





snowboardjoe
Members
-
Joined
-
Last visited
-
Went to base of URL and then I could select MFA settings. https://account.unraid.net/ Thanks!
-
That link is not working. I get prompted to login and it's successful, but it loops back to log me in again.
-
Old thread, but was wondering how this was resolved? I'm running into the same issue where grafana insists on running as 472:0. PUID/PGID have no effect.
-
Looking for help on getting Grafana container reinstalled. I'm starting over from scratch and purging the old data. Directoty /mnt/user/appdata/grafana is owned by nobody:users. No matter what I do from the configuration of the container, I can't force it to use this uid:gid. It insists on using 472:0 which I don't want it to use. Why is this container so difficult to manage?
-
Yes, that's where I thought it would be, but there is no option there to modify MFA.
-
I want to change my MFA settings to a different provider, but I can't find it anywhere in my account settings, profile, etc., here in the forums. Don't see any other help forum to get assistance here either.
-
I've been spending hours getting the system back to normal the past day and making good progress. Here's what happened and looking for guidance to complete the recovery and verify I'm in a better state than before. Running 6.12.10 as of right now. Btrfs corrupted Been having a problems for the last 6 months with my btrfs based cache constantly using 5GB of space daily. The first time back in the fall it reached 90% and was impacting applications that did not have enough free space. I was unable to find what was growing. `df` reports it was full and btrfs indicated the same thing. Hardly any metadata space was in use and all was in data. No subvolumes, no snapshots, tools say everything is healthy. Yet it was impossible to find what was growing. I had about 120GB of real data, but btrfs says I was use 360GB at this point. I ended up copying the entire contents of my cache to another drive, deleted what was on cache and it went back to 0%. I copied the data back and now `df` and btrfs report 120GB in use. WTH? The next day the slow growth was back and this week it got to 90% again. After more hours trying to troubleshoot and gave up and decided I needed to clear the cache, reformat it and rebuild it again, assuming there was some kind of underlying corruption from last year. Errors clearing cache Shutdown Docker and set all shared to use array as primary. My appdata would not move for some reason and that was weird. I ended up moving the data manual (rsync). One of my fatal errors was not checking things worked in the new space before deleting what was still left in cache--that's on me. I did manually move docker.img. I then tried to fire everything up and things got really weird. All of my docker containers were acting as if this was the first time I launched them--all of them. Recovery Started rebuilding data from my CP backups and have most of it in place. Only data lost so far my Plex metadata (not the media in the array). I'm at a good stopping point with the recovery and want to get the less critical components, but I want to make sure I'm doing this right from the beginning. I need to stop docker, set appdata to use cache as primary and let mover do its thing. I need to make sure I'm not using the explicit path of /mnt/cache/appdata for the docker.img (I recall seeing that and I think that was a bad thing to do as it should be associated with a share, right?). The fact that mover would not move everything off the cache in the first place that should have been a big red flag that something was not right and I should have stopped what I was doing right there to analyze things first to prevent data loss.
-
I finally ended up clearing the cache. Set all shares to use array only, shutdown docker, ran mover. I made the mistake of not protecting the docker.img, but just too some time to reinstall all previous apps. Then I allowed appdata to use cache as preferred device again. Massive change in utilization. I recovered hundreds of gigabytes. I still have some growth, but I have some theories on the problem. Something solely within appdata.
