




syrys
Members
-
Joined
-
Last visited
Everything posted by syrys
-
Updated OLD unraid server with some difficulty. But you are spot on, i can now use unassigned devices to mount the drive. Thank you so much for the help
-
Hmm, yeah thought it was something like that. Hmm, seems a bit risky though, thats one of the reasons im starting fresh with a new build. Are there any good tools that allow backups and rollbacks if the update didnt work as expected? Maybe a tool to take a backup of the flash drive and restore it (assuming its that simple to roll back, hopefully)?
-
This is a brand new drive, i put it in the NEW server and initialised a new unraid array with two drives (this is one of the two) with no parity. then i unplugged it from the NEW server, and then plugged it into the OLD server (SATA directly to the MB), and then used unassigned devices plugin on the OLD server to click mount (what happened then is in the post above). long story short, the error is from the OLD server. im mounting a new server's drive into the old server.
-
ok, so i moved the array disk from the NEW unraid server to OLD unraud server. clicked MOUNT under the unassigned devices for the 18TB drive, the button changes to "mounting" and then unraid loading animation pops up, then page refreshes and the drive still had the MOUNT button (as if mount failed). The system logs show the following: Mar 10 00:31:30 karie unassigned.devices: Adding disk '/dev/sdb1'... Mar 10 00:31:30 karie unassigned.devices: Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdb1' '/mnt/disks/ST18000NM000J-2TV103_ZR53FQDA' Mar 10 00:31:30 karie kernel: XFS (sdb1): Superblock has unknown read-only compatible features (0x8) enabled. Mar 10 00:31:30 karie kernel: XFS (sdb1): Attempted to mount read-only compatible filesystem read-write. Mar 10 00:31:30 karie kernel: XFS (sdb1): Filesystem can only be safely mounted read only. Mar 10 00:31:30 karie kernel: XFS (sdb1): SB validate failed with error -22. Mar 10 00:31:30 karie unassigned.devices: Mount of '/dev/sdb1' failed. Error message: mount: /mnt/disks/ST18000NM000J-2TV103_ZR53FQDA: wrong fs type, bad option, bad superblock on /dev/sdb1, missing codepage or helper program, or other error. Mar 10 00:31:30 karie unassigned.devices: Partition 'ST18000NM000J-2TV103_ZR53FQDA' could not be mounted... Does that give any insights?
-
There are raid controllers involved (but i followed some steps to correctly configure a raid controller according to unraid tutorial like 8 years back - on my old server), but im plugging it directly into a motherboard sata post on the old server. Can you clarify, if i initialise an array on the new server (without parity), and then unplug one of the drives of said array, then plug it directly on to the OLD unraid server (sata connection directly to the motherboard), should i then be able to click MOUNT on this migrated drive on unassigned devices without doing anything else on the old server (without deleting partitions, without formatting or anything)? If this is suppose to work (it doesnt for me), please give me a confirmation and i will attempt it again tomorrow and post an actual error msg here (i didnt bother because the error felt like it was never meant to work that way, i figured that the array used a different file structure/format or or some config that unassigned devices doesnt understand). also note that the OLD server is running unraid 6.8.x (so unassigned devices plugin is probably pretty old - probably havent updated in many years), and NEW server is ... well... NEW (unraid 6.12.x etc).
