

autumnwalker
-
Posts
246 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by autumnwalker
-
-
On 9/30/2023 at 4:03 AM, Rysz said:
Backend development can never plan for all UPS devices and updating comes with a chance of degraded UPS compatibility.
That means if NUT works well for you and you are happy with everything, updating is not going to bring you much benefit.
Thank you for the heads up!
Is there a way to roll back to a previous version of the plugin if you update and it breaks your UPS? I don't want to get "tech debt" by just letting the updates go.
-
Is it possible to use this to host local files on TFTP? I have a couple of devices (e.g. IP phone) which are updated via tftp hosted files.
I like the iPXE features too ... but wondering if I can also use this to allow a device to grab a local file via tftp without the whole iPXE menu, etc.
-
On 4/1/2023 at 8:13 AM, SimonF said:
I have created a test 2.8 version https://raw.githubusercontent.com/SimonFair/NUT-unRAID/master/plugin/nut-2.8.0.plg
Only tested on a slave node so far not the netserver one. You will need to remove the orignal plugin to install this version.
Error message in logs. Apr 1 12:10:23 GUITest upsmon[11117]: Login on UPS [[email protected]] failed - got [ERR ACCESS-DENIED] but does connect.
Running this version now with SNMP. Appears to be working as designed! Thanks!
-
Ahh - that shows the localhost stuff - the old version I had network as "no".
-
39 minutes ago, SimonF said:
Yes local host still exists.

Weird ... I don't see it here.

