

lovingHDTV
-
Posts
605 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by lovingHDTV
-
-
the docker just stopped working for me. when I try to download a movie I get:
07-15 10:32:20 ERROR [chpotato.core.plugins.log] API log: {'file': u'http://HOST/couchpotato/static/scripts/combined.plugins.min.js?1580803031', 'message': u"chrome 91: \nUncaught TypeError: Cannot read property 'length' of undefined", 'line': u'1288', 'page': u'http://HOST/couchpotato/movies/', '_request': <couchpotato.api.ApiHandler object at 0x14fda2805d90>}
and it no longer issues the search to the indexers.
It worked a couple weeks ago, but I have updated since then. I'm currently up to date.
Ideas?
-
Just wanted to say thanks. Works great.
Backed-up my current config, stopped older version, installed this, imported my backup, and updated the firmware for all my access points.
worked perfectly.
thanks
-
Ok rebooted in safe mode. added the cache drive back, I guess unraid lost track of it. Rebooted and its up and running.
thanks
-
wonderful the cache drive didn't come back.
It is only a few months old.
-
like so:
append vfio-pci.ids=8086:10d6 nvme_core.default_ps_max_latency_us=0 initrd=/bzroot -
This AM I noticed none of my docker were running. Looking at the log file I found this:
Apr 23 00:00:02 tower Plugin Auto Update: Checking for available plugin updates Apr 23 00:00:05 tower Plugin Auto Update: Update available for ca.mover.tuning.plg (Not set to Auto Update) Apr 23 00:00:05 tower Plugin Auto Update: Update available for dynamix.wireguard.plg (Not set to Auto Update) Apr 23 00:00:06 tower Plugin Auto Update: Update available for nvidia-driver.plg (Not set to Auto Update) Apr 23 00:00:06 tower Plugin Auto Update: Update available for parity.check.tuning.plg (Not set to Auto Update) Apr 23 00:00:06 tower Plugin Auto Update: Update available for preclear.disk.plg (Not set to Auto Update) Apr 23 00:00:06 tower Plugin Auto Update: Update available for unassigned.devices.plg (Not set to Auto Update) Apr 23 00:00:06 tower Plugin Auto Update: Community Applications Plugin Auto Update finished Apr 23 02:15:15 tower kernel: nvme nvme0: I/O 370 QID 2 timeout, aborting Apr 23 02:15:45 tower kernel: nvme nvme0: I/O 370 QID 2 timeout, reset controller Apr 23 02:16:15 tower kernel: nvme nvme0: I/O 14 QID 0 timeout, reset controller Apr 23 02:18:57 tower kernel: nvme nvme0: Device not ready; aborting reset, CSTS=0x1 Apr 23 02:18:57 tower kernel: blk_update_request: I/O error, dev nvme0n1, sector 1049736304 op 0x0:(READ) flags 0x80700 phys _seg 1 prio class 0 Apr 23 02:18:57 tower kernel: blk_update_request: I/O error, dev nvme0n1, sector 1816114528 op 0x0:(READ) flags 0x80700 phys _seg 1 prio class 0 Apr 23 02:18:57 tower kernel: nvme nvme0: Abort status: 0x371 Apr 23 02:21:05 tower kernel: nvme nvme0: Device not ready; aborting reset, CSTS=0x1 Apr 23 02:21:05 tower kernel: nvme nvme0: Removing after probe failure status: -19 Apr 23 02:23:13 tower kernel: nvme nvme0: Device not ready; aborting reset, CSTS=0x1 Apr 23 02:23:13 tower kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 2, flush 0, corrupt 0, gen 0 Apr 23 02:23:13 tower kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme0n1p1 errs: wr 0, rd 2, flush 0, corrupt 0, genPrior to these log entries there is no messaging about my nvme0n1p1 except when it rebooted from updated a few weeks ago.
