




jfrancais
Members
-
Joined
-
Last visited
Everything posted by jfrancais
-
Nope. Still hung up. if I navigate into the container I can see everything, but the connected clients can not. I feel like it is a routing issue or something for the NATed ips but I'm not skilled enough in the networking side to go any further and it seems like no one else is running into this issue.
-
Still struggling a bit on OpenVPN-AS docker config but I have made some progress. I now have my OpenVPN-AS running in host mode. Docker containers are on br1 (running on the second NIC) with assiged IPs. If I shell into the OpenVPN-AS container I can communicate with everything, the host and all the containers. Clients connected to OpenVPN server can communicate to the unraid host and all the network except for the docker containers in br1. I feel like this is a routing issue that should be fixable. Can anyone provide assistance? I'm really weak on the networking side of things.
-
Still struggling on getting the OpenVPN Docker working properly when configured with it's own IP. Does anyone have it working in this scenario?
-
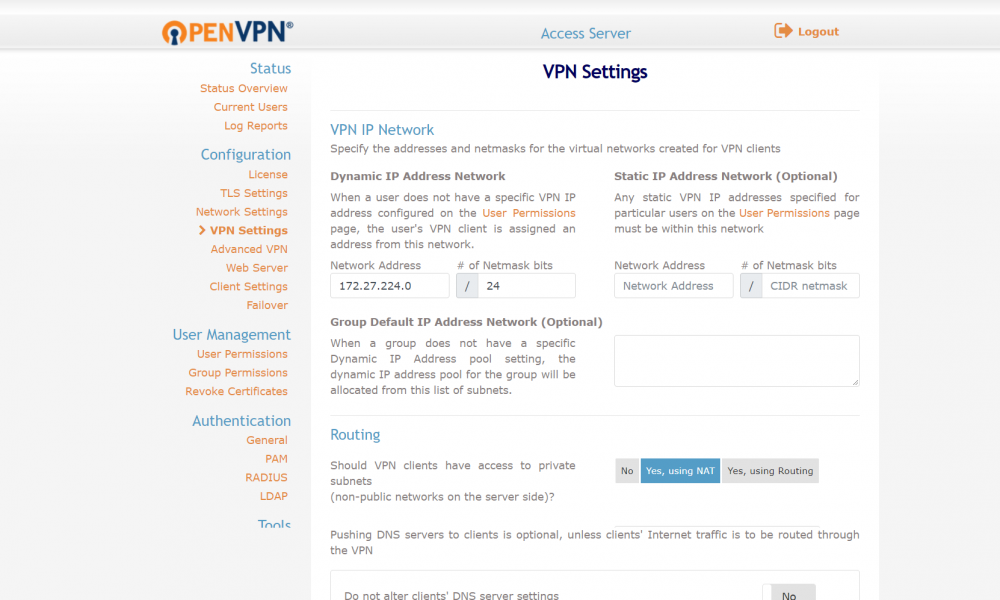
Gotcha, unsure why that wasnt in my screenshot, private subnets should be given access to there is: 172.27.224.0/24 192.168.1.0/24 So I believe I have it set like you are suggesting and still doesnt work
-
I dont follow you. Where are you putting this?
-
No. I can ping that address but if I go to http://172.27.224.1:943 I get timed out and nothing comes back
-
Ok, Sorry, I finally got back to this. Just to rehash. I now have 2 nics in my unraid server. I removed the br0 network. I created the br1 network with the eth1 nic in it (eth0 is the unraid server primary nic). I moved all my docker containers with static IPs into br1. I shelled into the openvpn-as container and verified I can ping the unraid host and my main network router by ip and by DNS name. I can do dns lookups (dns server is my main router 192.168.1.1) so it appears I have the docker problem worked around. Problem is, my openvpn connected clients still cant access resources. Once connected to the vpn I am still having connectivity issues. The VPN clients cant ping or access the unraid host (192.168.1.207). They can ping my main router (192.168.1.1) and other docker containers by ip (headphones container at 192.168.1.57 for example). They can't do DNS resolution at all (tried nslookup tool using 192.168.1.1 as name server but it times out, same as using 8.8.8.8 as name server). I have attached screen shots of what I think would be useful settings. Any assistance would be appreciated. I'm banging my head against the wall on this.