-
Appears to have worked. Did the configuration for "enable localhost connection" get removed? I don't see it in settings anymore - but I see sensor values from IMPI so it must be working.
-
15 hours ago, SimonF said:
You may have to uninstall then install config should be retained.
Thanks, I'll give this a shot.
-
1 hour ago, SimonF said:
You should be able to find my vers before 6.12
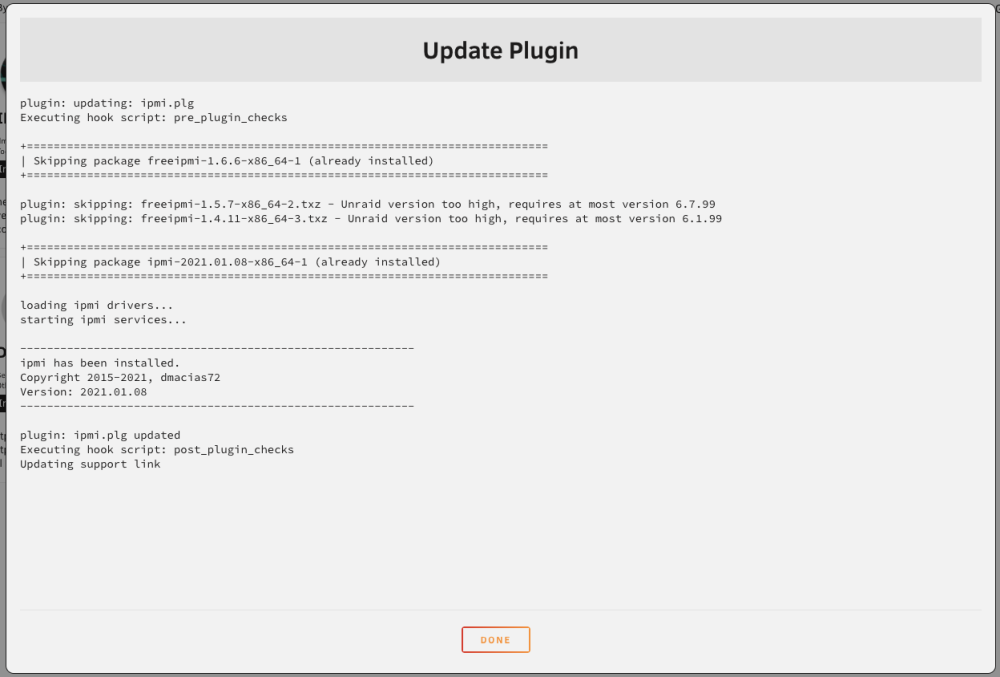
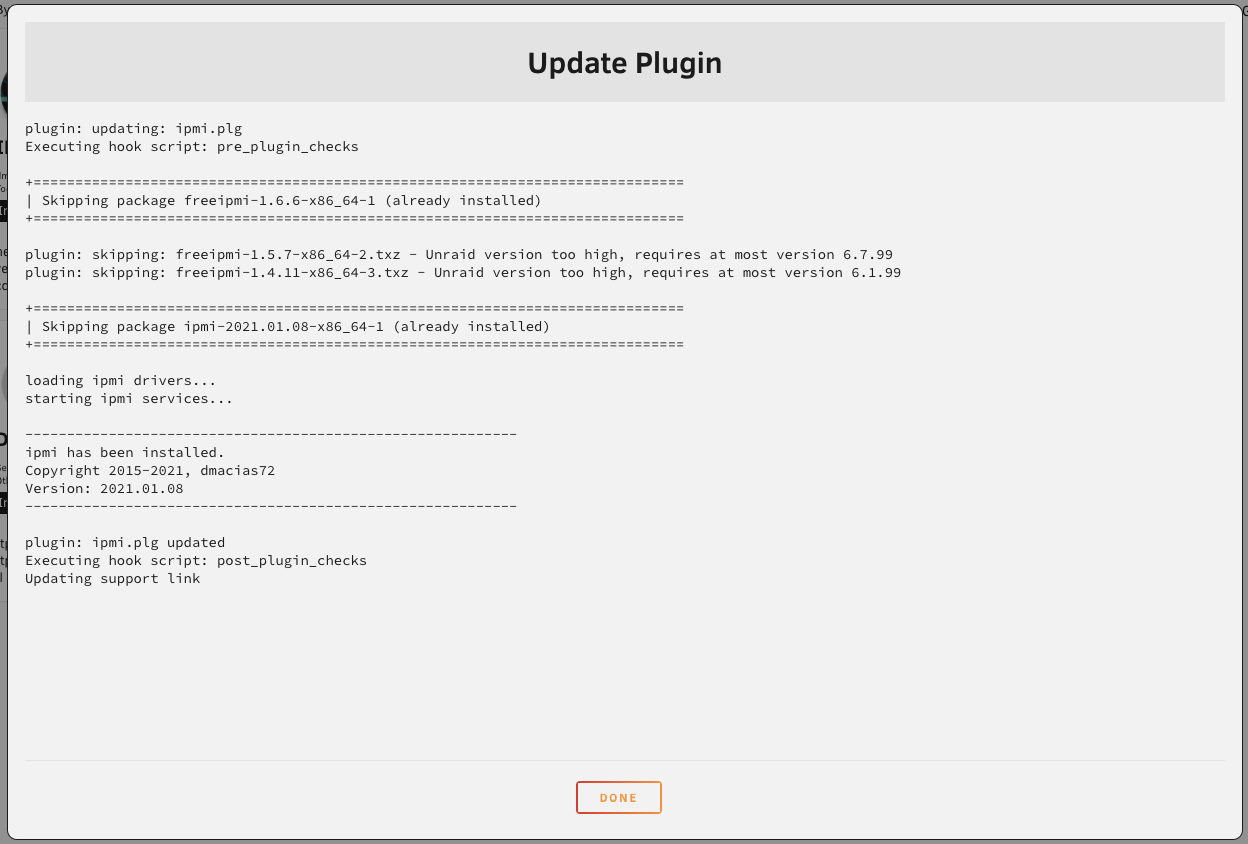
I can find it, but when I hit "update" it installs the dmacias72 version again.
-
hmm - trying to do the "update" method outlined in the early posts, but it just keeps re-installing the old version by dmacias72. Do I have to be on 6.12 first?
-
Anyone using a reverse proxy and experincing this? I just flipped to Nginx Proxy Manager and experienced this again. Toggling "websockets support" immediately solved the problem in the Unraid dashboard for me.
-
took the nuclear option and deleted the /mnt/cache/system/docker and /mnt/user/system/docker folders and I'm starting fresh.
-
Just now, JorgeB said:
Vdisks are thin provisioned initially, copy back with:
cp --sparse=always /source /destis there some way to cleanup what it has already done?
Is the right way to do this with /mnt/user or directly to /mnt/diskX and then to /mnt/cache or to /mnt/user/share?
-
I previously had a 500 GB cache drive (single disk pool) and replaced it with a 1 TB drive.
I shut down docker and virtual machines, set shares to Cache: Yes and invoked mover. After mover finished I took the 500 GB drive out and put the 1 TB drive in. I flipped the shares to Cache: Prefer and invoked mover. Mover has been going for over 24h now and it has somehow managed to move over 500 GB of data back to the 1 TB drive - which makes no sense since the 500 GB drive was only about 45% full to begin with.
Any idea why this is occurring? It appears to be related to btrfs subvolumes - it has been moving them for almost the entire time and somehow growing them to bigger than they were previously.
-
I've been looking at this also - Wazuh doesn't have a Slackware Agent package available.
-
To add to this - I kept "host access to custom networks" on and went back to macvlan and all my problems went away. I do not have crashing issues with macvlan (luckily).
-
Trying to preclear a new drive, seems to be stuck on "Starting ...".
I've noticed a couple others in this thread with the same symptom, but don't see the solution.I don't see anything in the logs at all - just that I started the preclear operation and then I eventually cancel it (I let it run all night - still didn't start).EDIT: I removed the preclear addon and then re-installed it and now it is working again.
-
@Astatine are you using ipvlan + "Host access to custom networks"?
wonder if we're bumping into this?
More info:
-
4 hours ago, MAM59 said:
You should check your firewall rules.
Likely that you have forgot to allow access from the VM Net, so that everybody but the VM Host can use it.
Thanks!
Same network. Also network topology has not changed. This was not an issue until upgrading to 6.11.5.
-
I appear to be having the same symptoms. I'm not getting clock sync errors or anything. I can hit anything on my local LAN using IP or DNS entry (using pfSense DNS resolver), but anything that my local DNS cannot resolve (e.g. google.com) I get "Destination Host Unreachable".
What's odd is I tried the same ping tests from inside a VM running on Unraid while Unraid is having these issues ... and the VM has no network problems at all. The VM is configured to use the same pfSense DNS resolver.
I wasn't having this issue until after I upgraded to 6.11.5. I was previously on 6.10.3.
-
I'm seeing the same thing here now using Edge 111.0.1660.13.
-
I have a MIB (for SNMP purposes) that I want to add to my Unraid box. MIBs are located at /usr/share/snmp/mibs. What's the best way to add a file to that directory so that it survives reboots / upgrades?
-
FYI - just did this conversion myself and Unraid retained my custom networks. I just had to reinstall my containers (which also retained their custom networks / settings). Painless!
-
17 hours ago, VRx said:
@autumnwalker try to set /mnt/user as Host path
That one is there by default in the template.