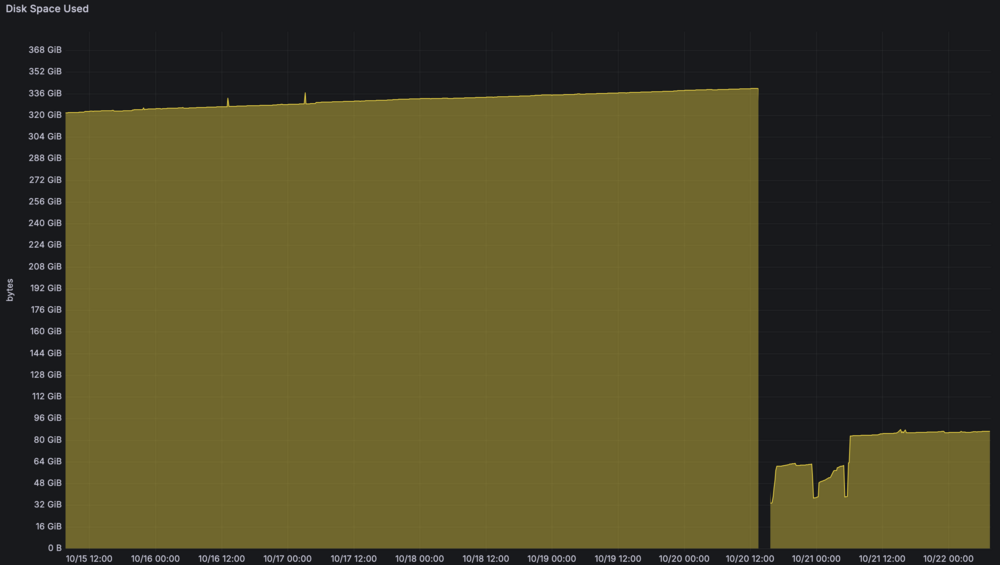
-
Compression is off--never enabled. Even if it was enabled, I would not expect the raw data to double in size like it does now. Gong to check if there are any underlying snaphots. UPDATE: No subvolumes found. Going to try offloading directories to see what happens with that mount point.
-
This is interesting. I just inserted a spare drive into my system and formatted as xfs. I then rsync'd /mnt/cache to the new drive. Then I checked output from df for this: root@laffy:~# df -h /mnt/cache /mnt/disks/WD-WX21DA735946/ Filesystem Size Used Avail Use% Mounted on /dev/sdd1 466G 334G 132G 72% /mnt/cache /dev/sdc1 5.5T 177G 5.3T 4% /mnt/disks/WD-WX21DA735946 root@laffy:~# df -l /mnt/cache /mnt/disks/WD-WX21DA735946/ Filesystem 1K-blocks Used Available Use% Mounted on /dev/sdd1 488386552 349294220 137669236 72% /mnt/cache /dev/sdc1 5858435620 185293440 5673142180 4% /mnt/disks/WD-WX21DA735946 That's surprising to see the variation there between the filesystems both in terms of disk used and inodes used. Appears brtfs is causing a LOT of overhead for the same data. Not sure how I'm going to find this. I suspect it's the Plex data, but not sure yet.
-
I also thought about making a copy of /mnt/cache into some scratch space and evaluating things as well. Seems more like an issue with brtfs and it's frustrating. I've had to troubleshoot problem like this for years, but only with more traditional filesystem types. This really eludes me. I have a lot of directories in /mnt/cache/appdata. I was hoping the du command under the suite of brtfs subcommands would help, but just confirm what du was already telling me.
-
I'm fully aware of that. I've been managing Linux systems for decades. Restating this point is not helping the situation here. What would be helpful is for you to answer my direct questions above. If you can't then let someone els provide assistance.
-
The app NerdTools is no longer supported.
-
This is what I have right now on my system. I'm focusing just on the /mnt/cache mount point here. root@laffy:/mnt/cache# btrfs filesystem df /mnt/cache Data, RAID1: total=463.73GiB, used=349.81GiB System, RAID1: total=32.00MiB, used=80.00KiB Metadata, RAID1: total=2.00GiB, used=460.05MiB GlobalReserve, single: total=224.84MiB, used=0.00B root@laffy:/mnt/cache# btrfs filesystem du -s /mnt/cache Total Exclusive Set shared Filename 136.58GiB 136.58GiB 4.00KiB /mnt/cache DF reports 349GiB used. DU reports 136GiB used. That's a massive variance. How do I find what is filling up /mnt/cache? When DF reaches 100% I'm dead in the water. That's what I'm trying to prevent. I'm 71% of the way there already and it keeps rising constantly. Normally I would use du to help find directories and subdirectories to isolate growth, but that is not working here as none of them show any significant usage or growth (nothing that would explain a 215GiB variance). What preventative measures can I take to to find and isolate what is eating up disk space before I'm out of space in /mnt/cache?
-
You're missing my point. Btrfs tools show that only 135GB is in use. What is the df output hundreds of GB's off?