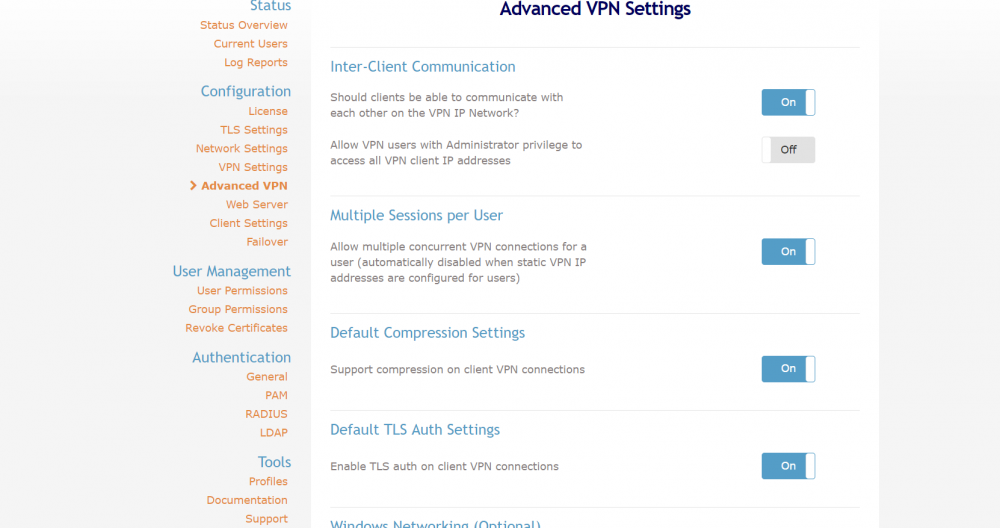
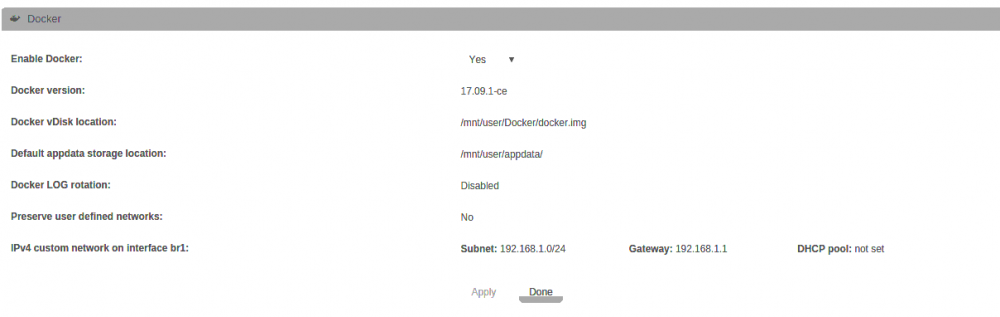
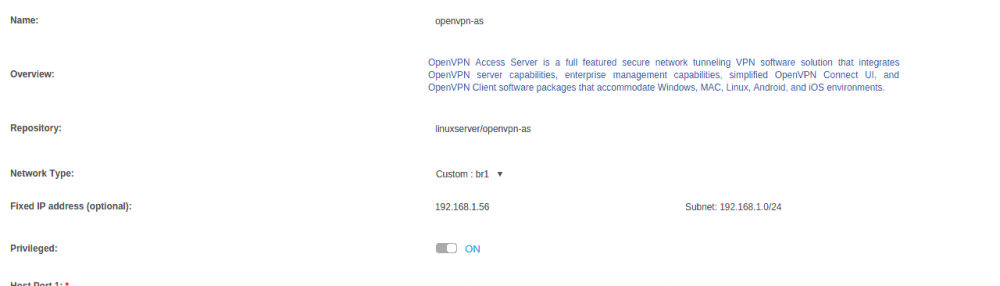
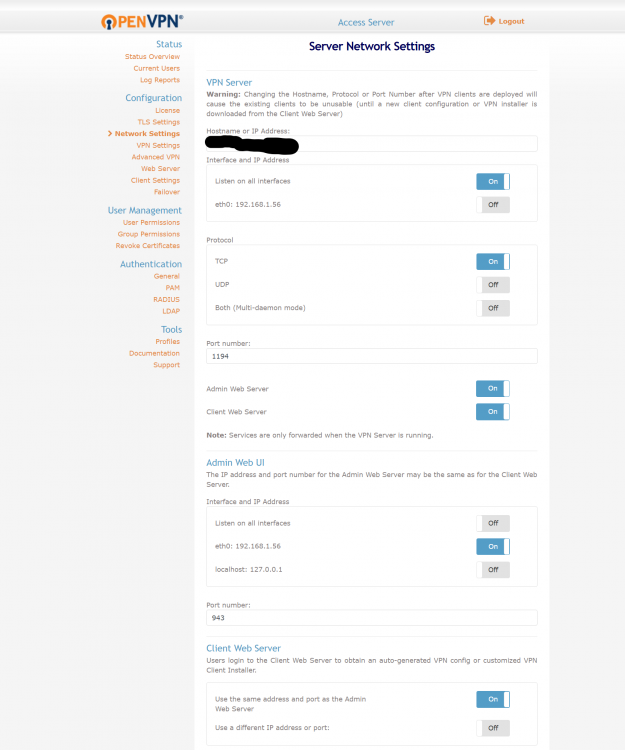
-
Got a little further, when I set my OpenVPN-AS to TCP (disabled UDP) I can now connect to the OpenVPN-AS server from the outside world. I have the exact same issue as before. When I connect the OpenVPN-AS server docker container that is setup to use br1 and an assigned ip, VPN clients can talk to other docker containers on br1 but not unraid host, router or internet.
-
OK, I got my br1 up and running. I have moved my docker containers to br1 with static IPs. The Docker containers can talk to each other as well as the unraid host, containers that are on host/bridge network and the internet. Still having issues with the OpenVPN-AS config. When I leave the OpenVPN-AS docker container on host network and set my router to direct VPN ports to my unraid server IP, from the outside world I can connect to VPN server, access router, unraid server ip and internet but I cant talk to docker containers on br1. When I switch the OpenVPN-AS container to br1 and give it an IP and adjust the router to push ports to this new IP, I cant connect to it from the outside world. OpenVPN client sits at connecting.
-
Ok I added a second NIC. It is unplugged from lan. Has no ip. In unraid gui i disables bridging on eth0 and enabled on eth1. Docker containers can’t select br1 as an option. Network settings show link as down (because it is unplugged). What am I missing?
-
The bolded looks interesting. my router's VLAN support isnt reliable and I don't have a second NIC in my server. This method looks like it would be a good alternative to usign a full VM for my OpenVPN server. Could you provide some specifics on this?
-
