clear the log somehow ? I also had another error inside the VM with TrueNAS. It couldn't SMART check two drives and I think it stopped at some point. Could it be that this was the same point the DMA MAP errors stopped ? I will actually give it a try and turn off the SMART check inside Truenas, maybe this fixes it. Could failed drives lead to such an error, even if the HBA is stubbed ? EDIT: the qemu log seems to stop shortly after starting the VM. Even under load or running tasks inside Truenas I can not see any new DMA MAP errors. 2. The unresponsive Unraid GUI behavior actually started after days of the VM running and not after stopping it immediately (which was the case before). I was able to restart it a few times without the GUI or the VM acting up. Any idea where I can find what the attribute -22 even means. I am researching about this error in particular for months now and I still have no clue what the error (code) actually means and yes I looked up the qemu documentation ... no luck from my side there.
-
And the crash is reproducible. Every time I want to SMB move files while 3 VMs are active EDIT: It happens for all transfers now no matter what Windows VM I use. I didn't even change the Truenas xml and it was working for days ... man Unraid makes me go insane : ( I however managed to get a diagnostics dump. It randomly works ... Find it attached. The only thing I noticed is that the times are not synchronized between the logs from libvirt, the trueness vm and the windows vm. Another idea, is there a chance to change the libvirt/qemu version (again) to maybe an older or a newer version ? I already did it with the edk2 as explained here: Does that include libvirt/qemu ... I have no idea ... Glad about any answer. icarus-diagnostics-20240322-0553.zip
-
If you consider trying another mainboard (I know it's not ideal): I am close to using all PCIe lanes on the Asus W680 ACE with the i9. It works like a charm and the IOMMU layout is perfect for my use case. You can easily riser the m2 slots for additional x4 PCIes and I will even try a SLIM SAS to PCIE adapter soon, that would give you up to 8 PCIe slots (2 x8 and 6 x4) on a workstation mainboard. I can't speak for that HBA and mainboard in particular never used it, sry ...