-
No absolutely, i think sadly everything implies faulty UPS. It is what it is, unfortunately its just a bad purchase for me. atleast on the bright side, i can repurpose it for a non smart usecase - battery backup my router or something (the UPS is still very functional, just not the data). Thank you for all the sanity checks and suggestions
-
Current state: I have an old unraid server with 10x 8tb drives. I just built a new unraid server with a bunch of 16tb drives (I haven't really started the array or setup any data/apps yet, it's new new). At this moment, I have both servers running at the same time. I do not intend to reuse the 8tb drives from the old server, I have enough new 16tb drives (about 5 of them) at hand for my needs. Also note, old server is running unraid 6.8.x and new is 6.12.x - incase I need to watch out for anything? What I want to do: I want to copy over about 40tb of data from the old unraid server to the new server. What are my best options? I do also like to minimise any downtime (I will eventually fully setup the new server and just swap the two once data is migrated and all the apps/dockers are installed), and I want to do the migration as soon as possible (no huge hurry though). I could easily copy data over the network. But that's limited to 1 gigabit (I only have a gigabit network and old server only supports gigabit even if network supports it). I understand that I can not put a parity in the new server to speed up copy, but it's still limited to gigabit. I tried initialising the array on new sever (without parity), and then physically moved (and plugged in) one of the array drives to the old server hoping that I can mount it as unassigned devices to copy data over to it (copy inside the same machine using sata speeds rather than saturating the network), but i was unable to mount the new drive into the old machine (I assume since I initialise it as an array on the new server, file systems are different? What's the correct/best way here? Are there any tools I can use or steps I can follow?
-
The cable that was on the box looks like that, are there variants of the cable that I should be concerned about? Also the cable from my old apc ups also looks like that (this was maybe 8 years old), and I also tested with that cable.
-
Im just playing around with it on windows. The powerchute software complains that it cant find the device. When i plug it in, sometimes windows device manager's USB section displays nothing new. But sometimes device manager shows "unknown usb device (device descriptor request failed)".
-
Unfortunately its not under warranty as far as im aware as i purchased it secondhand (new/unused/unopened but dont have any original paperwork for warranty). Is damaged USB controller a common issue? do you know if there is anything i can do to make sure that this is the case, or is my debugging basically prove it already? Or do these things have like firmware upgrades sort of thing that i may need to do (never had to do anything like that for the old UPS, but this seems more modern than the old one i have)?
-
just to clarify the new Unraid server that i was testing this on has never had any other ups plugged in (still now). its a fresh install of unraid (couple of days ago). So there shouldn't be any older config to worry about. The older unraid server i used to double check the UPS on however had another UPS plugged in (and that ups works just fine using the built in apc ups daemon).
-
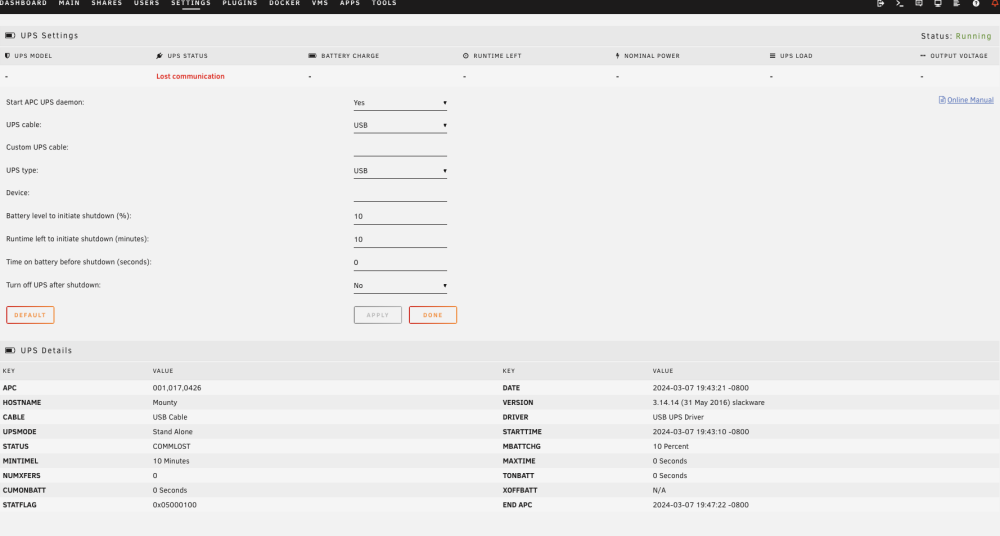
I just recently picked up an APC BE850G2 UPS. Ive also recently just built a new Unraid system. Was trying to connect up the new UPS into the new system, and im unable to get it connected. Basically what i did was, connect up the data port of the UPS to the Unraid server, then used the built in UPS settings to enable APC UPS Daemon, and it always just says "Lost communication". Screen looks like this: Ive tried different USB ports (incl USB 2.0 ports according to the MB manual), still no difference. ive done `lsusb` on command line and it doesnt show anything that implies the UPS root@Mounty:/etc/apcupsd# lsusb Bus 002 Device 002: ID 174c:3074 ASMedia Technology Inc. ASM1074 SuperSpeed hub Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 004: ID 0951:1666 Kingston Technology DataTraveler 100 G3/G4/SE9 G2/50 Bus 001 Device 003: ID 174c:2074 ASMedia Technology Inc. ASM1074 High-Speed hub Bus 001 Device 002: ID 0b05:19af ASUSTek Computer, Inc. AURA LED Controller Bus 001 Device 009: ID 8087:0026 Intel Corp. AX201 