.jpg.28290fe604e024851ad06b9cae09c235.jpg)

snuffy47
-
Posts
145 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by snuffy47
-
-
Top Shelf that got her mounted.
Bit unsure how to check recycle bin of drive though... What should the next step be to ensure all is running as it should
-
Do I use -L in the options or the command that was in another post on console
xfs_repair -vL /dev/md1
-
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... Log inconsistent (didn't find previous header) failed to find log head zero_log: cannot find log head/tail (xlog_find_tail=5) ERROR: The log head and/or tail cannot be discovered. Attempt to mount the filesystem to replay the log or use the -L option to destroy the log and attempt a repair.Well it would seem it asked to use -L

-
Hello,
Well it seems I have myself in a pickle. Pretty sure Disk 7 is failing and when I was getting ready to change it out also noticed that Disk 1 is indicating that its unmountable.
Did find a post on running a file check in maintenance mode but does not see to work.
Phase 1 - find and verify superblock... - block cache size set to 1867992 entries Phase 2 - using internal log - zero log... Log inconsistent (didn't find previous header) failed to find log head zero_log: cannot find log head/tail (xlog_find_tail=5) - scan filesystem freespace and inode maps... sb_fdblocks 111061741, counted 113015432 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 0 - agno = 3 - agno = 4 - agno = 5 - agno = 13 - agno = 14 - agno = 10 - agno = 7 - agno = 9 - agno = 8 - agno = 11 - agno = 2 - agno = 6 - agno = 15 - agno = 12 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... Maximum metadata LSN (8:394) is ahead of log (0:0). Would format log to cycle 11. No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Fri Feb 3 13:28:28 2023 Phase Start End Duration Phase 1: 02/03 13:28:23 02/03 13:28:23 Phase 2: 02/03 13:28:23 02/03 13:28:24 1 second Phase 3: 02/03 13:28:24 02/03 13:28:26 2 seconds Phase 4: 02/03 13:28:26 02/03 13:28:26 Phase 5: Skipped Phase 6: 02/03 13:28:26 02/03 13:28:28 2 seconds Phase 7: 02/03 13:28:28 02/03 13:28:28 Total run time: 5 secondsThink I need to cross my fingers and figure out what is going on with Disk 1 before monkeying with Disk 7
-
I plan to do something the 8TB and 2TB wasnt sure what but will preclear and see what happens
Event: Unraid Parity check
Subject: Notice [TOWER] - Parity check finished (0 errors)
Description: Duration: 19 hours, 51 minutes, 6 seconds. Average speed: 112.0 MB/s
Importance: normalThe other 2 with UDMA CRC error count 30 and 21 will monitor
Well it was a mess but with your help trurl and the UNRAID community looks like I am back to a healthy status
-
Well I decided to just replace Disk 2
Everything seems to be good now
-
Event: Unraid Parity sync / Data rebuild
Subject: Notice [TOWER] - Parity sync / Data rebuild finished (0 errors)
Description: Duration: 20 hours, 55 minutes, 4 seconds. Average speed: 106.3 MB/s
Importance: normalWill try what you suggested for Disk 2 now
-
Quote
The pending sector on disk2 I hope doesn't cause problems for disk1 rebuild.
Me too
") 19hrs and we will know
19hrs and we will know
The items like the Pending Sector amount is there a Ok - Not ok but change very soon number that I can use to ensure I donnt get intot this agian
Or I guess I am really asking when there is orange lines - When do I pull the trigger to replace though will likely be a moving target just looking for a best recommendation - lets say not critical data Not saving baby monkeys here - I do have critical data though hahaha
-
Disk 1 is rebuilding fingers crossed
sad to see the 8TB go bye bye
I posted my Disk 2 GUI for thoughts - I have drives now to replace it
")
The other disks in the GUI have no orange lines except 2 with UDMA CRC error count 30 and 21.