I've tried to stop the array, but just get a ton of errors about trying to unmount the cache drive:
Apr 23 10:19:41 tower root: umount: /mnt/cache: target is busy. Apr 23 10:19:41 tower emhttpd: shcmd (42946): exit status: 32 Apr 23 10:19:41 tower emhttpd: Retry unmounting disk share(s)... Apr 23 10:19:46 tower emhttpd: Unmounting disks... Apr 23 10:19:46 tower emhttpd: shcmd (42947): umount /mnt/cache Apr 23 10:19:46 tower root: umount: /mnt/cache: target is busy. Apr 23 10:19:46 tower emhttpd: shcmd (42947): exit status: 32 Apr 23 10:19:46 tower emhttpd: Retry unmounting disk share(s)...I'm pretty sure the cache drive isn't going to suddenly turn on, so how should I proceed?
thanks
david
-
I had three severs defined and they worked fine. I upgrade all my dockers and to 6.9.1 (was 6.9.0-RC<something>) and now mineos only shows the one server I added most recenlty.
I do see them in the games area, their backups are there as well.
Ideas on why Mineos has lost track of them?
thanks
-
45 minutes ago, olehj said:
You do select a group ID as well? It requires both.
No was not selection a group ID. When I clicked on it the only option was -- so I didn't think it necessary. I typed a 1 and put them all in the same group and it now works.
thanks,
david
-
6 minutes ago, olehj said:
It might be related.
Anyway, a good place to start is "Force scan all" and if that does't work: delete the database and reinstall the plugin. And -wait- until the plugin says it's installed/done. It may take some time depending on how many drives it needs to check and wake up from standby.
I removed the plugin and the sqlite database from the flash. Re-installed and I can see the scan find my drives. I then add a Disk Layout of 1x16. In the configureation tab I see the layout and drives.
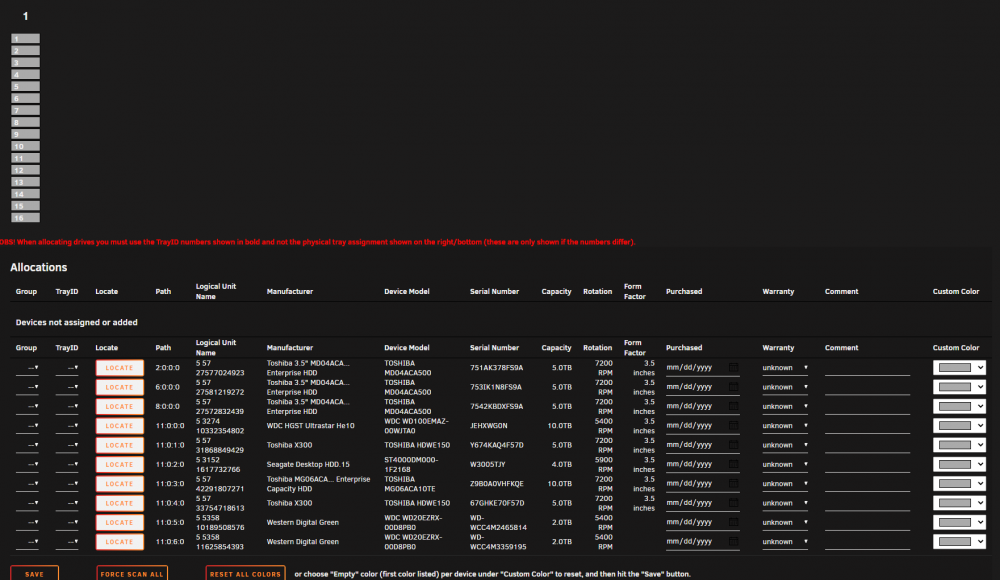
I then select the trayID for a drive and hit save. It goes off and when it comes back nothing changes.
I'll just wait until 6.9 goes GA. I had to switch because of my SSD drives.
thanks
-
49 minutes ago, olehj said:
As said before, I do not support alpha/beta/rc versions. Mainly only the current stable (after I bother installing it myself obviously).
Not concerned about no nvme drive. It seems that others can actually update the tray numbers, which I can't do either.
-
Just installed, running 6.9.0-rc2.