You may have been referring to me. I'm having this issue. It is expected behavior. dockers with their own IP will be able to talk to each other but not other docker containers with host IP by design. I have moved my OpenVPN docker to its own IP as well, but I'm struggling to get the VPN connected clients to talk to anything other than the br0 containers in this scenario. As for why we want them on their own IP, well for me I have a few services that run the same port and I prefer to not redirect the port to something else. And if you even have 1 docker container using its own IP your VPN connected clients cant talk to them when running as a docker. Kind of the point of a VPN server. Unfortunately my search thus far has been fruitless and I may have to go back to OpenVPN as a VM instead of a docker container.
-
Has anyone successfully got their OpenVPN-AS Docker running on network type br0 with it's own IP? Still struggling to get my clients communicating properly and I don't want to switch back to a full VM if I don't have to.
-
In the docker settings for openvpn-as I have network type set to br0, fixed ip address set to 192.168.1.56 and INTERFACE variable set to eth0. With this, VPN clients can connect to my VPN and can access my other docker applications that are also setup on br0 but they cant access the internet or any other part of my LAN. If I set the docker settings for openvpn-as to have a network type of bridge, VPN clients can still connect, can access the internet and other parts of my LAN but none of the docker images on br0 (which is expected, that is why I'm trying to move the openvpn-as docker to br0). trouble shooting br0 scenario using: docker exec -it openvpn-as /bin/bash and I can curl http://www.limetech.com and get a response and I can curl http://192.168.1.1 (gateway) and http://192.168.1.50 (a docker on br0) and also get results. But to my connected VPN clients I can't see gateway or external internet.
