




dhomas
Members
-
Joined
-
Last visited
Everything posted by dhomas
-
Thanks for looking into it! I updated from the unraid update utility. After some time (I think it might have been upgrading the internal DB?), it came up and started working again. It connected up to my other Syncthing agent in version 1.30. Now I just have to figure out how to compile version 2.0.2 myself for my other NAS (a Drobo 5N2).
-
So, I stopped the container and tried starting it via 'docker run' which didn't fail at startup, but seemed to hang. I may have not started it correctly, though. I ended up rolling back to Syncthing v1.3.0 and everything is back to normal. I think the binhex container will need to be tweaked to work with version 2.0.0, though.
-
So, Syncthing proposed an update to version 2.0.0 today. I've previously updated from older versions to newer from within the web interface, but this time it didn't come back up. I see this in the logs: ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 2025-08-12 09:34:47,319 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23158311906064 for <Subprocess at 23158313690048 with name start-script in state STARTING> (stdout)> 2025-08-12 09:34:47,319 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23158312503344 for <Subprocess at 23158313690048 with name start-script in state STARTING> (stderr)> 2025-08-12 09:34:47,319 WARN exited: start-script (exit status 80; not expected) 2025-08-12 09:34:47,319 DEBG received SIGCHLD indicating a child quit 2025-08-12 09:34:50,323 INFO spawned: 'start-script' with pid 86 2025-08-12 09:34:50,340 DEBG 'start-script' stderr output: syncthing: error: unknown flag -c, did you mean one of "-h", "-C", "-D", "-H"? 2025-08-12 09:34:50,341 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23158312310160 for <Subprocess at 23158313690048 with name start-script in state STARTING> (stdout)> 2025-08-12 09:34:50,341 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23158312312608 for <Subprocess at 23158313690048 with name start-script in state STARTING> (stderr)> 2025-08-12 09:34:50,341 WARN exited: start-script (exit status 80; not expected) 2025-08-12 09:34:50,341 DEBG received SIGCHLD indicating a child quit 2025-08-12 09:34:51,342 INFO gave up: start-script entered FATAL state, too many start retries too quickly ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ I would try to change the startup script but I don't know where to do it. Anyone else having this issue and/or know how to fix it?
-
Running a repair in Windows seems to have fixed it. Triggered another parity check, though, on restart. Thanks for your help!
-
I'll try that after my parity check completes. I just found it odd that I only started getting the error after upgrading. Thanks for the tip! I'll report back after doing the repair to confirm the solution.
-
Hello all! I just updated to unraid 6.12.12 and upon reboot, I received this error message via email: "Event: USB flash drive failure Subject: Alert [UNDOM] - USB drive is not read-write Description: DataTraveler_2.0 (sda) Importance: alert" I tried to reboot again and the error message reappeared. This second reboot also triggered a parity check, not sure why. I've seen some other posts about this error message, but it seems suspect to me that the error message only appeared after updating. I've checked and this is the very first time I received this message. When I check syslog, I can see the following error message repeating every minute: Aug 21 15:49:39 unDOM flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Aug 21 15:50:00 unDOM kernel: FAT-fs (sda1): error, corrupted directory (invalid entries) I've also included diagnostics, if it can be helpful. What do I need to do to avoid a crash? Thanks for any help! undom-diagnostics-20240821-1552.zip
-
Did anyone ever figure this out? I still don't have full driver support on my Asus Prime Z790M-Plus motherboard.
-
I've got 2 sticks of 48GB. I'll plan some downtime (this is my "production" Plex server) to test the sticks individually. Right now, I've been up for 1 day 16 hours and parity check has completed (after the unclean shutdowns). Thanks again for your support!
-
I really thought it was bad RAM, too. But I tested it for over 13 hours and 8 passes. Could a bad USB flash drive cause something like this? It shouldn't, I think, since unraid is loaded to RAM on boot from my understanding. But I think I've had a crash before when I bumped the USB boot drive, so I'm not sure.