Bluetooth Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub As i mentioned, i also already have an OLD Unraid server that also has an OLD APC UPS connected to it. So to test things, i connected the new UPS to the old server (using the same OLD cable that already works on the same USB port that already works on the old server), and the old server doesnt detect this either (same "Lost communication"). So, its not the USB port, its not the USB cable. Its either the software, drivers, or faulty UPS. New Unraid running on "6.12.8". Old Unraid running on "6.8.3". When googling around, ive seen comments from other users implying that this model of UPS works fine with unraid (for them). ive also tried using NUT (i dont think i actually need to), but what ever i try, it seems to imply that it cant find a device. Can anyone help me debug this or let me know if they have any suggestions? Assume in a bit of a noob. Any help is appreciated, im at the end of the line atm. I guess the next thing to try is to plug it into a windows machine and see if that can detect the UPS (unsure how to test this, but ill try figure that out over the weekend).
-
Alright, here is my "hacky" solution to the above problem. It works for now, if someone has a better solution, let me know. Install User Scrips plugin (if you dont have it already), and add the following script: #!/bin/bash mkdir /mnt/disks/rclone_volume chmod 777 /mnt/disks/rclone_volume obviously you can set -p flag on the mkdir if you need nested directories or if you have issues with sub directories not being there, but from trial and error on my unraid setup, at boot (before array starts), `/mnt/disks/` exist. edit the script to include all the mount folders you want (if you have multiple mounts), and chmod 777 each of them. Set the above user script to run on every array start. Just to make sure my container doesnt start prior to this finishing (unsure if it can happen?), i added a random other container above my rclone container (a container that doesn't need drives to be mounted), and set a delay to 5 secs (so rclone container waits 5 seconds). This might be unnecessary. Hope it helps someone.
-
Hmm, ive been banging my head against the desk all day, can someone here give me some advice on how to fix this? So this issue that was already mentioned several times, i get this. But the solution mentioned does not work after server restart. Executing => rclone mount --config=/config/.rclone.conf --allow-other --read-only --allow-other --acd-templink-threshold 0 --buffer-size 1G --timeout 5s --contimeout 5s my_gdrive: /data 2020/09/02 14:00:21 mount helper error: fusermount: user has no write access to mountpoint /data 2020/09/02 14:00:21 Fatal error: failed to mount FUSE fs: fusermount: exit status 1 First of all, i have the docker installed, and all the settings as mentioned throughout this thread. I do also have couple of extra rclone flags passed in, but these arnt the issue. So, lets say the mount point defined is `/mnt/disks/rclone_volume`, when i restart the server (docker auto starts), and i see the above mentioned error. If i stop the docker, and do `ls -la` i see the ownership is `root:root` for `/mnt/disks/rclone_volume`. alright, sure, `chmod 777`, `chown 911:911` the rclone_volume, then restart the docker, cool, everything works. `/mnt/disks/rclone_volume` gets mounted correctly (`ls -la` shows 911:911 great), i can browse the files, no errors in the docker logs. Sweet, everything is sorted right? No, unfortunately not. The moment i reboot the unraid server (remember the docker auto starts), i get the above mentioned error on the docker logs, and obviously the drive is not mounted. so back to `ls -la` on the `/mnt/disks/rclone_volume`, and its back to `root:root` and `755`. So basically, every time start my server, i have to manually `chmod 777` and/OR `chown 911:911` the `/mnt/disks/rclone_volume`, and then start the docker? Any idea whats causing this? I cant be the only one having this issue can i? So, essentially, for this docker to successfully mount a drive, it needs the mount destination to either be `777` or `911:911`. But for what ever reason, at rebbot/start or unraid, the ownership of `/mnt/disks/rclone_volume` gets reset to `root:root` even if you had set it to `911:911` prior to restart (i assume user 911 doesnt exist at the very start, so it defaults to root?). at the start of the boot, unraid (?) also sets `/mnt/disks/rclone_volume` to 755 (even if you had it set to 777 before restart). wtf? could this be related to another plugin i might have?
