




shutterbug
Members
-
Joined
-
Last visited
Everything posted by shutterbug
-
sure enough, 5 total clicks on macOS installer after a reboot each time got me into the OS. Thank you! (and SpaceInvader One does indeed note this in the video, now that I've gone back and reviewed, doh!)
-
yes, that's exactly what I see. I'm running around an 8th gen corei7, and 6.9 rc1.
-
Well I finally got the macinbox vm working, I formatted my 107gig disk, started the OS reinstall of bigsur, it ran for about 1/2hr, appeared to complete without errors, then when it rebooted and I'm back to the screen that has macos base system, macos installer, recovery, uefi shell, shutdown and reset nvram. If I reinstall again, same things happens. I seem to be stuck in a loop and never get an option to boot into the OS.
-
Deleting the custom_ovmf folder was what I needed, thanks so much!
-
So I had macinabox working previously (the version before bigsur was supported), worked great. I followed space invader ones steps in the video, precisely, to remove my old VM, docker, template, etc... I've gone through the video several times to make sure I'm not missing a step. My docker is configured precisely as noted in the video (same paths/etc..) but I'm getting this error when I try to fire up the VM with bigsur for the first time: "operation failed: unable to find any master var store for loader: /mnt/user/system/custom_ovmf/Macinabox_CODE-pure-efi.fd" I've removed everything and have gone through the video several times, all with the same result. The only thing that's not 'stock' on my unraid would be that I have a pool of nvme SSDs in addition to my cache (running 6.9 rc1) and I have moved my 'domains' directory for VMs to that pool.
-
Thank you! Is there any reason I wouldn't want to run privoxy? I never had it on before, but after enabling it and reading up on it, I reconfigured sonarr and radarr to pull from the privoxy port and this seems like an ideal solution. Just wondering if there are any cons to running it? (I don't use SABnzbd outside of my LAN)
-
Sure enough, enabling privoxy solved it for me as well. I've never had this enabled previously, as you noted, worked fine before. Thanks!
-
both sonarr and radarr show that it is running, the checks from those tools pass. I've tried to hit the web interface from multiple browsers and incognito mode, all time out. Unraid has been rebooted, problem remains.
-
No auth errors, the wireguard interface appears to come up and I receive an IP: 2020-12-02 18:12:57,180 DEBG 'start-script' stdout output: [info] Attempting to bring WireGuard interface 'up'... 2020-12-02 18:12:57,189 DEBG 'start-script' stderr output: Warning: `/config/wireguard/wg0.conf' is world accessible 2020-12-02 18:12:57,194 DEBG 'start-script' stderr output: [#] ip link add wg0 type wireguard 2020-12-02 18:12:57,195 DEBG 'start-script' stderr output: [#] wg setconf wg0 /dev/fd/63 2020-12-02 18:12:57,206 DEBG 'start-script' stderr output: [#] ip -4 address add 10.x.x.x dev wg0 2020-12-02 18:12:57,210 DEBG 'start-script' stderr output: [#] ip link set mtu 1420 up dev wg0 2020-12-02 18:12:57,227 DEBG 'start-script' stderr output: [#] wg set wg0 fwmark 