It scans and finds my non-nvme drives, but when I go to assign them to a trayID the save button doesn't do anything. It just resets the trayID settings back to -- and nothing else.
ideas on how I can figure out why?
One small update: When scanning it does find my nvme drive in the window that pops up, but it never appears in the device list.
thanks
david
-
I just upgraded my cache from spinning disk to M.2 SSD.
I've now been monitoring the writes to the cache and see that a lot of dockers update their log files, which in my case are stored on the cache drive. LetsEncrypt is a bad one as it updates its access.log file every 3-4 seconds. This results in what appears to be a lot of writes to the disk.
Is this of concerns? The writes are very small as the log file is just getting appended to.
How does everyone else handle log files from docker? Just ignore it because is isn't a real issue. Write to the /var/log area in the ram disk? Maybe log rotate them to cache for backup?
Just curious,
david
-
I'm seeing more error reports. Ideas?
2021/01/06 13:27:25 [error] 431#431: *4765522 user "root" was not found in "/config/nginx/.htpasswd", client: 37.46.150.24, server: _, request: "GET / HTTP/1.1", host: "<myExternalIP>:443" 2021/01/06 13:27:33 [error] 430#430: *4768442 user "root" was not found in "/config/nginx/.htpasswd", client: 37.46.150.24, server: _, request: "GET / HTTP/1.1", host: "<myExternalIP>:443" 2021/01/06 13:27:54 [error] 431#431: *4770435 user "report" was not found in "/config/nginx/.htpasswd", client: 37.46.150.24 , server: _, request: "GET / HTTP/1.1", host: "<myExternalIP>:443" 2021/01/06 13:28:05 [error] 431#431: *4770753 user "admin" was not found in "/config/nginx/.htpasswd", client: 37.46.150.24, server: _, request: "GET / HTTP/1.1", host: "<myExternalIP>:443" 2021/01/06 13:28:23 [error] 430#430: *4772463 user "admin" was not found in "/config/nginx/.htpasswd", client: 37.46.150.24, server: _, request: "GET / HTTP/1.1", host: "<myExternalIP>:443" 2021/01/06 23:03:22 [crit] 430#430: *403730 SSL_read_early_data() failed (SSL: error:141CF06C:SSL routines:tls_parse_ctos_ke y_share:bad key share) while SSL handshaking, client: 192.241.221.196, server: 0.0.0.0:443
I have no idea what client is 37.46.150.24
david
-
Today I noticed that nginx is running at ~60% CPU constantly.
I do see a lot of these messages in the nginix/error.log
2021/01/05 21:15:50 [error] 431#431: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:15:50 [error] 430#430: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:15:55 [error] 431#431: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:15:55 [error] 430#430: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:16:00 [error] 431#431: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:16:00 [error] 430#430: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:16:05 [error] 431#431: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:16:05 [error] 430#430: send() failed (111: Connection refused) while resolving, resolver: 127.0.0.11:53 2021/01/05 21:16:10 [error] 431#431: r3.o.lencr.org could not be resolved (110: Operation timed out) while requesting certificate status, responder: r3.o.lencr.org, certificate: "/config/keys/letsencrypt/fullchain.pem"thanks,
david
-
OK I guess I really screwed things up.
exactly what I didn't want to do.
Here is what cache is saying now. The second balance happened, but btrfs is still running keeping me from stopping the array.
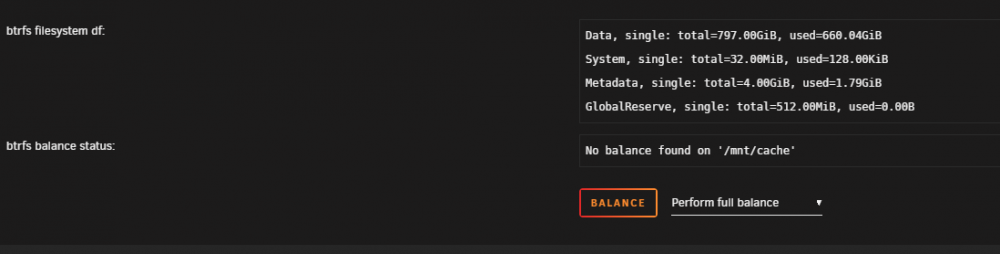
It also now says single instead of Raid1. I can't show a picture of the main page because I can't stop the array. But I have cache pool set to 2 slots, and the first slot is this drive, and the second is set to no device.
