



.jpg.28290fe604e024851ad06b9cae09c235.jpg)

snuffy47
Members
-
Joined
-
Last visited
Everything posted by snuffy47
-
Well I need to change the power cable still will order a new one. I have a spare 8T in the machine if needed. It doesnt need to be connected to the same SATA port to swap does it?
-
Poopy it came back :( tower-diagnostics-20260103-1415.zip
-
Ok will do. Back to parity drive watching Last check completed on Wed 17 Dec 2025 01:42:46 AM EST (today) Duration: 1 day, 3 hours, 52 minutes, 37 seconds. Average speed: 79.7 MB/s Finding 0 errors
-
Will let the parity sync finish. Think the Smart Error was there prior for Disk 3 Once things are back running will see what is up.
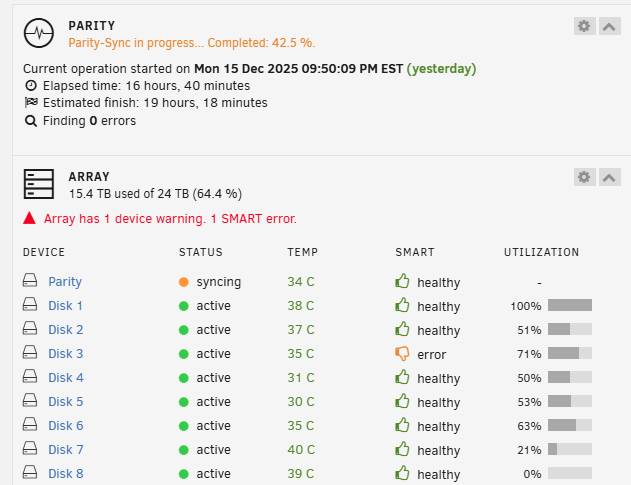
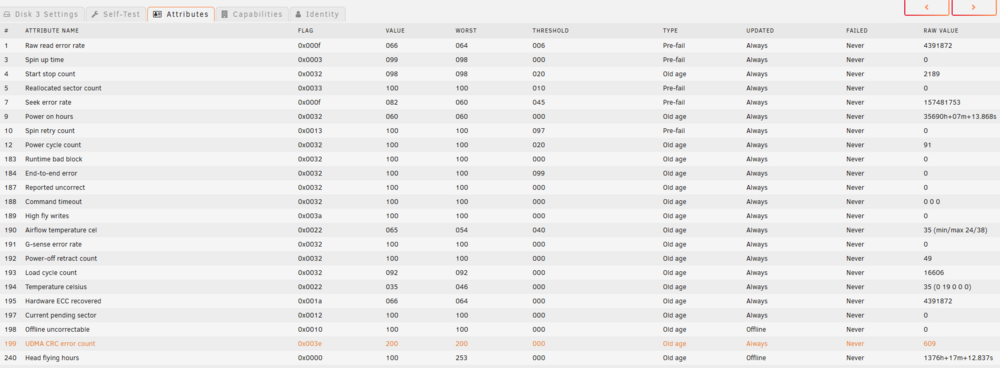
-
Hello, Well working through some parity drive problems but since I have been opening the box up in the last few weeks more then I have since I build this thing wondering if its time to upgrade..... And if so what should I upgrade too - $$ isnt something that is free to spend here . This thing primary runs Plex, sonar, radarr, nzbget and backups my local network file systems. Supermicro X8DT6 , Version 2.02 American Megatrends Inc., Version 2.2 BIOS dated: Mon 9 Jul 2018 12:00:00 AM EDT Intel® Xeon® CPU L5640 @ 2.27GHz x 2 Memory: 40 GiB DDR3 Multi-bit ECC CORSAIR OBSIDIAN 750D case 24T drive space
-
Okay took it apart damn been a long time moving stuff around in this thing. Replaced the sata cable with another one. Did find the power cable had a splitter. Do not have a new one but took it all apart cleaned and reconnected Does look like I have a data disk on its way out too Disk 3?