51820 2020-12-02 18:12:57,228 DEBG 'start-script' stderr output: [#] ip -4 route add 0.0.0.0/0 dev wg0 table 51820 2020-12-02 18:12:57,229 DEBG 'start-script' stderr output: [#] ip -4 rule add not fwmark 51820 table 51820 2020-12-02 18:12:57,230 DEBG 'start-script' stderr output: [#] ip -4 rule add table main suppress_prefixlength 0 2020-12-02 18:12:57,233 DEBG 'start-script' stderr output: [#] sysctl -q net.ipv4.conf.all.src_valid_mark=1 2020-12-02 18:12:57,234 DEBG 'start-script' stderr output: [#] iptables-restore -n 2020-12-02 18:12:57,236 DEBG 'start-script' stderr output: [#] '/root/wireguardup.sh' 2020-12-02 18:12:58,327 DEBG 'start-script' stdout output: [info] Application does not require external IP address, skipping external IP address detection 2020-12-02 18:12:58,328 DEBG 'start-script' stdout output: [info] WireGuard interface 'up' 2020-12-02 18:12:58,329 DEBG 'start-script' stdout output: [info] Application does not require port forwarding or VPN provider is != pia, skipping incoming port assignment 2020-12-02 18:12:58,382 DEBG 'watchdog-script' stdout output: [info] SABnzbd not running 2020-12-02 18:12:58,382 DEBG 'watchdog-script' stdout output: [info] Attempting to start SABnzbd... 2020-12-02 18:12:59,192 DEBG 'watchdog-script' stdout output: [info] SABnzbd process started [info] Waiting for SABnzbd process to start listening on port 8080... 2020-12-02 18:12:59,403 DEBG 'watchdog-script' stdout output: [info] SABnzbd process is listening on port 8080
-
Thanks for this. So I went through your steps and it got rid of the warning in the logs, but now I have an error and still can't access the web interface. The error in the logs is: 2020-12-02 18:00:18,435 DEBG 'start-script' stderr output: parse error: Invalid numeric literal at line 4, column 0 the only thing that differed from your instructions was that the new variable asked for both a VALUE and a DEFAULT VALUE. I put 'wireguard' in VALUE and left DEFAULT VALUE empty (I also tried just 'wireguard' in the DEFAULT VALUE field, same impact)
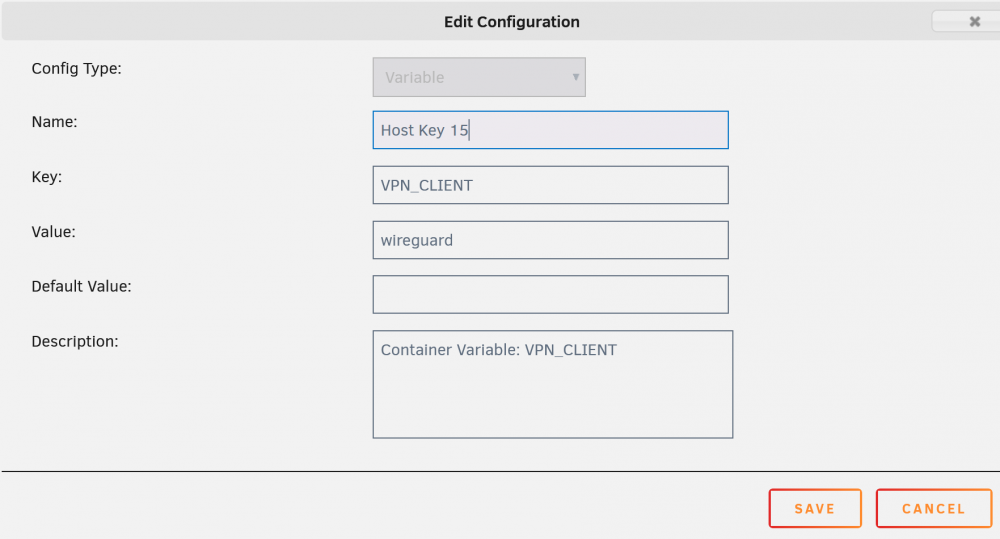
-
No, it's been running on port 8080 for months. I verified I'm hitting it at :8080 and that the config shows 8080. (see attached config)
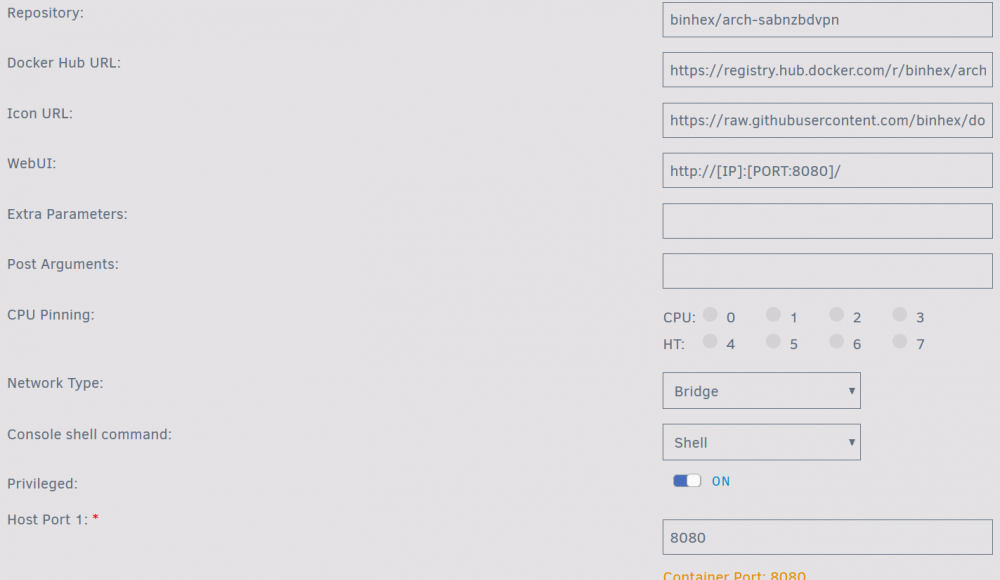
-
It does actually seem to be working, i.e. Sonarr passes the download client test. I just can't hit the web interface.
-
Thanks, I went ahead and stepped through #19 and restarted the docker. I still can't load the webpage and the logs still show the same warning I posted above.
-
I updated my docker for SABnzbdVPN this morning and now I can't get the web interface to respond (it just times out on port 8080). I'm seeing the following error in the logs: 2020-12-02 13:56:59 DEPRECATED OPTION: --cipher set to 'aes-128-cbc' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM). Future OpenVPN version will ignore --cipher for cipher negotiations. Add 'aes-128-cbc' to --data-ciphers or change --cipher 'aes-128-cbc' to --data-ciphers-fallback 'aes-128-cbc' to silence this warning. Could this be the reason I can't start it, and if so how do I change this? I use PIA for the VPN, and am running 6.9 beta 35 of unraid.