How do I recover? The system is running, but I see a lot of these in the log file:
For clarity sake, the old cache drive is sdf.
Jan 5 15:23:58 tower kernel: BTRFS info (device sdf1): relocating block group 4975807692800 flags data Jan 5 15:24:14 tower kernel: BTRFS info (device sdf1): found 8 extents Jan 5 15:24:15 tower kernel: BTRFS info (device sdf1): found 8 extents Jan 5 15:24:15 tower kernel: BTRFS info (device sdf1): relocating block group 4973660209152 flags data Jan 5 15:24:31 tower kernel: BTRFS info (device sdf1): found 8 extents Jan 5 15:24:32 tower kernel: BTRFS info (device sdf1): found 8 extents Jan 5 15:24:32 tower kernel: BTRFS info (device sdf1): relocating block group 4971512725504 flags data Jan 5 15:24:48 tower kernel: BTRFS info (device sdf1): found 8 extents Jan 5 15:24:48 tower kernel: BTRFS info (device sdf1): found 8 extents Jan 5 15:24:49 tower kernel: BTRFS info (device sdf1): relocating block group 4969365241856 flags datathanks
david
-
the balancing finished. I then stopped all dockers, stopped the array. Changed the cache to only have the new drive and restarted the array.
It is now doing a balancing again. Is this expected?
I can see the data mounted.
-
5 hours ago, JorgeB said:
You can also do an online replacement, but note the bold parts about single device replacement.
I backed up the drive using the CA plugin, then started this last night. It is now about 93% done.
thanks
-
I've read the wiki on replacing a cache drive but am not sure I understand what is being asked and why it is necessary.
I have a 2TB spinning disk for cache formatted with BTRFS. It is in the system and running fine. I also installed a new 2TB SSD M.2 drive that I want to move everything from cache over to. I have VM, docker, mysql, etc on the cache drive.
I was planning on stopping VM, dockers, and the array.
format the new drive
copy everything from the old drive to the new drive
assigning the new drive as cache
starting everything back up.
The wiki talks about using mover to move things, or adding the new drive to the cache pool and having balancer do things. I assume the default setting for a cache pool is to mirror the data across both disks?
I'd prefer doing this the "recommended way" but have concerns. I really don't want to screw it up and have to rebuild everything from scratch.
thanks,
david
-
Maybe this can help?
If I run ps on it I see:
12316 5624 root root find find /mnt/cache/appdata -noleaf
Anyone know who/what would be running find on my appdata with the -noleaf option?
david
-
When my server has issues I open a console and look at the processes with top in an attempt to figure out what is going on.
However, since every docker runs things as root, I can see many process running, all owned by root. A common one is find. Now how do I figure out which docker, or the unRaid OS itself is running find and why? I do have my mover scheduled to only run at 1AM so I don't think it is unRaid.
So how does everyone else deal with this? Can you setup the dockers to have their own user and create a user for each docker by name? I could then at least see which docker owns which process.
Currently I'm trying to debug why my minecraft server is lagging and shutting down. It has 16GB of memory allocated, but only uses 5GB. I've pinned it to a specific core. I do see mysqld and find running constantly and large wa states. I think this is the cause of the minecraft server shutting down do to "lag".
thanks
david
-
Anyone still running this docker? When I try to go to the web address [IP]:5060 it doesn't connect to anything.
The log appears as if it is running:
time="2020-12-01T21:32:30-05:00" level=info msg="Cardigann dev" time="2020-12-01T21:32:30-05:00" level=info msg="Reading config from /.config/cardigann/config.json" time="2020-12-01T21:32:30-05:00" level=info msg="Found 0 indexers enabled in configuration" time="2020-12-01T21:32:30-05:00" level=info msg="Listening on 0.0.0.0:5060"I can get a console and run a query, though it errors out because I don't have anything configured.
suggestions?