-
I started up again and so far no errors after about 2 hours. SHFS crashed within about 1h20m last time. I hope it will complete the parity check this time around (only 22 hours to go! ). I noticed another segfault at startup for a process that I'm unfamiliar with (and for which searching didn't provide much of use): Apr 10 06:23:29 unDOM kernel: update-mime-dat[1575]: segfault at 150000 ip 00001517c54af159 sp 00007ffc1f731778 error 4 in libc-2.37.so[1517c536c000+169000] likely on CPU 12 (core 24, socket 0) Apr 10 06:23:29 unDOM kernel: Code: 77 c3 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 44 00 00 89 f8 48 89 fa c5 f9 ef c0 25 ff 0f 00 00 3d e0 0f 00 00 0f 87 37 01 00 00 <c5> fd 74 0f c5 fd d7 c1 85 c0 74 5b f3 0f bc c0 c5 f8 77 c3 0f 1f In any case, I'll keep monitoring. When it works, unraid is so very powerful. Coming from a Drobo that only just barely served files (their "DroboApps" were laughable), it's been a blast to use. I just really need it to be stable. Thanks for your help!
-
Here is the syslog leading up to the crash (syslog.log) as well as the syslog created upon startup to recover the files (syslog-new.log). Thanks for any help! syslog.log syslog-new.log
-
Syslog is already enabled, but I could not retrieve it as the filesystem was no longer accessible and SCP was not working. I will turn it on again and retrieve the syslog and post it here.
-
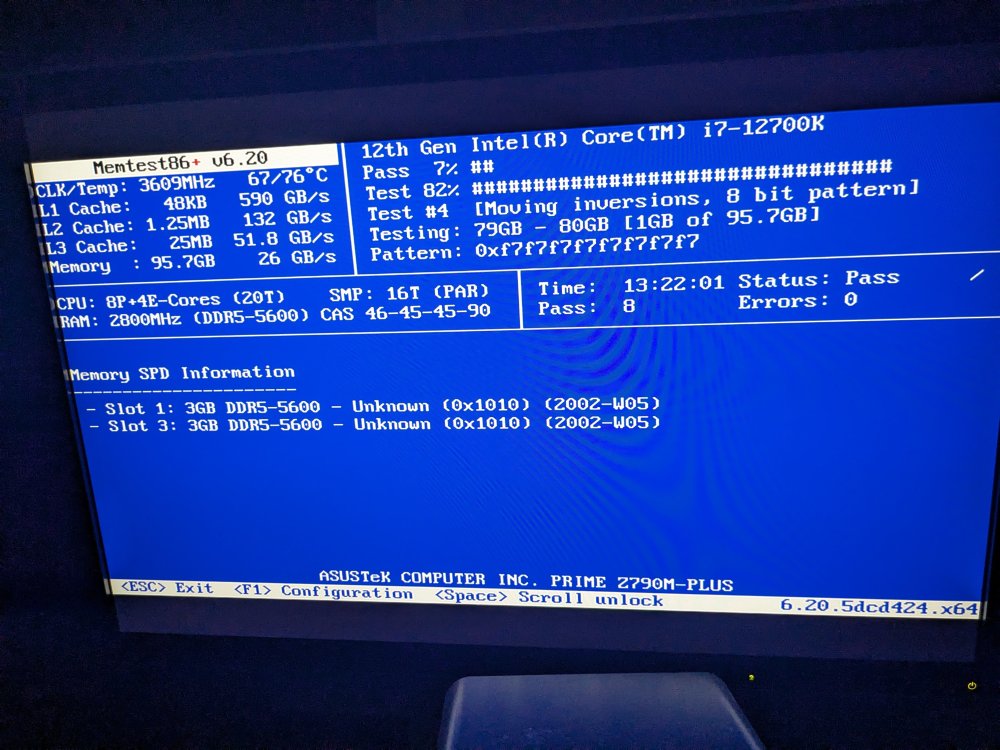
Hello there! I am still relatively new to unraid, having build my machine and installed it about December 2023. In my time using unraid, it has been quite unstable and I don't know why. I tried many things to stabilize it, but it's only gotten worse. Here is a timeline of events: Install on 6.2.18 around December 2018 Imported about 60TB from old NAS Started installing some containers in parallel Some containers may have been setup incorrectly as the system became unstable after installing them; uninstalled all containers System was stable-ish Upgraded to 6.2.19 Every so often (maybe once a week), the system would lock up: WebUI unavailble, no response from keyboard presses, no activity on attached monitor, single-press power button did not trigger shutdown Tried to update BIOS, which resulted in my RAM no longer being correctly recognized by my motherboard (issue raised to Asus) Downgraded BIOS; tested RAM extensively (8 passes on MemTest86+, see attached) Installed Immich Upgraded to 6.2.20 Now extremely unstable; cannot even stay up long enough to complete parity check The WebUI remains accessible, but all shares disappear. I can shut down via the WebUI. This is also the case if I start in safe mode Diagnostics are attached. Thanks for any help! This is driving me bonkers! undom-diagnostics-20240410-0833.zip
-
Thanks for the reply! I only now noticed it.