-
Will take it apart again not sure I can replace power cable but will check
-
Well it happened again Did not restart and uploaded file tower-diagnostics-20251213-1824.zip
-
Took a bit to enable but been running green for about 5 days. Guess I just need to keep an eye on it.
-
Ok have some cables showing up tomorrow. What do I do after I change the cable? Should the x go away
-
Hello Attached. tower-diagnostics-20251106-0657.zip
-
Hello Well its been sometime running my server but it seems my parity has a red x. Wondering what my next steps are. I do have a replacement drive
-
Thanks for all the help much appreciated
-
Top Shelf that got her mounted. Bit unsure how to check recycle bin of drive though... What should the next step be to ensure all is running as it should
-
Do I use -L in the options or the command that was in another post on console xfs_repair -vL /dev/md1
-
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... Log inconsistent (didn't find previous header) failed to find log head zero_log: cannot find log head/tail (xlog_find_tail=5) ERROR: The log head and/or tail cannot be discovered. Attempt to mount the filesystem to replay the log or use the -L option to destroy the log and attempt a repair. Well it would seem it asked to use -L tower-diagnostics-20230203-1348.zip
-
Hello, Well it seems I have myself in a pickle. Pretty sure Disk 7 is failing and when I was getting ready to change it out also noticed that Disk 1 is indicating that its unmountable. Did find a post on running a file check in maintenance mode but does not see to work. Phase 1 - find and verify superblock... - block cache size set to 1867992 entries Phase 2 - using internal log - zero log... Log inconsistent (didn't find previous header) failed to find log head zero_log: cannot find log head/tail (xlog_find_tail=5) - scan filesystem freespace and inode maps... sb_fdblocks 111061741, counted 113015432 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 0 - agno = 3 - agno = 4 - agno = 5 - agno = 13 - agno = 14 - agno = 10 - agno = 7 - agno = 9 - agno = 8 - agno = 11 - agno = 2 - agno = 6 - agno = 15 - agno = 12 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... Maximum metadata LSN (8:394) is ahead of log (0:0). Would format log to cycle 11. No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Fri Feb 3 13:28:28 2023 Phase Start End Duration Phase 1: 02/03 13:28:23 02/03 13:28:23 Phase 2: 02/03 13:28:23 02/03 13:28:24 1 second Phase 3: 02/03 13:28:24 02/03 13:28:26 2 seconds Phase 4: 02/03 13:28:26 02/03 13:28:26 Phase 5: Skipped Phase 6: 02/03 13:28:26 02/03 13:28:28 2 seconds Phase 7: 02/03 13:28:28 02/03 13:28:28 Total run time: 5 seconds Think I need to cross my fingers and figure out what is going on with Disk 1 before monkeying with Disk 7 tower-diagnostics-20230203-1328.zip
-
I plan to do something the 8TB and 2TB wasnt sure what but will preclear and see what happens Event: Unraid Parity check Subject: Notice [TOWER] - Parity check finished (0 errors) Description: Duration: 19 hours, 51 minutes, 6 seconds. Average speed: 112.0 MB/s Importance: normal The other 2 with UDMA CRC error count 30 and 21 will monitor Well it was a mess but with your help trurl and the UNRAID community looks like I am back to a healthy status
-
Well I decided to just replace Disk 2 Everything seems to be good now
-
Event: Unraid Parity sync / Data rebuild Subject: Notice [TOWER] - Parity sync / Data rebuild finished (0 errors) Description: Duration: 20 hours, 55 minutes, 4 seconds. Average speed: 106.3 MB/s Importance: normal Will try what you suggested for Disk 2 now
-
Me too 19hrs and we will know The items like the Pending Sector amount is there a Ok - Not ok but change very soon number that I can use to ensure I donnt get intot this agian Or I guess I am really asking when there is orange lines - When do I pull the trigger to replace though will likely be a moving target just looking for a best recommendation - lets say not critical data Not saving baby monkeys here - I do have critical data though hahaha
-
Disk 1 is rebuilding fingers crossed sad to see the 8TB go bye bye I posted my Disk 2 GUI for thoughts - I have drives now to replace it The other disks in the GUI have no orange lines except 2 with UDMA CRC error count 30 and 21.