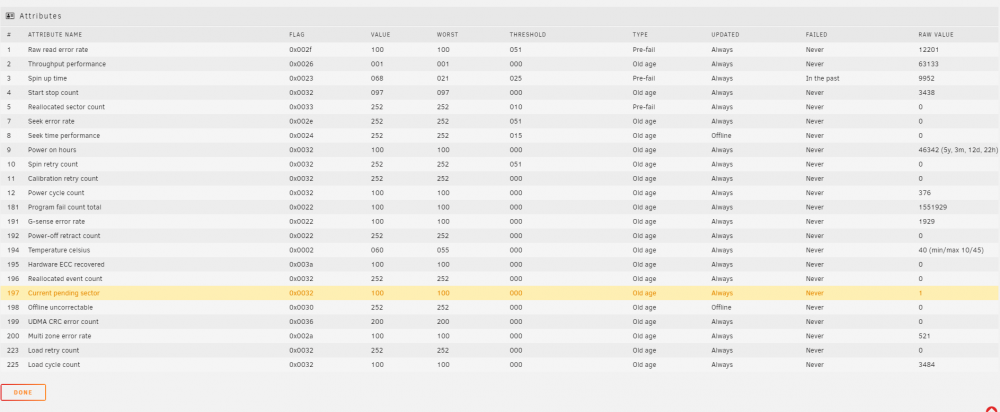
-
Okie Dokie
I still have a thumbs down on Disk 1 and before I had the crazy Disk 3 failure we were targeting Disk 2.
Attached the display of disk 1. If I was ignoring things in the past need to understand better what I can acknowledge and what I should be proactive about. Alot of the 2GB are older for sure
Really appreciate all the help
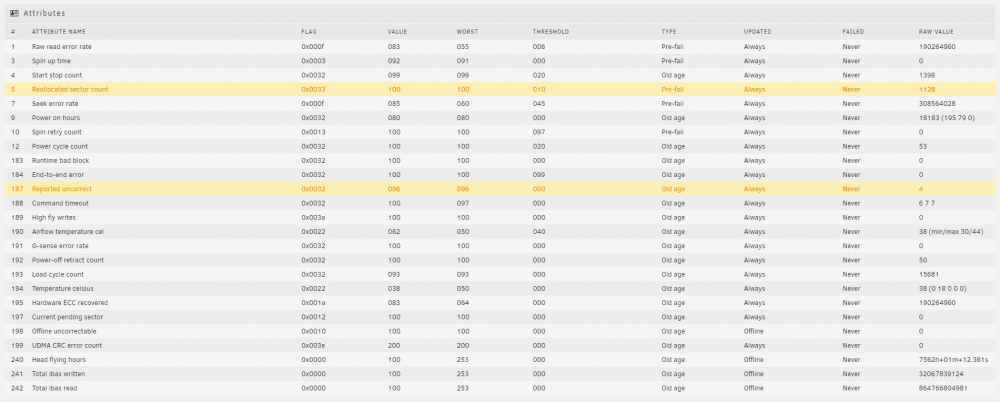
-
-
-
I started that last night but forgot to shut spin down off. Will do an extended test on all remaining drives and post - though it will likely take a day
-
Well first drive replaced
Now I am not sure which one to replace or if I should wait just happy the rebuild went okay
-
Still easily 7 hours to go
Been watching this thing like a hawk as it my first cherry on suspected failure and on top of that possible more at risk HD failures
I need to call it a night
I posted my log just for poops and giggles but will say I miss the ignore and no problems that has been the norm on my end
Really appreciate the help on here. I implement every suggestion from my past problems just not experienced enough to understand the warnings
Also want to add I have a replacement for disk 1 but I am struggling with replacing it as it is one of the newest drives in my array and damn its 8TB - will say less then 1 year old - that might be putting the cart before the mule but damn it hurts
-
Appreciate it
ST2000DMZ08 Segate 2TB
Sorry missed the rerquest for log
-
Well things are rebuilding.....