-
Hello there! I had a question about giving my spare license away. In a fit of FOMO, I bought an unraid license just before the pricing model change. The license has yet to be used or associated to a USB key. I talk about unraid to all my friends (even though I'm a pretty recent convert myself) and just convinced another friend to take the plunge. I would like to "gift" him the spare license I bought a few days ago so he, like me, can benefit from the unlimited lifetime upgrades. I saw this thread that touches on the topic: However, this appears to be to transfer a "used" license to someone else. Mine has not been used yet, so I thought my case warranted its own thread. I can see on the invoice that the license is attributed to my name and email address. Can I send the unactivated license key to my friend for him to use? Or will he need to activate it using my name and email address? Thank you for any advice! Cheers! Dhomas
-
I used the Unassigned Devices Preclear plugin to preclear my Disk 5.
-
After a format, the new drive is also functional. Thanks for your help! I'm learning unraid, so these types of small issues still make me a little skittish. I'll mark your post as a solution. However, my understanding is that it should not be necessary to reboot for these types of array operations, provided my drives are already physically installed. Any clue as to what made the previously functional Disk 4 show up as Unmountable? So I can avoid these mini heart attacks in the future.
-
Phew! A reboot seems to have fixed Disk 4. Disk 5 still appears as Unmountable. I suppose I should just format that one.
-
Hello all! I am having a problem that I don't know how to resolve. I had an array of 2 x 22TB parity drives and 4 data drives: 2 x 16TB, 1 x 22TB, and 1 x 20TB. I wanted to add a 5th data drive, an 18TB, to the array. I performed the preclear on the new drive, all completed successfully with no errors (pre-read, preclear, post-read). I then stopped the array, added the new drive (Disk 5) to the array and started it up again. When I started it, Disk 4 (which already has data on it) and Disk 5 showed up as "Unmountable: Unsupported partition layout". See below: I do not want to lose the data on Disk 4. Disk 5 is new, so I don't care if I need to format it again. How should I proceed? Thank you for any help you can provide. Edit: added diagnostics. Regards, Dhomas undom-diagnostics-20240314-0819.zip

-
I just performed the operation. Parity is being rebuilt on the newly added parity drive. The replaced disk is being reconstructed. All in parallel. It worked better than I expected! Thanks again!
-
Thank you for the advice and clarifications. I will try this today and mark your post as a solutions after successfully applying it.
