

akawoz
-
Posts
31 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by akawoz
-
-
When going through this account migration it reminded me that Unraid still has a very old (and no longer active) email address.
I've successfully migrated using that old email address but when I attempt to change the email address I get the message that the email address was changed successfully, but then on logout and login I notice that it will only accept the old email address (which has reverted in the account settings).
I've attached a screen recording. Any ideas?-
 3
3
-
-
On 1/12/2022 at 1:35 PM, ufo56 said:
@infernix what memory modules you are using with X12SCA-5F ?
I'll chime in - using this same board with Unraid, have 4x of these (no ECC currently):
root@Preston:~# sudo dmidecode --type 17 | more
# dmidecode 3.3
Getting SMBIOS data from sysfs.
SMBIOS 3.3.0 present.Handle 0x0028, DMI type 17, 92 bytes
Memory Device
Array Handle: 0x0021
Error Information Handle: Not Provided
Total Width: 64 bits
Data Width: 64 bits
Size: 8 GB
Form Factor: DIMM
Set: None
Locator: DIMMA1
Bank Locator: P0_Node0_Channel0_Dimm0
Type: DDR4
Type Detail: Synchronous Unbuffered (Unregistered)
Speed: 2667 MT/s
Manufacturer: Corsair
Serial Number: 00000000
Asset Tag: 9876543210
Part Number: CMK16GX4M2Z3200C16
Rank: 1
Configured Memory Speed: 2667 MT/s
Minimum Voltage: 1.2 V
Maximum Voltage: 1.2 V
Configured Voltage: 1.2 V
Memory Technology: DRAM
Memory Operating Mode Capability: Volatile memory
Firmware Version: Not Specified
Module Manufacturer ID: Bank 3, Hex 0x9E
Module Product ID: Unknown
Memory Subsystem Controller Manufacturer ID: Unknown
Memory Subsystem Controller Product ID: Unknown
Non-Volatile Size: None
Volatile Size: 8 GB
Cache Size: None
Logical Size: None -
I'm been doing a bunch of testing after replacing my Xeon E5-2696v2 + GPU and Supermicro motherboard setup with a Z590 + i5-11400 combo using Quicksync and have arrived at a stable solution that allows me to hardware transcode with the latest Plex builds.
I have issues with any Unraid release from 6.10.0-RC1 including RC2 and the latest test builds beyond that. Regardless of my setup including blacklisting i915 in favour of GPU Top I still have crashes when Plex uses hardware transcoding (incl current build 1.25.5.5492). My server will hang (no video, keyboard, mouse) and drop from the network. Requires hard reset.
My solution:
Unraid: 6.9.2
Plex 1.25.5.5492
config/modprobe.d/i915.conf = options i915 force_probe=4c8b
no GPU top or GPU statistics installed
My force_probe=4c8b because when I tried 4c8a I got a message in dmesg that told me to use 4c8b instead. My CPU config is below for reference.
Hope this helps someone - this was very frustrating going from an incredibly stable Xeon build to an i5-11400 and having unpredictable crashes without anything in the logs.
Cheers!
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 39 bits physical, 48 bits virtual CPU(s): 12 On-line CPU(s) list: 0-11 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 167 Model name: 11th Gen Intel(R) Core(TM) i5-11400 @ 2.60GHz Stepping: 1 CPU MHz: 4203.711 CPU max MHz: 4400.0000 CPU min MHz: 800.0000 BogoMIPS: 5184.00 Virtualization: VT-x L1d cache: 288 KiB L1i cache: 192 KiB L2 cache: 3 MiB L3 cache: 12 MiB NUMA node0 CPU(s): 0-11 Vulnerability Itlb multihit: Not affected Vulnerability L1tf: Not affected Vulnerability Mds: Not affected Vulnerability Meltdown: Not affected Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled v ia prctl and seccomp Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RS B filling Vulnerability Srbds: Not affected Vulnerability Tsx async abort: Not affected Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtr r pge mca cmov pat pse36 clflush dts acpi mmx f xsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rd tscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperf mperf tsc_known_freq pni pclmulqdq dtes64 monit or ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc _deadline_timer aes xsave avx f16c rdrand lahf_ lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_ adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx 512f avx512dq rdseed adx smap avx512ifma clflus hopt intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke avx512_vb mi2 gfni vaes vpclmulqdq avx512_vnni avx512_bit alg avx512_vpopcntdq rdpid fsrm md_clear flush_ l1d arch_capabilities -
I had exactly this happening with my SAS drives under 6.9.1 when I started using the SAS spindown plugin, see my post here:
Same case, same backplane, but using SM motherboard with integrated HBA.
-
Did you ever get any further with this - I'm trying to manually add Mysterium as a docker container but with little luck (openvpn doesn't start).
-
On 3/11/2021 at 3:22 PM, akawoz said:
I'm seeing almost identical error numbers on two ST4000NM0023 (via onboard LSI SAS2308 on Supermicro X9DRD-7LN4F) one day after updating to 6.9.1 and also one day after running a successful parity check (on 6.9.0 just prior to upgrading to 6.9.1)
I've never seen issues with these drives before. Only other change was the installation of the SAS spin down plugin (which I'm now removing to test).Diags attached.