Watching the drive I am very unsure why this is so high - its what the old drive indicated as a failure mode but the new drive is not flagging anything
# ATTRIBUTE NAME FLAG VALUE WORST THRESHOLD TYPE UPDATED FAILED RAW VALUE 1 Raw read error rate 0x000f 079 076 006 Pre-fail Always Never 74902826
-
Well your suggestion worked
My drives are in hand I am going to exchange 3 now
One thing that popped up that I have never seen before is this which guess it means things are really messed up
QuoteEvent: unRAID file corruption
Subject: Notice [TOWER] - bunker verify command
Description: Found 7 files with BLAKE2 hash key corruption
Importance: alertBLAKE2 hash key mismatch, /mnt/disk3/movies/A-X-L (2018)/A-X-L (2018).mkv is corrupted
BLAKE2 hash key mismatch, /mnt/disk3/movies/50 50 (2011)/50 50 (2011).mkv is corrupted
BLAKE2 hash key mismatch, /mnt/disk3/movies/Aquaman (2018)/Aquaman (2018).mkv is corrupted
BLAKE2 hash key mismatch, /mnt/disk3/movies/Postcards from the Edge (1990)/Postcards from the Edge (1990).mkv is corrupted
BLAKE2 hash key mismatch, /mnt/disk3/movies/Legend of Tarzan, The (2016)/The Legend of Tarzan2016.ISO is corrupted
BLAKE2 hash key mismatch, /mnt/disk3/movies/Mandy (2018)/Mandy (2018).avi is corrupted
BLAKE2 hash key mismatch, /mnt/disk3/movies/The Chronicles of Narnia Prince Caspian (2008)/The Chronicles of Narnia Prince Caspian (2008).mkv is corrupted -
Well I can not win for losing on this one....
Just had another crazy storm roll through and I am having problems Mounting my external drive I was using to back up some of my data
the messages I get are
QuoteSep 7 18:56:19 Tower unassigned.devices: Adding disk '/dev/sdn1'...
Sep 7 18:56:19 Tower unassigned.devices: Mount drive command: /sbin/mount -t 'ntfs' -o rw,auto,async,noatime,nodiratime,nodev,nosuid,nls=utf8,umask=000 '/dev/sdn1' '/mnt/disks/ST4000DM004-2CV104_ZFN3XMJZ'
Sep 7 18:56:19 Tower unassigned.devices: Mount of '/dev/sdn1' failed: '$MFTMirr does not match $MFT (record 0). Failed to mount '/dev/sdn1': Input/output error NTFS is either inconsistent, or there is a hardware fault, or it's a SoftRAID/FakeRAID hardware. In the first case run chkdsk /f on Windows then reboot into Windows twice. The usage of the /f parameter is very important! If the device is a SoftRAID/FakeRAID then first activate it and mount a different device under the /dev/mapper/ directory, (e.g. /dev/mapper/nvidia_eahaabcc1). Please see the 'dmraid' documentation for more details. '