-
I don't think it is an OpenVPN settings issue. I think it is a problem with the docker bridging. When openvpn-as is set to use br0, I can connect to VPN, and I can access all my other dockers that use bridging, but can't access the internet or other machines on my network. When I set openvpn-as to use standard eth0 I can connect to VPN, access internet and other resources, but can't access any of the other docker images that use br0 networking.
-
Still struggling with this. Any thoughts? with my other docker services running on real IP addresses and not accessable from my VPN, it is rendering my VPN largely useless
-
unraid is on 192.168.1.207 openvpn docker is 192.168.1.56 routing setting is set to all clients to have access to 192.168.1.0/24 (yes using nat) So I believe everything should be correct on that front. Further to this, I accessed the shell of the docker image and was able to access the internet (curl http://www.canoe.ca returns the canoe website) and the other docker containers (curl http://192.168.1.55 returns my default nginx page from that docker) via the console. cant access the unraid server ip (curl http://192.168.1.207 fails to connect) via the docker container so that is consistent with how I would expect it to communicate.
-
You mean put it on bridge networking? I've been there already. That is where I started. OpenVPN-AS was giving out IPs and clients could communicate with my entire network. Once I started putting some of my other docker images in br0, the VPN clients could no longer communicate with those dockers (which makes sense). So now I'm trying to switch OpenVPN-AS to also be on br0, and secondary to that, I want VPN clients to get IPs direct from router. But first I want to get OpenVPN-AS fully working on br0.
-
I'm posting here as I'm looking for assistance myself, my original post was above.
-
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='openvpn-as' --net='br0' --ip='192.168.1.56' --privileged=true -e TZ="America/Regina" -e HOST_OS="unRAID" -e 'TCP_PORT_943'='943' -e 'UDP_PORT_1194'='1194' -e 'INTERFACE'='eth0' -e 'PGID'='100' -e 'PUID'='99' -e 'TCP_PORT_9443'='9443' -v '/mnt/user/appdata/openvpn-as':'/config':'rw' 'linuxserver/openvpn-as' f4eed7625fcff79f6883fe1654b65e439342059d145604c18be7bba9a292b1c9 my router has port forwards for 943, 1194 and 9443 to 192.168.1.56. Unraid network config is set the not enable bonding, yes to enable bridging. members of br0 are eth0. ip4 online, ip address is 192.168.1.207 / 24 and gateway is 192.168.1.1. enable vlans is No. routing table as below: IPv4 default 192.168.1.1 via br0 209 IPv4 172.17.0.0/16 docker0 1 IPv4 192.168.1.0/24 br0 209 IPv4 192.168.122.0/24 virbr0 1 I can communicate with the docker image (see the web interface) and I can connect to the VPN from outside my lan. clients are given an IP from openvpn-as and they cant communicate with anything.
-
I don't see the VPN Mode menu item in the admin area at all, so I don't know how to change OSI layer to 2.
-
So I have had my openvpn docker running well for a quite a while now. Everything is working as expected. But I'm looking at doing a change. I recently switched a few of my docker images to use br0 networking and given their own IP address. Since that time, none of my VPN clients can see those apps running on br0 (which makes sense now that I know that those addresses can't communicate with the host ip). I'd like to make 2 changes to my openvpn docker configuration. I'd like to move it from bridge networking to br0 with its own IP, and I'd like to have the VPN clients get their DHCP information directly from my router instead of assigned from within open VPN (and being NATed). I've yet to get either to work. When I changed the docker config to br0 and give it an IP, clients can still connect and get an IP, but they can't access anything. And I havent found any way to do the DHCP thing. My searching hasnt been fruitful thus far. Can anyone assist?
-
any chance an upgrade to nginx is in the queue? I require ngx_stream_ssl_preread module and ngx_stream_map module. Sounds like those are in 1.11.5
-
OK, I made some head way on stream. I was able to enable stream by adding the following to my nginx.conf file: load_module "modules/ngx_stream_module.so"; Now I'm able to flow my VNC traffic thru. Unfortunately it doesnt help my with my overall goal. I was hoping to do tcp forwarding based on the hostname (IE vnc.address.com and vnc2.address.com would both go to nginx and forward to the appropriate vnc backend. Looks like I need nginx 1.11.5 before I can continue on that path: http://stackoverflow.com/questions/34741571/nginx-tcp-forwarding-based-on-hostname
-
Anyone got stream working? All my searching still seems to point to stream module not enabled.




