




Sniper00X
Members
-
Joined
-
Last visited
Everything posted by Sniper00X
-
@JorgeB no, with versions > than 6.9.2 when it crash, if's inaccessible even on the local terminal (frozen).
-
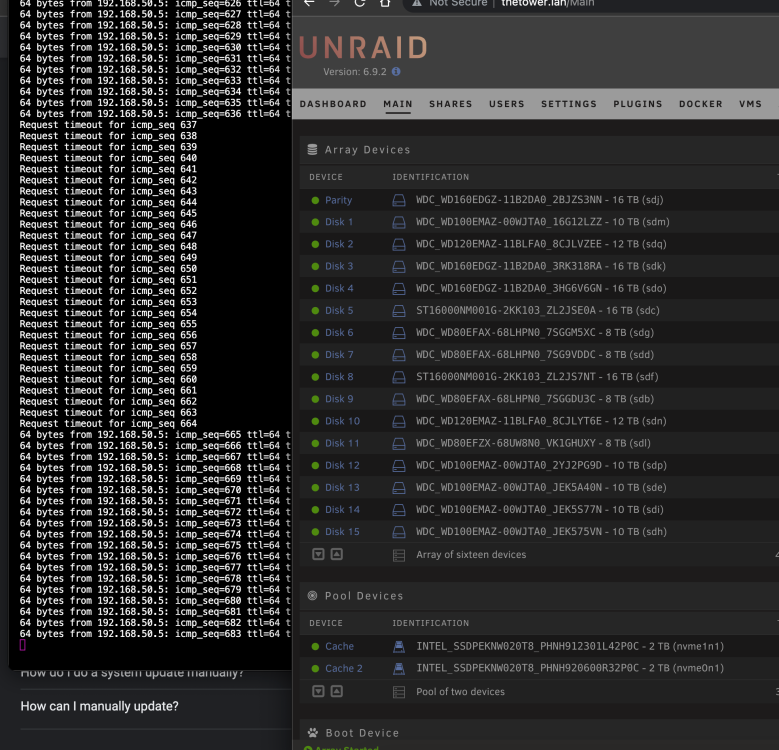
So I've downgraded back to 6.9.2 for now Array did start, however interestingly, I've been doing a ping test to the server every time i start the array to see if it goes down. It seems even with 6.9.2 the interface goes offline for a moment but comes back up. I don't know if it's related, but is it possible that my network cards or net config is what's causing the crashes --- and i didn't notice because it recovers with 6.9.2 but not the later versions? Here's a screenshot of the ping test as the array was starting --- and i've included the latest syslog as well (weird) syslog
-
Here's the latest syslog after most recent reboot and crash syslog
-
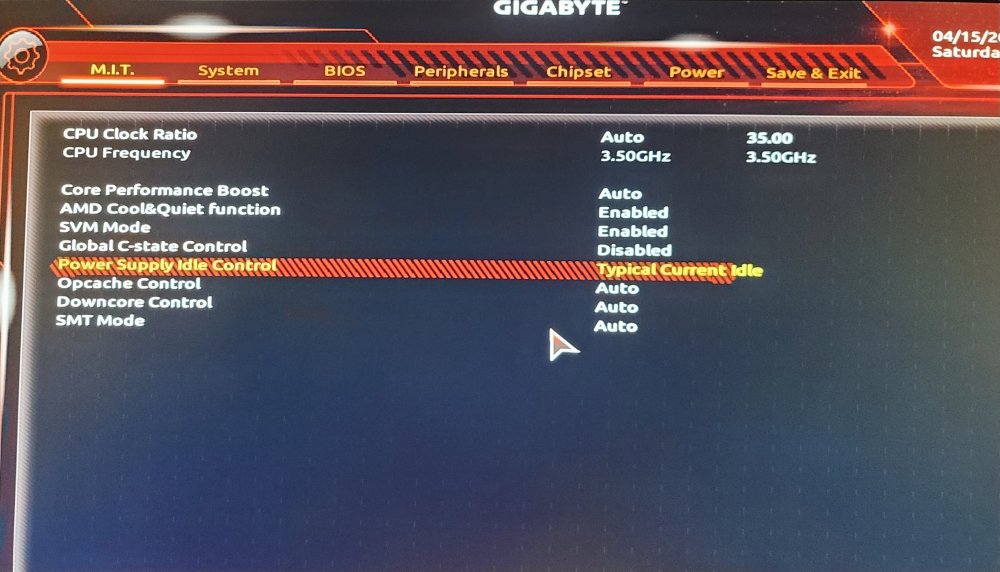
Thanks for the reply @Squid yes I've double checked those settings. I've even toggled C-State to see if it would make a difference, no luck.
