




bilbo6209
Members
-
Joined
-
Last visited
-
Itimpi, so I set a minimum on cache and all shares, hit tge mover button again and files are moving. It doesn't seem like this should hit it but it did! I set the use cache back to yes too.
-
I thought prefer was prefer to use the cache, but won't stop transfer if the cache fills up, the files will go to the shares directly instead. I started to adjust the minimum space on the shares.... But if all shares are on all drives won't it always have all free space on the drives? But will this correct the current issue?
-
I build my daughters unraid servers (they live out of state and this gives me off site redundancy and allows them access to some shared files. When I built the severs I threw a handful of drives In, smaller drives thinking I wouldn't mirror that much data.... Well their drives filled up and their cache drives filled up. I have added more data drives and tries kicking off mover to dump the cache data to the new drives and received the error (in the active logging) of "step 3 {time} server name file path Dest path (28) no space left on device" I then used unbalance to move some files off the full drives to the new drives and tried again, same error I changed the cache setting for each share to prefer (I want it this way in the future so transfers don't hang if the cache fills up) Same error I read on a different post to change the split behavior, it was on automatically split, I changed to to all other options and received the same error each time. Does anyone have any other suggestions? The servers are going back out of state tomorrow morning and gaining physical access to them will be out of the option, and we interface access is a pain but doable.
-
Of course this is the one disk I forced a reformat on to get the full 8tb vs the 7.8tb available due to the 4k formatting 🙄 OK ill drop it in a different system with a trial key, what a pain 😞 Thank you JorgeB!
-
Sorry
-
I had some issues with drives and upgraded all my spinning disks.... Changed from 2 very low hour 12tb parity drives and 6 8tb used data drives to new 14tb parity drives, 2 new 14tb data drives and the 2 12tb parity drives becoming data drives. I swapped a new 14tb drive in place of both 12tb parity drives (one at a time and let each rebuild before replacing the next) I the swapped a new 14tb (or the 2 12tb parity) in one at a time and let it rebuild for 4 of the 6 current data drives. I pulled the 2 remaining 8tb data drives and did a new config to remove the 2 8tb drives from the array. Using the unassigned devislces plugin I was able to mount one of the 2 8tb drives and copy data to the array. I have attempted to mount the other 8tb drive and each Time it attempts to mount and fails.... Hitting the log button in the GUI it says "mount of sdl1 failed. Mount /mnt/disks/8tb (mount 2) system call failed: function not implemented. If I look in krusader the mount doesn't show... I have rebooted to ensure it wasn't something hung etc bob-diagnostics-20230719-2217.zip
-
I had some issues with drives and upgraded all my spinning disks.... Changed from 2 very low hour 12tb parity drives and 6 8tb used data drives to new 14tb parity drives, 2 new 14tb data drives and the 2 12tb parity drives becoming data drives. I swapped a new 14tb drive in place of both 12tb parity drives (one at a time and let each rebuild before replacing the next) I the swapped a new 14tb (or the 2 12tb parity) in one at a time and let it rebuild for 4 of the 6 current data drives. I pulled the 2 remaining 8tb data drives and did a new config to remove the 2 8tb drives from the array. Using the unassigned devislces plugin I was able to mount one of the 2 8tb drives and copy data to the array. I have attempted to mountvtge other 8tb drive and each Time it attempts to mount and fails.... Hitting the log button in the GUI it says "mount of sdl1 failed. Mount /mnt/disks/8tb (mount 2) system call failed: function not implemented. If I look in krusader the mount doesn't show... I have rebooted the server today to ensure it wasn't a pending reboot etc I have attached logs so hopefully someone can point me to if this is a OS issue and beings here or if it is a plugin issue and shojkd be posted on their forum bob-diagnostics-20230719-2217.zip
-
That is my fear too.... All internal slots are full 😞 BUT I am condensing a couple drives down onto a bigger drive. All Disks that have logged errors in unraid have been in that disk slot so I'm just going to mark it as bad so I don't use it. Sucks to have a nice hot swap chassis that has a bad slot. As long as it doesn't spread to other slots I can live with it. Thanks for your help JorgeB!