-
Hello there! Still getting the hang of Unraid, so I have a lot of questions. I try to find answers before posting, but some answers seem older and may no longer apply to the latest versions of unraid. I also have a very particular situation that I am not sure how to handle. Here is the context: I currently have 1 x 22TB parity drive with 1 x 22TB, 2 x 16TB, and 1 x 14TB data drives. I am in the process of preclearing 1 x 22TB drive and 1 x 20TB drive. All my drives are hotswappable; I was happy to see that Unassigned Devices saw them as soon as I inserted them into the empty bays and I was able to preclear them without restarting the whole machine. Here is what I would like to do: Add the 22TB drive as a second parity drive Replace the 14TB data drive with the new 20TB drive Can I perform these operation in a single step? I would think I would do so in the following manner: Stop the array (after the preclear operations are done) Add the second parity drive Drop the 14TB (by setting it to "No Device") Add the 20TB drive into the slot liberated by the 14TB drive Replace the 14TB drive with the 20TB drive Start the array Is it as simple as that? Will this actually work? Or does the parity need to rebuild first when adding a second parity drive? Thanks for any advice! Regards, Dhomas
-
Hello all, Still pretty new to unraid, but I'm starting to get the hang of it. I am currently transferring everything to my unraid machine from a Drobo 5N2 using rsync. Today, while performing 2 concurrent rsync operations, the transfer just stopped. When I checked to see if my system was running ok, I saw that there was zero activity and the CPU was at 2%. I checked syslog and saw this: Feb 24 11:36:55 unDOM kernel: BUG: Bad page state in process ssh pfn:74d42a Feb 24 11:36:55 unDOM kernel: page:00000000a8e33046 refcount:0 mapcount:0 mapping:000000001057dde6 index:0x0 pfn:0x74d42a Feb 24 11:36:55 unDOM kernel: memcg:7000000 Feb 24 11:36:55 unDOM kernel: invalid mapping:00000000bc000000 Feb 24 11:36:55 unDOM kernel: flags: 0x17fff8000000000(node=0|zone=2|lastcpupid=0xffff) Feb 24 11:36:55 unDOM kernel: raw: 017fff8000000000 000000008e000000 dead000000000122 00000000bc000000 Feb 24 11:36:55 unDOM kernel: raw: 0000000000000000 0000000003000000 00000000ffffffff 0000000007000000 Feb 24 11:36:55 unDOM kernel: page dumped because: page still charged to cgroup Feb 24 11:36:55 unDOM kernel: Modules linked in: xt_CHECKSUM ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle vhost_net tun vhost vhost_iotlb tap xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter xfs md_mod zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs af_packet 8021q garp mrp bridge stp llc bonding tls i915 intel_rapl_msr intel_rapl_common x86_pkg_temp_thermal intel_powerclamp iosf_mbi coretemp drm_buddy i2c_algo_bit ttm kvm_intel drm_display_helper drm_kms_helper kvm drm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 sha256_ssse3 sha1_ssse3 aesni_intel input_leds intel_gtt crypto_simd cryptd rapl mei_hdcp mei_pxp wmi_bmof joydev led_class agpgart intel_cstate i2c_i801 syscopyarea mpt3sas nvme mei_me i2c_smbus sysfillrect Feb 24 11:36:55 unDOM kernel: intel_uncore tpm_crb ahci raid_class video e1000e nvme_core sysimgblt i2c_core mei tpm_tis scsi_transport_sas libahci vmd thermal fb_sys_fops fan tpm_tis_core wmi tpm backlight intel_pmc_core acpi_pad acpi_tad button unix Feb 24 11:36:55 unDOM kernel: CPU: 10 PID: 20249 Comm: ssh Tainted: P O 6.1.74-Unraid #1 Feb 24 11:36:55 unDOM kernel: Hardware name: ASUS System Product Name/PRIME