




lovingHDTV
Members
-
Joined
-
Last visited
Everything posted by lovingHDTV
-
I'm trying to add an eac3 audio to all my movies with TrueHD audio. I tried to use Add Audio Stream Codec, but it doesn't do anything. It processes the file, but says nothing needs to happen. When I google around it mentions a Tdarr_Plugin_075a_FFMPEG_Audio, but I don't see that plugin in the container. This has got to be a common request, any help on how to get it working? I have a TV that doesn't support truehd so for that TV I want eac3 available. thanks
-
It worked. Wouldn't be a bad idea to provide a few more details to the wiki. I now have one of 8 14TB drives upgraded to v5. It will take several weeks to months to migrate all the files to get them all swapped out. But the first one is important. thank you for all the help.
-
The rebuild will finish in 12 hours. I'll try again after that comlpetes. So I ensure the drive is still empty stop the array start the array in maintenance mode ERASE Start array in normal mode Format <does it now rebuild again?>
-
I copied all the data off, following the directions on the Wiki. Stop the array, mark as empty, start array, hit mover, verified the disk has no files. I stopped the array, removed the drive (because I wanted to upsize it). I precleared the replacement drive, add it to the array and it started a rebuild. I stopped the array manually formatted with: mkfs.xfs -m crc=1 /dev/sde -f start the array and it rebuilds. Do I have to remove the drive from the array completely, rebuild, then add the new drive? thanks
-
How do I update a drive that is already in my system and not have the rebuild process just revert it back to XFXv4? I even manually formatted it to v5 and it just reverts as soon as the rebuild happens (automatically). Also, is there anyway to do this without having to rebuild the array for every drive?
-
-
I plan to swap out two 5TB drives with two 14TB drives. Can I take this opportunity to also ensure the new drives are v5 instead of v4? Can this be done by changing out to the new drives and rebuilding, or do I need to move everything off the soon to be retired 5TB drives prior to replacing them. thanks
-
Thank you! I missed that when I chose br0.10 I needed to specify a static IP address. Everything up and running. I don't care if it is a dedicated IP, I Just wanted it on the 192.168.10.0 subnet.
-
I couldn't find a place in the Docker section to ask this question as it doesn't pertain to a specific docker, more how containers interact with each other and networking. I run gluetun and run my *arr, etc programs through that docker. One of the ports used is port 8000 seen here: This is all on the bridge network or 192.168.1.0. This all works fine. I want to install the Spoolman docker on the br0.10 network. It uses port 8000 that I set to 7912 in the template: This work fine as, I can access it via 192.168.1.107:7912. I want that to run on the br0.10 network as well, but when I set it to that network it doesn't work: For other containers when I use the br0.10 it works fine. Is this caused by the port 8000 conflicting with gluetun? The other containers use non-coflicting ports. Like this; Any help would be appreciated. I don't really understand all the docker networking. I'm hoping to get Spoolman to run on the br0.10 network. thanks david




-
Yes, this is what I'm doing and had a clash. In other ones I just change the ports to not clash and move one. That didn't work with this container, but my qbittorrent container did so I just resolved the clash with it. It's all working find now. Downloads great.
-
My network type is None as I run it through GlueTun or are you referring to a different network called bridge?
-
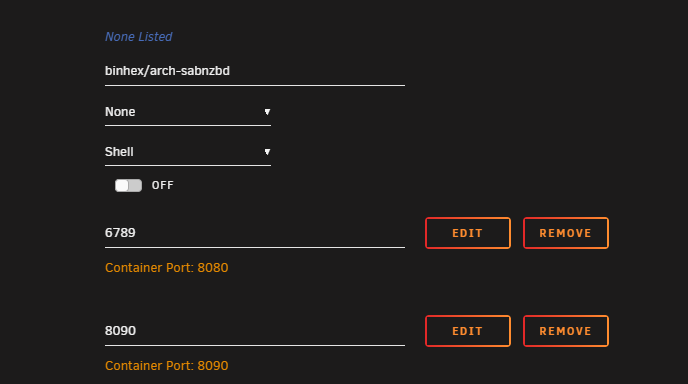
I have mapped my 8080 port -> 6789 to avoid a conflict with qbittorent, but it still runs on 8080. When I look at the details I see: 8080 does indeed work, but why isn't it 6789 instead? My fix was to move qbittorrent instead and that works perfectly. Seems something is broken with this docker.