-
Hmm interesting. Thanks for the info guys. So, that means, if i want to get 4k transcoding to be done in my plex docker, i need to upgrade to like a 7th/8th gen intel CPU/mobo (since GPUs arnt supported)? If i were to upgrade, does it matter what the CPU is, can i just upgrade to a cheap 8th gen i3 like the i3 8100? would that be enough? I guess my alternative is to run the plex server in a windows VM, thats probably a good option. Is there any instructions on how to pass through the GPU to my windows VM? Has anyone done this successfully?
-
Hey Guys, Im trying to get some step by step instructions about how to actually install a GPU on my unraid server and get plex server (running as a docker on unraid) to use that GPU to do transcoding. My unraid server runs on a i7 4770 cpu which isnt enough for 4k h265 transcoding, so i just installed a GTX 970 (might move to a 1030 or 1050 later) on the box. Although the hardware is installed, im not sure how to: 1. Check if the GPU is correctly installed (that OS/Unraid can actually see it)? 2. How to get my plex docker (linuxserver/plex) to actually make use of this GPU. Ive seen couple of threads about this, but the instructions wernt too clear for me (im a noob at these things). Can someone give me some instructions if they can? would be greatly appreciated I tried to follow this: On this step modprobe i915 chmod -R 777 /dev/dri I got the following error: chmod: cannot access '/dev/dri ': No such file or directory There were couple of other threads about editing syslinux.cfg and "go" file, but i have no idea where they are, how to edit them, and what to edit them to. So im pretty stuck Any help appreciated. PS: im running unraid 6.6.5
-
ah, fail. i thought it used to auto update OS =/ ah well, time to update
-
my unraid is set to auto update but currently at v6.4.1. i dont see this option. i assume its not currently on the main releases.
-
I know you guys keep suggesting that this is a user/config error time and time again. but after a year or so of struggling with this, my issue turned out to be jackett. i dont really know much about docker, and no one really gave me any good way to calculate disk usage per container, so i just deleted one container after another (order of least important). my docker size was going up by about 2-3%/day, so i would delete one container each day to see when the increase stopped. turned out that the culprit for me was jackett. it was likely saving logs or something somewhere it shouldnt have as it was configured correctly. As i mentioned, ive been struggling with this for a long time, ive made sure that every configurable setting in every container was configured correctly. something else you can try is, earlier in this thread, someone answered my question about ssh-ing into docker. If you have time to try it, you could try ssh, then use some disk/folder usage command to narrow down exactly which folder/files might be the cause, then submit a bug report to them. hope this helps.
-
Yeah i did, but to do so, you had to turn off docker. I simply just followed squid's instructions: For those that know about docker, is there really no way for one to browse into a docker containers file system and inspect/delete a file? Say you want to locate and delete a log fine manually, and you are sure its just being saved inside the docker, is there really no way to browse into the docker's file system and try locate and remove said file(s)? This would solve most of our problems (although hackey, its still a viable solution).