Any help is appreciated
-
Well arent I in a mess
I wasnt having any problems up to the power outage knocking my MOBO out but guess need to learn how to read the HD counts better. You get use to no problems and then you ignore things
The data back up will take another day
Do I toss a dart at the wall and try replacing Disk 3 first.. The 2 TB drives and 8TB I ordered wonnt be here till mid week
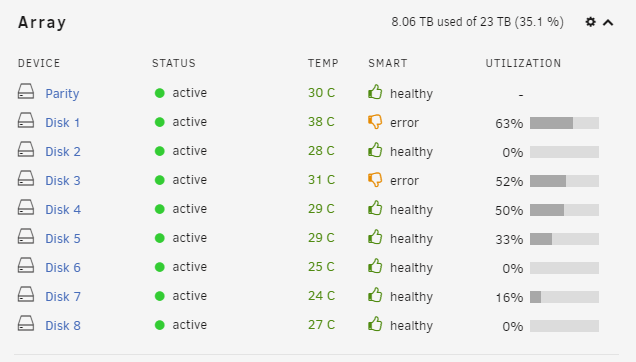
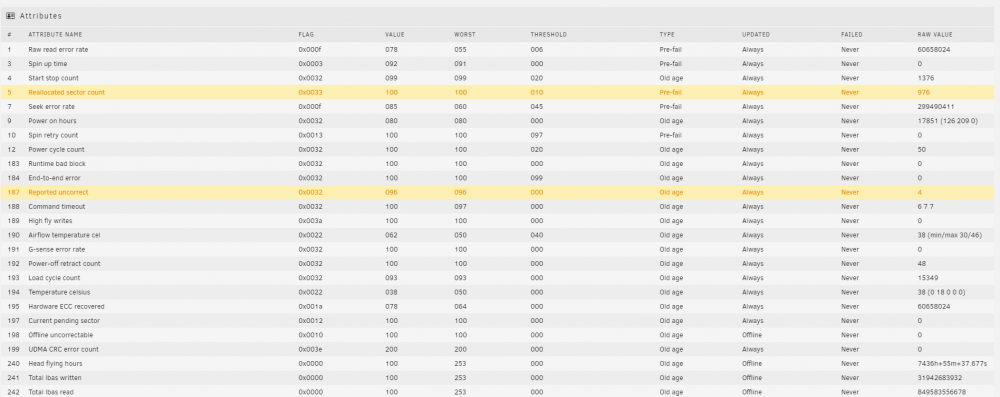
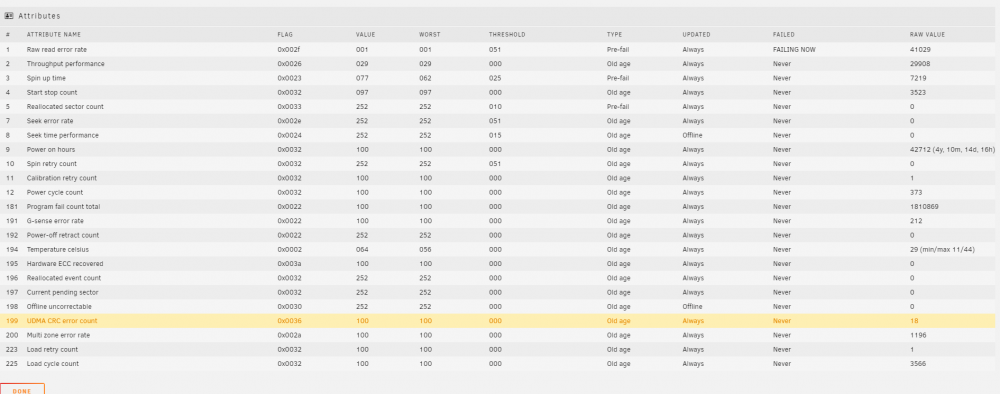
-
Update
Not sure if it was the correct approach but I had 2 disks that would allow me to back up lets say would rather not lose files but would rather not... Crazy part is 3/4 of my data is media that falls under that category. My do not want to ever lose I keep a external back up already
Order some new drives if replacement is required also as backing up files used my spares. Like I said maybe not the best idea but still not sure what is causing all the problems
The RAW error reads have seemed to stop now that I canceled the parity check
General Plan at this point and hoping if I am off track that the more experienced may correct
1. Back up Data
2. Check Connections on every thing and run a few days. Struggling with this as I feel there is failing hardware but maybe not
3. If problem continues change drive 3 - Hope it rebuilds - run for a few days
4. Have not went past that
-
-
In Painic mode.....
Have not opened up box or changed anything yet
What I started was to SMART Test disc 1 and disk 3 with the intentions of testing all my drives and posting. These are attached though my server started a schedule parity check that I forgot to turn off
Disk 3 is spitting out a ton of Raw Read Errors
I am wondering if there is something lose ;( The 1 item I should note I do have a 5 disk 5.25" insert. I was thinking I should emliminate this out of the system as it is old but I am 1 slot shy in my server to do that
Going to back things up now guess go from there
RAID Forums.zip tower-smart-20210902-1327 (1).zip tower-smart-20210902-1327.zip
-
I get email notifications just not sure how well I monitor that though
Do you have a recommendation as I am sure it will run over the evening when I change it.
-
Turl
Well I have a disk I can replace it with so will go that route
. Before I do is there anything else I should complete prior to this?





Disk 1 Unmountable file corruption
in General Support
Posted
Thanks for all the help much appreciated