




lovingHDTV
Members
-
Joined
-
Last visited
Everything posted by lovingHDTV
-
I just upgraded and now my 1.17.1 and papermc 1.17.1 servers wont start. Any idea where I can look at a log file to figure out why? thanks david
-
How do I connect to the console via rcon-cli? Is it possible? thanks
-
For years I've had a sshd docker setup to support remove backups. In the docker I set a guid:uid and limit access to only the Backup share on the array. I setup keys public/private for authentication that are stored in appdata directory. Is there a more native approach with ssh today? I know that sometime ago there were changes made to the ssh support, but it seems allow access to the entire server which I don't want. thanks david
-
I found that some files in the setup area were owned by root. I changed them to nobody/user and now it is running. Go figure. . .
-
after a good nights sleep I figured out what is going wrong. I don't know why it fails, but have fixed it. My nzbgetvpn docker is failing to start, so I open a console in that docker and run the /home/nobody/watchdog.sh to start it. That gets done as root, because the console login is root. This then means all the downloads are also owned by root/root. This is causing sonarr to fail, even though it has full access to all the files/directories when I log into the sonarr console. Because the console login is root. I'm sure as nobody/users it wouldn't have access to remove the original download. After changing ownership of the downloaded files, it runs fine. So I just need to figure out how to switch to be user nobody in a docker console so I can really test things.
-
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='nzbgetvpn' --net='bridge' --privileged=true -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'VPN_ENABLED'='yes' -e 'STRONG_CERTS'='no' -e 'VPN_USER'='' -e 'VPN_PASS'='' -e 'VPN_REMOTE'='jfk-029.ovpn' -e 'VPN_PORT'='1194' -e 'VPN_PROV'='custom' -e 'VPN_PROTOCOL'='tcp' -e 'LAN_NETWORK'='192.168.1.0/24' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:6789]/' -l net.unraid.docker.icon='https://raw.githubusercontent.com/binhex/docker-templates/master/binhex/images/nzbget-icon.png' -p '6789:6789/tcp' -v '/mnt/disks/LocalBackup/docker-settings/nzbgetvpn/downloads':'/data':'rw' -v '/etc/localtime':'/etc/localtime':'ro' -v '/mnt/disks/LocalBackup/docker-settings/nzbgetvpn/downloads/complete':'/data2':'rw' -v '/mnt/disks/LocalBackup/docker-settings/nzbgetvpn':'/config':'rw' 'jshridha/docker-nzbgetvpn' I posted in the nzb support page because I have to get into the console and start nzbget manually to get it to run. I just run the same command that the docker runs when it starts. Seems like permissions issue as well.
-
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='binhex-sonarr' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'PUID'='99' -e 'PGID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8989]/' -l net.unraid.docker.icon='https://raw.githubusercontent.com/binhex/docker-templates/master/binhex/images/sonarr-icon.png' -p '8989:8989/tcp' -p '9897:9897/tcp' -v '/mnt/disks/LocalBackup/docker-settings/nzbgetvpn/downloads/complete/':'/data2':'rw' -v '/mnt/cache/appdata/sonar/config':'/config':'rw' -v '/mnt/disks/LocalBackup/docker-settings/deluge/downloads/':'/data':'rw' -v '/mnt/user/TV Shows/':'/media':'rw' 'binhex/arch-sonarr'
-
Still trying to recover from my docker drive crashing. The restore of the appdata didn't actually restore everything to working order. Now trying to figure out why Sonarr will import a TV show, then delete it, then report: 2021-10-19 21:50:27,703 DEBG 'sonarr' stdout output: [Warn] ImportApprovedEpisodes: Couldn't import episode /data2/tv/SEAL.Team.S05E01.PROPER.1080p.WEB.H264-STRONTIUM/MfAu8zfkfBJBYcphntDPTgvz.mkv [v3.0.6.1342] System.UnauthorizedAccessException: Access to the path '/data2/tv/SEAL.Team.S05E01.PROPER.1080p.WEB.H264-STRONTIUM/MfAu8zfkfBJBYcphntDPTgvz.mkv' is denied. ---> System.IO.IOException: Permission denied I can see it copy the file over to the array, so those permissions are fine, then it just deletes it. It is doing that constantly for all 15 files waiting to be imported. Just copy/delete rinse and repeat. Any ideas as to what the permission issue it is referring to?
-
Oddly I can just run /home/nobody/wathdog.sh and it will run when I do it from the command line. When run from the system nzbget fails to run.