-
Haha i dont mind. Maybe suggestions you get might help me with my issue too (fingers crossed)
-
This is my output: > du -h -d 1 /var/lib/docker/ 0 /var/lib/docker/tmp 9.6G /var/lib/docker/containers 22G /var/lib/docker/btrfs 12M /var/lib/docker/image 68K /var/lib/docker/volumes 0 /var/lib/docker/trust 84K /var/lib/docker/network 2.4M /var/lib/docker/unraid 0 /var/lib/docker/swarm 32G /var/lib/docker/ Not really sure what this is actually telling me though
-
Tried this, but the numbers of this doesnt add up at all. The size column adds upto maybe 3GB at max (3gb virtual, <500mb normal). But my docker usage is well over 18gb. So yeah... CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE d43779fb64f6 linuxserver/plex "/init" 10 days ago Up 8 days plex 307.9 kB (virtual 432.1 MB) d6dca3fe11f5 linuxserver/sonarr "/init" 3 weeks ago Up 8 days 0.0.0.0:8989->8989/tcp Sonarr 137.1 MB (virtual 643.4 MB) eed3a5e07642 linuxserver/radarr "/init" 6 weeks ago Up 8 days 0.0.0.0:7878->7878/tcp radarr 27.62 MB (virtual 535.3 MB) 2731688ca5f1 linuxserver/sabnzbd "/init" 6 weeks ago Up 8 days 0.0.0.0:8080->8080/tcp, 0.0.0.0:9090->9090/tcp sabnzbd 339.6 kB (virtual 271.3 MB) 61c0ac7c92c6 linuxserver/deluge "/init" 9 weeks ago Up 8 days deluge 589.8 kB (virtual 172.3 MB) 0cbc1ab01f86 google/cadvisor:latest "/usr/bin/cadvisor -l" 3 months ago Up 8 days 0.0.0.0:8081->8080/tcp cadvisor 0 B (virtual 57.32 MB) cd9f8971ca71 dreamcat4/jackett "/init" 10 months ago Up 8 days 0.0.0.0:9117-9118->9117-9118/tcp jackett-public 18.92 MB (virtual 355.4 MB) e010e90c85bd linuxserver/plexpy "/init" 11 months ago Up 8 days 0.0.0.0:8181->8181/tcp plexpy 128.1 MB (virtual 243 MB) 2386dbb08d28 coppit/duckdns "/bin/sh -c /root/duc" 11 months ago Up 8 days DuckDNS 144 B (virtual 237.6 MB) b6471e1de692 linuxserver/htpcmanager "/init" 11 months ago Up 8 days 0.0.0.0:8085->8085/tcp htpcmanager 31.39 MB (virtual 148.7 MB)
-
Unfortunately i still havent found a solution for this original issue. Im glad that you atleast have a good idea what app is causing your issue. In my case, i have no idea still (and i dont have a clone system to test it out) For starters, it would be super helpful if there was a way to find out the actual HDD usage of every docker running on the system (so we can nail down the culprit). And once we nail down the culprit, atleast you can dive into try solve the problem or go complain to the docker developer about the issue. Ah well, for the time being, im just increasing the docker space allocation. I hope the usage increase is slower than the consumer SSD size improvements haha
-
Can anyone help me with this? My docker image is now at 85% I have not installed or done any changes since my earlier post. The links from Squid does not work for me, so i cannot check the issue he is refferings to. Since the last post, i have done few things to debug but with no luck. Using ssh, I tried getting a list of docker containers using docker ps -a Then exported every single docker container one by one into tars using: docker export container_name > container_name.tar #for example docker export plex > plex.tar Looked at the file sizes for the resulting tars, and they barely add upto 3-4gb as expected. But my docker image is 20gb and its hitting 85% usage which is 17gb. What on earth is going on? Is there really no way to accurately look at the size of each container?