Update: port 5060 is blocked by current browsers so I changed the host port from 5060 to 5070 in the settings and it works fine now.
-
############################################################################################################################ # # # unRAID Server Preclear of disk 31454B4A52525A5A # # Cycle 1 of 1, partition start on sector 64. # # # # # # Step 1 of 5 - Pre-read verification: [27:36:54 @ 100 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [31:47:24 @ 87 MB/s] SUCCESS # # Step 3 of 5 - Writing unRAID's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying unRAID's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: FAIL # # # # # # # # # # # # # # # ############################################################################################################################ # Cycle elapsed time: 45:44:54 | Total elapsed time: 45:44:54 # ############################################################################################################################ ############################################################################################################################ # # # S.M.A.R.T. Status (device type: default) # # # # # # ATTRIBUTE INITIAL STATUS # # 5-Reallocated_Sector_Ct 4 - # # 9-Power_On_Hours 57 - # # 194-Temperature_Celsius 34 - # # 196-Reallocated_Event_Count 4 - # # 197-Current_Pending_Sector 8 - # # 198-Offline_Uncorrectable 0 - # # 199-UDMA_CRC_Error_Count 0 - # # # # # # # # # # # ############################################################################################################################ # SMART overall-health self-assessment test result: PASSED # ############################################################################################################################ --> FAIL: Post-Read verification failed. Your drive is not zeroed.I also see an error in the log file
Aug 5 11:21:24 tower preclear_disk_31454B4A52525A5A[39727]: Post-Read: dd output: 2581222916096 bytes (2.6 TB, 2.3 TiB) copied, 11381.9 s, 227 MB/s Aug 5 11:21:24 tower preclear_disk_31454B4A52525A5A[39727]: Post-Read: dd output: dd: error reading '/dev/sdl': Input/output error Aug 5 11:21:24 tower preclear_disk_31454B4A52525A5A[39727]: Post-Read: dd output: 1230825+1 records in Aug 5 11:21:24 tower preclear_disk_31454B4A52525A5A[39727]: Post-Read: dd output: 1230825+1 records out Aug 5 11:21:24 tower preclear_disk_31454B4A52525A5A[39727]: Post-Read: dd output: 2581228163072 bytes (2.6 TB, 2.3 TiB) copied, 11391.3 s, 227 MB/s Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 5 Reallocated_Sector_Ct 650 Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 9 Power_On_Hours 103 Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 194 Temperature_Celsius 40 Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 196 Reallocated_Event_Count 650 Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 197 Current_Pending_Sector 8 Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 198 Offline_Uncorrectable 0 Aug 5 11:21:25 tower preclear_disk_31454B4A52525A5A[39727]: S.M.A.R.T.: 199 UDMA_CRC_Error_Count 0I've run this two times with the same resilts. it is a brand new hgst 10TB druive.
ideas?
david
Edit: as this now has 650 reallocated sectors, after two attempts. I'm just returning the drive.
-
5 hours ago, BRiT said:
Then you're running Plex Plugin and not Plex Docker ?
Nope, never ran a plugin for plex. Just the linuxserverio plex docker.
Hence my confusion.
-
1 hour ago, saarg said:
If the plex container is stopped, plex is not running. Where do you see a plex process? Have you installed plex as a plugin at one point and forgot about it?
I ran open files. It is a script that runs to tell you what processes have open files. These open files keep the OS from unmounting the drives.
I could also run top, ps -aux | grep Plex, any number of ways to see the process. I tried kill -9; kill -15, but the process always got restarted. Dockers were turned off as well, but some daemon was restarting plex.
I've seen this a couple times now, when I stop the array before all dockers have finished starting.


[Deprecated] Linuxserver.io - CouchPotato
in Docker Containers
Posted · Edited by lovingHDTV
The last post to that forum was 3 years ago
UPDATE: I tried it again later and it just worked. who knows what went wrong