-
Well I'm back, The initial disk has been solid, full smart test (2 corrected delayed read errors taht have been there for a while) and copied 2 or 3tb of data to the drive with no issues. BUT the replacement drive has no smart errors, but unraid is reporting almost 22,000 errors 😞 My guess is the servers backplane has a flakey port etc... But I have attached the diags for anyone who wants to look and make any suggestions! bob-diagnostics-20230702-1619.zip

-
the diags are after the disk was disabled so no diags from when the disk was throwing the errors in unraid. I had to reboot the server due to another issue I have another thread opened for (error showing unraid is unable to write to /usr/local/ and basically stops unraid from accessing github, updating plugins/dockers etc, and causes an unclean shutdown and parity check when using the reboot or shutdown option in the gui) i can try doing a preclear, on the disabled drive and see what it does. I just rebuilt the data on a different drive and would really rather not put the disabled drive back in and rebuild again. I dont know if I will see the errors if the disk is unassigned.
-
If these are "nothing to worry about" why did disk 5, with only 2 corrected delayed read errors, throw over 1.5 million errors in unraid while rebuilding data (drive replaced) and unraid disabled the drive? Sorry not trying to be confrontational just trying to understand why a drive with so few errors that are usually "nothing to worry about" would be toasted by unraid.... While I'm not happy about the drives having errors, I'm more worried about something else happening on the server that I was hoping would have shown in the logs.
-
The disk above would have been disk 5 in the diagnosis Here is disk 2 with more errors in the log BUT 0 errors showing on the main screen in unraid, and no unraid errors or warnings.
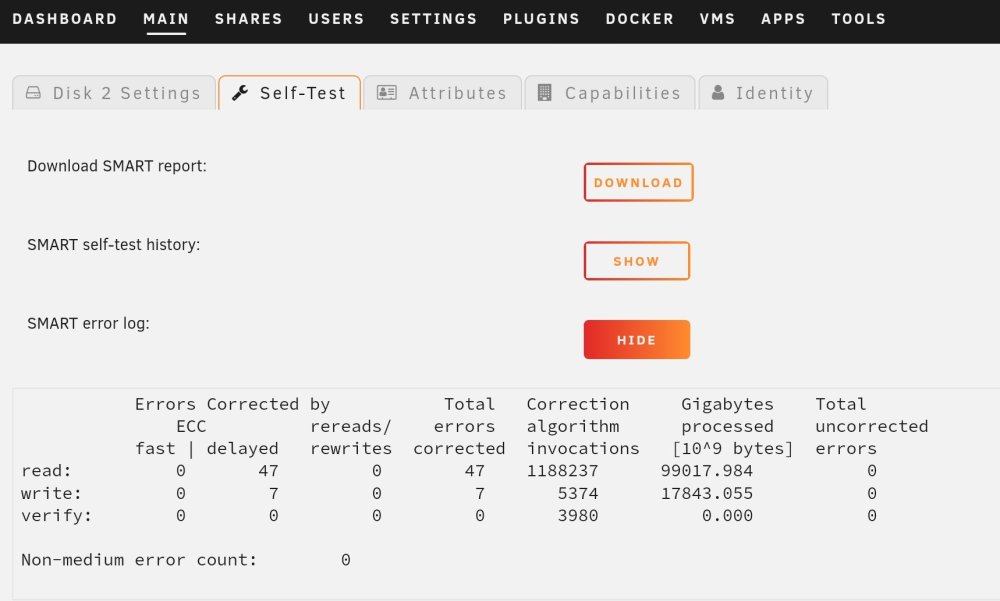
-
In the smart scan logs, they are all corrected I attached a pic of the logs for the drive unraid disabled, it had somewhere in the 1.5 million errors shown on the main screen while rebuilding the drive. Even though smart onlh shows 2 errors. Bill
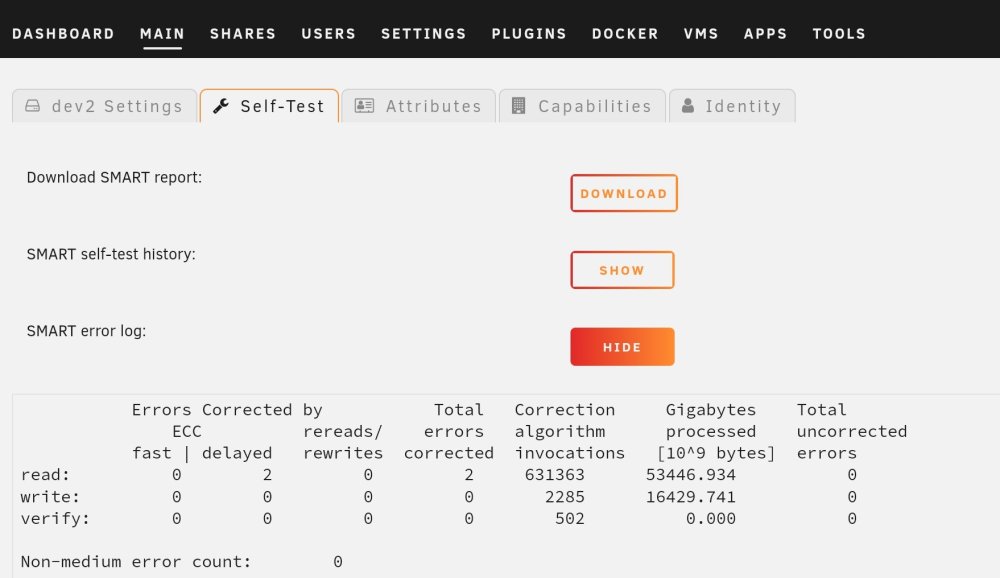
-
Update I have attached an updated diagnostic report I was misreading tge logs and reading correction algorithm invocations as errors, but it seems they are not actually "errors". But I still have 4 drives with delayed read and write smart errors... It still seems kind of unlikely that 5 drives would all start throwing errors (even though unraid is only reporting errors on the main screen for one)... Is it possible the sas card or something else is happening? Or did I just have a run of really bad luck with drives? bob-diagnostics-20230621-2156.zip
-