-
Hey @JorgeB I've captured and attached the latest syslog It's still crashing upon array startup syslog
-
I recently upgraded from version 6.9.2 But all versions I've tried has been crashing after array startup Some versions (like 6.11.5) the array was able to start (sporadically) but then would crash during Parity Checks I've had to downgrade to 6.9.2 to get back to an operational state. Here's what i've tried so far: - Booted into Safe Mode (no plugins), made no difference - Fixed all Common Issues reported - Removed old plugins - Upgraded all plugins to latest version - Looked at logs to see if anything stood out that might be causing a kernal panic (couldn't find anything meaningful - Messed around with c-state and acpi settings in bios (no difference) What might I be missing in order to figure out what's causing the issue? Thanks S
-
Hello, This weekend went into the BIOs and disabled Global C-States However, this morning the server crashed again. This time though, I had a monitor hooked up to the server and was able to take a image of the screen <code> a(PO) drm backlight agpgart w83795 i5500_temp ip6table_filter ip6_tables iptable _filter ip_tables x_tables be2net igb i2c_algo_bit atlantic edac_mce_amd kvm_ama kvm btusb btrt1 crct10dif_pclmul crc32_pclmul btbcm crc32c_intel btintel ghash_ clmulni_intel aesni_intel crypto_simd bluetooth mxm_wmi cryptd wmi_bmof glue_he I per mpt3sas izc_piix4 raid_class ecdh_generic input_leds ecc nume rapl scsi_tran sport_sas ahci i2c_core led_class nume_core k10temp wmi ccp libahci button acpi-_ cpufreq [last unloaded : be2net] --- end trace 306897cb8606c0c5 ]--- RIP: 0010:nf_nat_setup_info+0x129/0x6aa [nf_nat] Code: ff 48 8b 15 ef 6a 00 00 89 c0 48 8d 04 c2 48 8b 10 48 85 d2 74 80 48 81 ea 98 00 00 00 48 85 d2 of 84 70 ff ff ff 8a 44 24 46 <38> 42 46 74 09 48 8b 92 98 00 00 00 eb d9 48 8b 4a 20 48 8b 42 28 RSP: 0018:ffffc9000075c700 EFLAGS: 00010202 RAX: ffff8881bf5e5d11 RBX: ffff8884cb2d6940 RCX: 0000000000000000 RDX: 41a68045a11c4623 RSI: 0000000017213a45 RDI: ffffc9000075c720 RBP: ffffc9000075c7c8 R08: 00000000251a42d2 R09: ffff8881bec61680 R10: ffff8881432ec388 R11: ffffffff815cbe4b R12: 0000000000000000 R13: ffffc9000075c720 R14: ffffc9000075c7dc R15: ffffffff8210b440 FS: 0000150126d5b640(0000) GS:ffff889ffd340000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CRO: 0000000080050033 CR2: 0000148053281800 CR3: 000000013e810000 CR4: 00000000003506e0 Kernel panic not syncing: Fatal exception in interrupt Kernel Offset: disabled --- [ end Kernel panic not syncing: Fatal exception in interrupt ]--- </code> Any clue what this is referring to?
-
@ChatNoir no I wasn't aware of that. But I'll certainly check and try that. I do have a Gen 1 Threadripper processor so it's quite possible that some bios update / tuning is required. I'll take a look at that as a start and report back. Question, is there anyway to get syslogs to be persistent? That way if i experience another crash we could have access to the log information and not lose it to reboot?
-
Hello, I've been experiencing some random server crashes. Not exactly sure what could be causing it as it happens at different intervals. Sometimes I can go days without any issues. When it happens, I lose network access, access to the web interface, and access to SSH or local terminal (at the machine). Can someone help take a look at my logs to see if I'm missing something obvious? Thanks thetower-diagnostics-20220328-1953.zip
-
Yes that's the only controller. Onboard SATA are unused. Ok i think it's time i unrack the server, crack it open and do some troubleshooting Will report back steps.
-
Ok it says the test completed without error Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 1962 - # 2 Extended offline Interrupted (host reset) 00% 1929 - # 3 Short offline Completed without error 00% 1900 - # 4 Extended offline Completed without error 00% 332 - I've attached the new diag file. Drive is still spun down and in disabled state, I haven't changed anything. Awaiting advice. thetower-diagnostics-20211210-1625.zip
-
ok did that and re-kicked off the test about 2 hours ago. It's still saying it's running and at 10% Will let it run it's course and report back.
-
Woke up this morning to the following error: Last SMART test result: Interrupted (host reset) I've attached the new diag files thetower-diagnostics-20211209-0815.zip
-
Should I run the Extended Smart test again? This time while mounted in Unraid?
-
it took about 22 hours
-
The only other thing i can think of is, do you think my SAS controller may need a firmware update to effectively run a 16TB drive? This is the first 16TB drive that I've put into the system probably a couple months ago and been having issues on/off Controller version: 04:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03)
-
I literally did it yesterday, not on the Unraid Server In a another computer that I was testing the drive Does the smart runs not get updated on the drive itself?
-
My new 16TB Exos Party Drive keeps going into disabled state and I'm not sure why Here's what i've done to try to troubleshoot: 1. Switched SATA cables 2. Moved drive to different slots 3. Pulled drive and update Firmware 4. Did Extended Self-test (Passed successful) 5. Did offline (outside of Unraid) surface scan test (no bad blocks reported) I'm stumped, any ideas? Here are my log files thetower-diagnostics-20211208-1715.zip
-
@JorgeB I pulled all of the drives from the server and rearranged to different slots. I paired the 16tb drives to consecutive slots (they we not before). I fired the server back up and started rebuild which seems to have completed successfully in little over 2 days without any noticeable errors. Have parity check set to monthly, so will monitor next month when it runs again Thanks for the help.