-
My docker drive crashed so I had to rebuild all my dockers. When I try to start the docker it connects to VPN fine, but the server wont start. I get the message: 2021-10-19 13:00:15,888 DEBG 'watchdog-script' stdout output: [info] Attempting to start nzbget... 2021-10-19 13:00:26,999 DEBG 'watchdog-script' stdout output: [warn] Wait for nzbget process to start aborted, too many retries If I get a console for the docker and run nzbget -c nzbget.config -D it runs just fine. Any ideas on why it won't run when the docker starts? I'm not sure where to fine a log file that might help. thanks david
-
I had a second 2TB drive I had installed to make a pool for my docker stuff. I just brought that online and it all worked as planned. thanks
-
I was just posting that I see that sdi is gone. Yes that is where my docker.img is stored along with all my dockers. So how best to recover? Two days ago I installed the new version of the docker backup script and did a complete backup to disk7. I moved all my dockers from my cache drive because I had swapped it to an SSD and it was getting an insane number of writes. How would you recommend me recovering? As I installed docker when it first came out, I've not kept up on what is the recommended way to do it any longer. Back then you couldn't have it on in share on the array. Is that still the case? thanks
-
This AM I noticed two dockers quit running over night. I would get Execution Error 403. I googled around a bit and it seems that my docker image was corrupted. So I followed the instructions to recreate it and re-install all my previous dockers. It never returned from a installing that last docker so the prompt/log window never went away. I rebooted the server and when it came back up it started a parity check which I have paused. I was able to start the first two dockers, then hit run all. Now it is just hanging and nothing is starting. Not sure what is going wrong, but here are my diagnostics. thanks, david tower-diagnostics-20211017-1118.zip
-
One thing I wanted to be able to see/monitor in the node exporter is the network traffic based on the docker. Today it lists all the veth<number> values, but I have no way to know how they map to the dockers. I found this plugin: ❚❚ [Plugin] Network Stats - Page 11 - Plugin Support - Unraid That has a script that can do the mapping. Is it possible to have do this mapping for the Promethius data so that what we see in the Graphana dashboard says the docker name instead of the veth<number>? If the veth<number> changes everytime the docker restarts, is the historical data valid? thanks david
-
hmm, just clicked the support link in the plugin. Let me go check. Yep, upgrading to new plugin. thanks
-
I'd like to exclude the download sub-folders in my nzb and deluge docker directories. The file browser to select exclude directories doesn't allow me to select subfolders. Is it possible to add them manually some way? I don't need to backup the gigabytes of data in these subfolders. I just want the config data.
-
Just added a ER605 and TL-SG2008P. Had an issue where the ER605 defaults to 192.168.0.1 and I use 192.168.1.1. There is a support FAQ at TP-Link that tells you how to get Omada to adopt the router. Other than that, not a docker issue, it worked great. I also just noticed that this docker supports non Host networking so I can assign a dedicated IP to the docker. Very nice indeed. Thanks again
-
The last post to that forum was 3 years ago UPDATE: I tried it again later and it just worked. who knows what went wrong
-
the docker just stopped working for me. when I try to download a movie I get: 07-15 10:32:20 ERROR [chpotato.core.plugins.log] API log: {'file': u'http://HOST/couchpotato/static/scripts/combined.plugins.min.js?1580803031', 'message': u"chrome 91: \nUncaught TypeError: Cannot read property 'length' of undefined", 'line': u'1288', 'page': u'http://HOST/couchpotato/movies/', '_request': <couchpotato.api.ApiHandler object at 0x14fda2805d90>} and it no longer issues the search to the indexers. It worked a couple weeks ago, but I have updated since then. I'm currently up to date. Ideas?
-
Just wanted to say thanks. Works great. Backed-up my current config, stopped older version, installed this, imported my backup, and updated the firmware for all my access points. worked perfectly. thanks
-
I had three severs defined and they worked fine. I upgrade all my dockers and to 6.9.1 (was 6.9.0-RC<something>) and now mineos only shows the one server I added most recenlty. I do see them in the games area, their backups are there as well. Ideas on why Mineos has lost track of them? thanks
-
No was not selection a group ID. When I clicked on it the only option was -- so I didn't think it necessary. I typed a 1 and put them all in the same group and it now works. thanks, david
-
I removed the plugin and the sqlite database from the flash. Re-installed and I can see the scan find my drives. I then add a Disk Layout of 1x16. In the configureation tab I see the layout and drives. I then select the trayID for a drive and hit save. It goes off and when it comes back nothing changes. I'll just wait until 6.9 goes GA. I had to switch because of my SSD drives. thanks
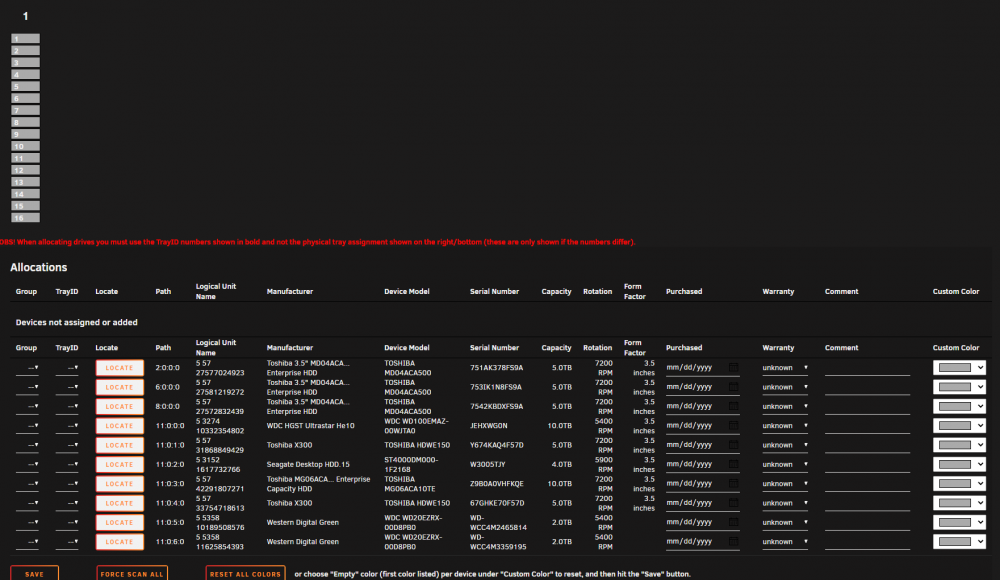
-
Not concerned about no nvme drive. It seems that others can actually update the tray numbers, which I can't do either.
-
Just installed, running 6.9.0-rc2. It scans and finds my non-nvme drives, but when I go to assign them to a trayID the save button doesn't do anything. It just resets the trayID settings back to -- and nothing else. ideas on how I can figure out why? One small update: When scanning it does find my nvme drive in the window that pops up, but it never appears in the device list. thanks david