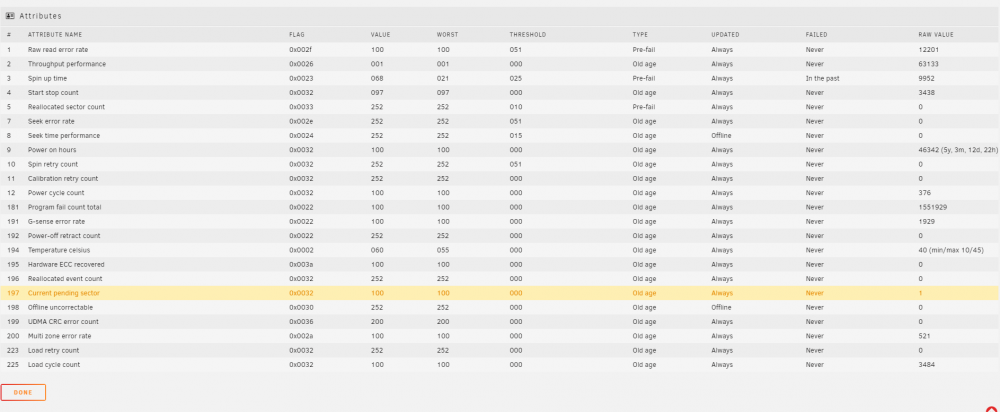
-
Okie Dokie I still have a thumbs down on Disk 1 and before I had the crazy Disk 3 failure we were targeting Disk 2. Attached the display of disk 1. If I was ignoring things in the past need to understand better what I can acknowledge and what I should be proactive about. Alot of the 2GB are older for sure Really appreciate all the help
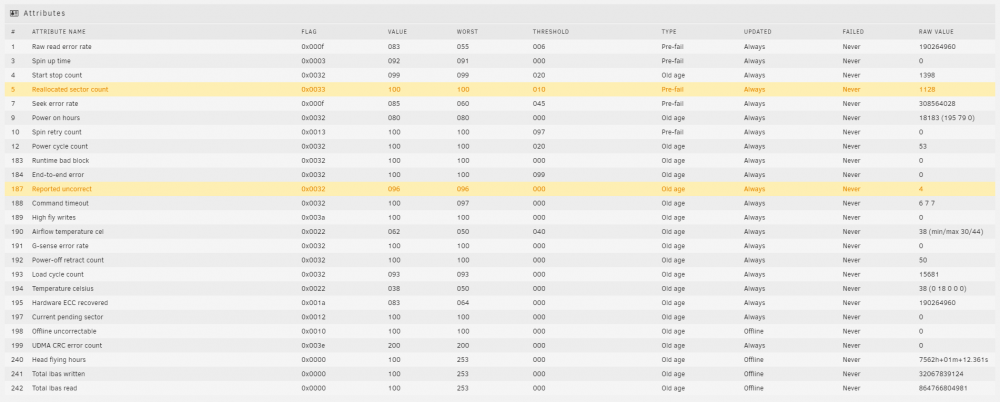
-
My bad tower-diagnostics-20210914-2209.zip
-
Extended test on remaining drives attached D1 tower-smart-20210913-0759.zip D2 tower-smart-20210913-0758.zip D4 tower-smart-20210913-0758.zip D5 tower-smart-20210913-0758.zip D6 tower-smart-20210913-0758.zip D7 tower-smart-20210913-0758.zip D8 tower-smart-20210913-0757.zip