-
Hmm odd as there were drives in there before and it's a hotswappable 24 bay Norco. But I'll try what you have suggested this weekend and report back
-
Thanks for taking a look. Here is the diagnostics requestedthetower-diagnostics-20211029-0638.zip
-
Hello I recently purchased (about 1 month now) 2 Seagate Exos x16 16TB drives I replaced parity with 1 and another array disk with the other Unraid was able to replace parity, upgrade the new disk, and rebuild parity successfully. My first Parity Check (scheduled) launched this weekend and I started getting a bunch of read errors on both 16TB drives Here's what I did so far: - I was forced to stop parity check - I ran smart extended checks on both drives -- they both passed - I did xfs_repair on the array drive -- because it was reading as unmountable - Parity drive was reporting as disabled -- I removed and reassigned Parity drive - Started Parity Re-build 30 mins into rebuild i'm getting disk read errors on the array drive (Exos 16TB): [77822.306452] md: disk8 read error, sector=248659112 [77822.306456] md: disk8 read error, sector=248659120 [77822.306459] md: disk8 read error, sector=248659128 [77822.306462] md: disk8 read error, sector=248659136 [77822.306466] md: disk8 read error, sector=248659144 [77822.306469] md: disk8 read error, sector=248659152 [77822.306473] md: disk8 read error, sector=248659160 [77822.306477] md: disk8 read error, sector=248659168 [77822.306481] md: disk8 read error, sector=248659176 [77822.306484] md: disk8 read error, sector=248659184 [77822.306487] md: disk8 read error, sector=248659192 [77822.306491] md: disk8 read error, sector=248659200 [77822.306496] md: disk8 read error, sector=248659208 [77822.306499] md: disk8 read error, sector=248659216 [77822.306503] md: disk8 read error, sector=248659224 [77822.306507] md: disk8 read error, sector=248659232 [77822.306511] md: disk8 read error, sector=248659240 [77822.306514] md: disk8 read error, sector=248659248 [77822.306517] md: disk8 read error, sector=248659256 [77822.306519] md: disk8 read error, sector=248659264 [77822.306521] md: disk8 read error, sector=248659272 [77822.306523] md: disk8 read error, sector=248659280 [77822.306524] md: disk8 read error, sector=248659288 [77822.306525] md: disk8 read error, sector=248659296 [77822.306526] md: disk8 read error, sector=248659304 [77822.306530] md: disk8 read error, sector=248659312 [77822.306532] md: disk8 read error, sector=248659320 [77822.306535] md: disk8 read error, sector=248659328 [77822.306536] md: disk8 read error, sector=248659336 [77822.306537] md: disk8 read error, sector=248659344 [77822.306541] md: disk8 read error, sector=248659352 [77822.306543] md: disk8 read error, sector=248659360 [77822.306545] md: disk8 read error, sector=248659368 [77822.306546] md: disk8 read error, sector=248659376 [77822.306548] md: disk8 read error, sector=248659384 [77822.306549] md: disk8 read error, sector=248659392 [77822.306550] md: disk8 read error, sector=248659400 [77822.306551] md: disk8 read error, sector=248659408 [77822.306555] md: disk8 read error, sector=248659416 [77822.306557] md: disk8 read error, sector=248659424 [77822.306560] md: disk8 read error, sector=248659432 [77822.306561] md: disk8 read error, sector=248659440 [77822.306562] md: disk8 read error, sector=248659448 [77822.306565] md: disk8 read error, sector=248659456 [77822.306567] md: disk8 read error, sector=248659464 [77822.306570] md: disk8 read error, sector=248659472 [77822.306571] md: disk8 read error, sector=248659480 [77822.306572] md: disk8 read error, sector=248659488 [77822.306573] md: disk8 read error, sector=248659496 [77822.306575] md: disk8 read error, sector=248659504 [77822.306579] md: disk8 read error, sector=248659512 [77822.306581] md: disk8 read error, sector=248659520 [77822.306583] md: disk8 read error, sector=248659528 [77822.306585] md: disk8 read error, sector=248659536 [77822.306586] md: disk8 read error, sector=248659544 [77822.306589] md: disk8 read error, sector=248659552 [77822.306591] md: disk8 read error, sector=248659560 [77822.306594] md: disk8 read error, sector=248659568 [77822.306595] md: disk8 read error, sector=248659576 [77822.306596] md: disk8 read error, sector=248659584 [77822.306598] md: disk8 read error, sector=248659592 [77822.306601] md: disk8 read error, sector=248659600 [77822.306604] md: disk8 read error, sector=248659608 [77838.048467] sd 1:0:4:0: Power-on or device reset occurred What else can i check to validate whether they are BAD drives versus a config issue with my Unraid?