preston-diagnostics-20210311-1519.zip 212.9 kB · 0 downloads
Quick update - I uninstalled the SAS spin down plugin (as that was my only change apart from the the 6.9 -> 6.9.1 upgrade. Rebooted and no errors so far. Will leave for another couple of days and if no errors will reinstall the plugin to test -
9 hours ago, optiman said:
Now that there are at least two different Seagate drive models with issues after upgrading, can anyone confirm they upgraded with no issues with the same drives I have?
12TB
ST12000NE0008
fw: EN01
8TB
ST8000NM0055
fw: SN04
LSI 9305-24i x8 controller
I'm seeing almost identical error numbers on two ST4000NM0023 (via onboard LSI SAS2308 on Supermicro X9DRD-7LN4F) one day after updating to 6.9.1 and also one day after running a successful parity check (on 6.9.0 just prior to upgrading to 6.9.1)
I've never seen issues with these drives before. Only other change was the installation of the SAS spin down plugin (which I'm now removing to test).Diags attached.
-
Not sure if this bug turned up in the RC series but just noticed when I rebooted without internet access 3 times over the last couple of days that all of the docker containers show "Update Ready", when I check the containers for updates they return to correct status (normally "up-to-date")
-
@Squid was correct - problem was faulty SATA power cable - in this case a molex to SATA converter. Thanks for your help!
-
Thanks @johnnie.black - I rebooted between drive attempts. Agree, def hardware. Will progress +12hrs. Thanks for looking at my logs, cheers!
-
Haven't done the reseat process yet - but I'm wondering why the whole rest of the array is running just fine, except when I rebuild drive 12. Lots of reads and writes going on to the other 11 drives just fine. Remember the second drive I tried was connected using completely different cabling, to a different HBA (motherboard based).
-
Interesting - I've changed only one thing (with anything remotely to do with cabling, power, devices) in the last 6mths; plugged a NiMH battery charger into the same outlet that the server is plugged into. Did this about a week ago.
Will try a rebuild again with that removed. Feels a bit like voodoo, but it is a cheap one sourced from Aliexpress.
UPDATE: OK that wasn't the problem. Start getting write errors immediately when I start the array. Will power down and try to reseat everything tomorrow and report back.
-
OK, after running unraid for years I've found something to stump me.
I had a drive fail recently with write errors (drive 12/sdq) - giving the red cross in the drive list. I removed the drive from the array and ran an extended SMART test on it - which finished without error. I next ran a full pre-clear cycle (full read, full zero, full read) which also ran without error.
I added the drive back into the array thinking the drive controller had maybe remapped some bad sectors and I was OK again (for now), only to have the rebuild fail on the drive with more write errors.
Decided this drive really was bad so went to the store and purchased an identical WD Red 3TB drive. Conducted a full pre-clear cycle which it passed with flying colours. Added drive back into the array and it failed during rebuild with write errors. This replacement drive was added to a different controller (on-board vs LSI 9211-8i) with different SATA and power cables and mounted in a different chassis location.
So now I'm completely stumped. Two drives, both that pre-clear just fine, both fail during rebuild in around the same place (~ 5%) with write errors (different sectors listed).The only commonality is that they are both in drive position 12 and seem to fail very early in the rebuild process.
Anyone got any idea where I start troubleshooting this? No other issues with my array and unraid implementation; its been very stable for the last couple of years and normally has uptimes measured in many months at a time.
Diagnostics attached.
-
NZBGet is now updated to v17.0 but when I specify that version (or any of the testing versions) my container fails to compile from source.
https://github.com/nzbget/nzbget/releases
Latest version that works OK is v16.4.
Any ideas?
-
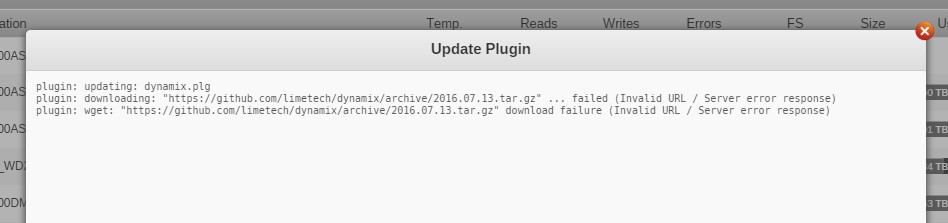
anyone see this with RC2 - WebGUI updates not working