Hey all I am hoping for smarter people to be able to look at my diags and hopefully help point at the likely culprit of an issue. I built a server a few months ago HPE dl380 lff gen9 (12 3.5 drive slots) 2 @ e5-2690 xeons 128gb ecc ram Matrox on board display 4 port Broadcom nic Emulex 2 port 10g nic LSI SAS2308 sas controller for Jbod enclosure (not currently in use) HPE smart array sas controller and expander to control all 12 drives, sorry forget exact models Nvidia gtx 1650 super (for plex transcoding) 7 @ 8tb hgst H7280A520SUN8.0T drives (data) 2 @ Seagate ST12000NM004G (dual parity) 1 @ samsung 870 4tb ssd (data write cache) 1 @ inland sata ssd 1tb (appdata) 1 @ samsung sata ssd 500gb (vm os disk) 1 @ 8tb hgst H7280A520SUN8.0T Precleared and in static bag as cold spare. All of the spindle drives were purchased used, ex data center drives... So I know there is a good possibility of drive failures with these, the 12tb drives had less than 500 hours on them so they were basicly new. About a week ago I saw errors on one data drive. I looked at the smart logs and saw delayed read errors, I talked to the company I bought the drives from and even though the drive was out of their warranty period they replaced the drive! I put the cold spare in and it started rebuilding. During the rebuild process I went to check if plex and other apps needed updates and received an error saying the server couldn't connect to github and an error message saying it couldn't write to a file in the usr/local share. That had happened a few weeks ago and the "fix" or work around was to reboot the server 🙄 unfortunately due to the error the server sees it as an unclean shutdown and stopped the data restore and kicked off a parity check instead (I hope that didn't delete 5 to 6btb of data 🤬)... During the parity check the "spare" drive listed over 1 million errors (very close in number to the number of writes on the disk). I paused the parity check, stopped the array put the replacement drive in the system (removed an unassigned drive) and restarted the array, at this time unraid disabled the "spare drive", I looked at the logs on the replacement drive and it has a bunch of smart errors as well 🤬 I then looked at all the drives, and out of the 9 spinning drives 6 are showing errors in the smart logs, most are delayed read errors, but there are some delayed write and verification errors as well. NONE of the ssds have any errors and 1 12tb and 2 8tb drives show no errors! I am currently running a full smart scan on all drives. In my mind it doesn't seem likely that so many of the drives would have errors, BUT it doesn't seem likely that there is another hardware issue or I would think All drives would have errors. I have attached diags in hopes some other smart people, who know Linux and unraid much better than me, can look at them and help me figure out if this is a random fluke and most of the drives I bought went bad or if there is something else going on. bob-diagnostics-20230621-1625.zip