Z790M-PLUS, BIOS 1630 02/04/2024 Feb 24 11:36:55 unDOM kernel: Call Trace: Feb 24 11:36:55 unDOM kernel: <TASK> Feb 24 11:36:55 unDOM kernel: dump_stack_lvl+0x44/0x5c Feb 24 11:36:55 unDOM kernel: bad_page+0xcc/0xe4 Feb 24 11:36:55 unDOM kernel: check_new_pages+0xb0/0xbc Feb 24 11:36:55 unDOM kernel: __rmqueue_pcplist+0x2ea/0x472 Feb 24 11:36:55 unDOM kernel: get_page_from_freelist+0x2b6/0x89a Feb 24 11:36:55 unDOM kernel: ? __kmem_cache_alloc_node+0x118/0x147 Feb 24 11:36:55 unDOM kernel: __alloc_pages+0xfa/0x1e8 Feb 24 11:36:55 unDOM kernel: alloc_skb_with_frags+0x8e/0x13d Feb 24 11:36:55 unDOM kernel: sock_alloc_send_pskb+0x1e9/0x23a Feb 24 11:36:55 unDOM kernel: ? get_compat_sigset_argpack.constprop.0+0x3b/0x3b Feb 24 11:36:55 unDOM kernel: unix_stream_sendmsg+0x13e/0x41f [unix] Feb 24 11:36:55 unDOM kernel: sock_sendmsg_nosec+0x2f/0x40 Feb 24 11:36:55 unDOM kernel: sock_write_iter+0x89/0xb8 Feb 24 11:36:55 unDOM kernel: vfs_write+0x10c/0x1b9 Feb 24 11:36:55 unDOM kernel: ksys_write+0x76/0xc2 Feb 24 11:36:55 unDOM kernel: ? fpregs_assert_state_consistent+0x20/0x44 Feb 24 11:36:55 unDOM kernel: do_syscall_64+0x68/0x81 Feb 24 11:36:55 unDOM kernel: entry_SYSCALL_64_after_hwframe+0x64/0xce Feb 24 11:36:55 unDOM kernel: RIP: 0033:0x14f19b04cba0 Feb 24 11:36:55 unDOM kernel: Code: 40 00 48 8b 15 79 42 0e 00 f7 d8 64 89 02 48 c7 c0 ff ff ff ff eb b7 0f 1f 00 80 3d 41 ca 0e 00 00 74 17 b8 01 00 00 00 0f 05 <48> 3d 00 f0 ff ff 77 58 c3 0f 1f 80 00 00 00 00 48 83 ec 28 48 89 Feb 24 11:36:55 unDOM kernel: RSP: 002b:00007ffcfbd97c18 EFLAGS: 00000202 ORIG_RAX: 0000000000000001 Feb 24 11:36:55 unDOM kernel: RAX: ffffffffffffffda RBX: 0000564d59e66080 RCX: 000014f19b04cba0 Feb 24 11:36:55 unDOM kernel: RDX: 0000000000008000 RSI: 0000564d59ee56d0 RDI: 0000000000000005 Feb 24 11:36:55 unDOM kernel: RBP: 0000564d59e60540 R08: 0000000000000000 R09: 0000000000000000 Feb 24 11:36:55 unDOM kernel: R10: 0000000000000000 R11: 0000000000000202 R12: 0000564d59ee56d0 Feb 24 11:36:55 unDOM kernel: R13: 0000000000008000 R14: 0000564d59e626a0 R15: 0000000000000000 Feb 24 11:36:55 unDOM kernel: </TASK> I was able to break the operation (CTRL-C) in my browser terminal window and resume the rsync transfer in the same session. So, other than wasting a little time where no transferring was being done, there was no harm done to my machine. Should I be concerned that this is symptomatic of a larger issue? Or should I just ignore it and hope it doesn't happen again? Thanks for any advice you can provide! Regards, Dom
-
So, after removing all the docker images and rebooting, the system is stable again. The Parity Check just completed successfully a minute ago after running for about 38 hours and found 6610 (thanks for confirming that this is expected). I will assume one of the containers was at fault. I'll add them back one at a time to see if one of them in particular is causing the system stability issues. I'll now consider this case closed. Thanks again for your support!
-
Right after posting this, I checked again and the errors went up in one shot to over 6600. Possibly more, since it stopped loggin? Feb 21 13:15:56 unDOM kernel: md: recovery thread: P corrected, sector=21610030936 Feb 21 13:15:56 unDOM kernel: md: recovery thread: stopped logging Is my data safe? Do I need to do anything? I realize this is unrelated to the initial issue, so should I open a new thread? Edit: it just stopped writing the individual errors so it didn't fill syslog with 6600 lines. Parity check is still ongoing and I assume will continue to report errors.