-
OK team, well now I'm really confused:
My Win10 VM has gone from suspending at least once every 30 mins to running continuously all night.
The ONLY change I have made in that time was the recreation of my docker.img file (size stayed the same) which does live on the same SSD's as my VM qcow2 files. Will keep monitoring but I don't understand how this could be related.
-
Hmm, wonder of when this is happening it's because it's filling up from other stuff temporarily. I'd be curious what the cache drive free space reports as when you are seeing this pause behavior.
Its not actually my cache drive - I've got a 4TB WD RED that I use for cache (2TB+ free at any time) and a couple SSD's mounted with unassigned devices that hold the VM and appdata files. So don't expect any large temp data to be hitting that SSD.
Will do a new Win 10 VM install and see if behaviour is same.
Attached a full view (with SN's removed) :-)

-
How much free space on the cache device itself?
37GB or 18%
-
I bet your vdisk is running out of space.
Yep - that was my first guess, but nope:
https://goo.gl/photos/AcetDXn5Gatck3Qn8
-
You should do all of the post-install tuning things from this guide:
http://lime-technology.com/wiki/index.php/UnRAID_6/VM_Guest_Support
Also, no need to try to adjust SeaBIOS, it is not the issue.
Grasping at straws you see - sometimes regular PC BIOS have these settings that can override Windows config.
And I've done all of the wiki items prior to original post.
-
Out of the box Windows10 is in "Balanced" mode, which puts it to sleep after a few mins of inactivity.
In the "real" world this isnt an issue as you can set your machine to be switched back on with USB input (like moving a mouse or hitting a keyboard key).
to fix:
goto the power options in the classic control panel, change it to performance (you might need to expand the "show additional plans" bit to select it.
click change plan settings and make sure its set to never put the PC to sleep.
That should stop the VM being suspended.
Tried this - no change. See my original post :-)
-
Guys have been trying to troubleshoot this myself but have hit a dead end. I have a vanilla Windows 10 (slow ring) install that keeps entering sleep or suspend mode. Windows is not configured to sleep or suspend. I've generated an energy-report and nothing strange seems to be noted.
I've tried moving to fast ring, but no luck. Tried moving between power plans but no change.
Strange thing is that if I try to edit any of the standard power plans, there are no timers set under sleep (attachment).
XML config:
Energy report:
Last thing I was going to try was to get into SeaBIOS to see if some BIOS config was overriding the OS - but can't for the life of me trigger BIOS entry (using VNC).
EDIT: just tried this app: https://sourceforge.net/projects/stayawake/ but still enters a "paused state"
EDIT: I've followed this http://lime-technology.com/wiki/index.php/UnRAID_6/VM_Guest_Support prior to posting.


-
Solved this - but don't know how. Moved from Needo to Linuxserver's Plex and running at full speed again (around 12x).
-
Hi guys, my Plex Media Server has /tmp mapped to /transcode to store temp transcode files in RAM when playing back live. Server can easily sustain 8+ HD streams no problem at all.
When I chose to sync for offline playback on a phone or tablet I get the message from the app that the transcode process will take ~ 20 - 30 hrs.
Here's the process the above creates (after requesting sync on my Nexus 6p):
/usr/lib/plexmediaserver/Resources/Plex New Transcoder -i /mnt/movies/Cooties (2015)/Cooties (2015).mkv -filter_complex [0:0]scale=w=min(720\,iw):h=min(300\,ih):force_original_aspect_ratio=decrease[0] -map [0] -codec:0 libx264 -crf:0 20 -pix_fmt:0 yuv420p -maxrate:0 1500k -bufsize:0 3000k -preset:0 veryfast -x264opts cabac=0:8x8dct=1:bframes=0:subme=3:me_range=4:rc_lookahead=10:me=hex:cabac=0 -map 0:1 -metadata:s:1 language=eng -codec:1 aac -strict:1 experimental -cutoff:1 15000 -channel_layout:1 stereo -b:1 193k -f mp4 -map_metadata -1 /config/Library/Application Support/Plex Media Server/Cache/Transcode/Sync/7643863/8368136/4e3d92d364c3eaace1ad.mp4.temp -y -nostats -loglevel quiet -loglevel_plex error -progressurl http://127.0.0.1:32400/video/:/transcode/session/b3a625fc-f0f1-4ad1-8762-53198eaa24bb/progress
I notice that it rights the temp sync file to /config not /transcode - but that's OK because my appdata for Plex is on an SSD.
The server is mostly idle while the above it going with very low CPU and IO usage so it doesn't appear to be bottlenecked.
Anyone got any ideas or suggestions on how to diagnose this?








Drive failures + replacements larger than parity
in General Support
Posted · Edited by akawoz
more info
Don't ask how I got in this situation 🤦♂️
In my 22 drive array (chassis can handle 24 drives) the largest drives I have are 8TB.
I have dual parity.
I have two failed drives.
I have 4x 10TB replacement drives.
I was hoping to rebuild the two failed drives onto 10TB and then swap the dual parity for 10TB but of course unraid won't allow me to install a replacement data drive larger than parity.
Is there any way at all to have unraid treat my 10TB replacement drives as 8TB temporarily or will I need to buy some 8TB drives (would really rather not).
Any clever ideas?