-
for the last month I've got about a 90% failure rate. They all download, but die downloading PAR files. I spoke with a friend that uses the same newserver and he doesn't have issues.
-
When you say "restore the key". I just copied it back to the root dir of the flash drive.
-
No Key, this it gave the flash GUID I see the gUID on my account purchases, but I have no keys associated with my account.
-
My flash drive started not booting, don't know why. So I copied everything to my desktop and re-installed using the installer. I then copied my Basic.key back to the drive, but it still says I need to register. It is the same flash drive, so what do I need to do? thanks david
-
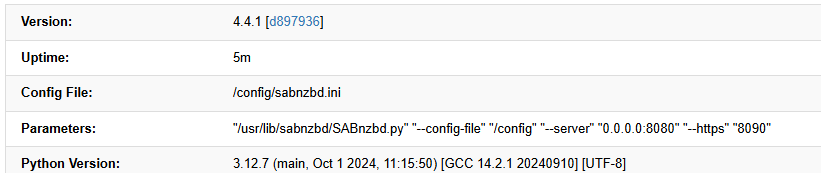
I just updated today and now it no longer can connect to my servers. Worked before the upgrade. Anyone else having this issue? I see nothing odd in the log file. Website works, etc, but when I try to download anything it just fails. I don't see any details in the log file. Can someone point me to a better log than supervisord.log?
-
Perfect. I was hoping that would be the case and it worked. It is already precleared.
-
Is there a way to just verify the signature? I'm pretty sure I precleared the drive earlier, but would like to verify the signature. I see it in unassigned devices, but in the GUI all I get is the start preclear option. Don't want to hit it as I'm afraid I'll have to start the 3 day preclear process over and not need to. thanks
-
I've two containers that have shown No Available for a couple weeks now. Both are available when I go to the docker page. One is the official ESPHome: https://hub.docker.com/r/esphome/esphome The other is my own here: ghcr.io/dpeart/heatmaster:main How do I figure out why? I know that ESPHome has been updated and I need the update. Not as concerned about mine as I've not changed it. thanks david
-
guess I'll order a new usb. I bought a 256GB one and apparently UnRaid is limited to 32GB.
-
as in I should replace my flash? I bought a new one a while ago with the intent to swap it out, just haven't figured out how to do it now that it is automated. I guess it is time to figure that out.
-
I saw this in the sylog I attached. This is the syslog from before the hang/reboot. Dec 19 02:42:34 tower emhttpd: Unregistered - flash device error (ENOFLASH7) Dec 19 02:42:34 tower emhttpd: error: device_read_smart, 8372: Cannot allocate memory (12): device_spinup: stream did not open: sdj Dec 19 02:42:34 tower emhttpd: error: device_read_smart, 8372: Cannot allocate memory (12): device_spinup: stream did not open: sdk Dec 19 02:42:34 tower emhttpd: error: device_read_smart, 8372: Cannot allocate memory (12): device_spinup: stream did not open: sdh
-
This AM the server was unresponsive. I could ping it, but could not log in. Even when trying to log in via the console, it would accept the user name, then just return to the login prompt. I had a bunch of messages on the console that said something about monitor_nchan had issues with local resources. I had to hard reboot it, ugh, it is back up. Attached are the diagnostics. I looks like there are some drive errors, like for all the drives. Any help appreciated. I had the syslog server going so here is the syslog. thanks tower-diagnostics-20221219-0623.zip syslog-192.168.1.107.log
-
OK, moved to ipvlan. Hopefully this resolves the random system hangs, and BTRFS issues. thanks for your help