-
On 1/11/2022 at 6:25 AM, VRx said:
Sorry, I think I missed notification about reply.
On the docker configuration page you have preconfigured /mnt/user and /mnt/cache (as array and cache pool).
You can change it on Your own, for example by disk or maybe add some other pools.
Access Mode can be just Read Only
For example:
/mnt/user on host You can bind to /mnt/array in zabbix agent container/mnt/cache on host You can bind to /mnt/something in zabbix agent container
In Zabbix GUI You must set container paths to monitor, so:
/mnt/array
and/mnt/something
I'm drawing a blank here. I've got the template configured using Linux by Zabbix Agent and it's working great. It has discovered /mnt/cache but it is not discovering /mnt/array.
It has also discovered all sorts of other filesystems (/, /etc/hostname - and some others). I assume those are related to the docker file as they seem to be detecting my docker file size.
Any tips to get /mnt/array detected?



[Plugin] NUT v2 - Network UPS Tools
in Plugin Support
Posted
@Rysz thank you for taking this on and for being so active and helpful here in the community.
I was working with one of the NUT devs to compile support for Liebert GXT UPS with is-webcard and this older network card I had at the time - we got really close and then he / she fell off the face of the earth so we never quite finished. My UPS mostly works with the ietf MIB. I'm hoping that one of the new NUT builds will incoroporate the work that we did for the Liebert GXT line.