




newerNan
Members
-
Joined
-
Last visited
Everything posted by newerNan
-
Nevermind, physical power button has appeared to triger a safe shutdown. Restarted now, everything looks good and normal. Will kick off a parity check to be safe. Thanks for the assistance.
-
Thanks for your reply @JorgeB I definitely wouldn't have expected a power issue, its a highend Corsair PSU, running off a UPS, but ok, stranger things have happened. New issue, stopping the array or trying to shutdown appears to do absolutely nothing. The log is 100% full at the moment, perhaps related to it not responding to these actions, but i also can't figure out how to clear that down without a reboot. Without any new log entries to view, i have no idea why its not stopping the array or shutting down. Any advice to get a clean shutdown? Thanks,
-
Sorry, i forgot to mention, that everything appears to still be working fine. Dockers are fine, remote array access over SMB is fine, but not tested in anger.
-
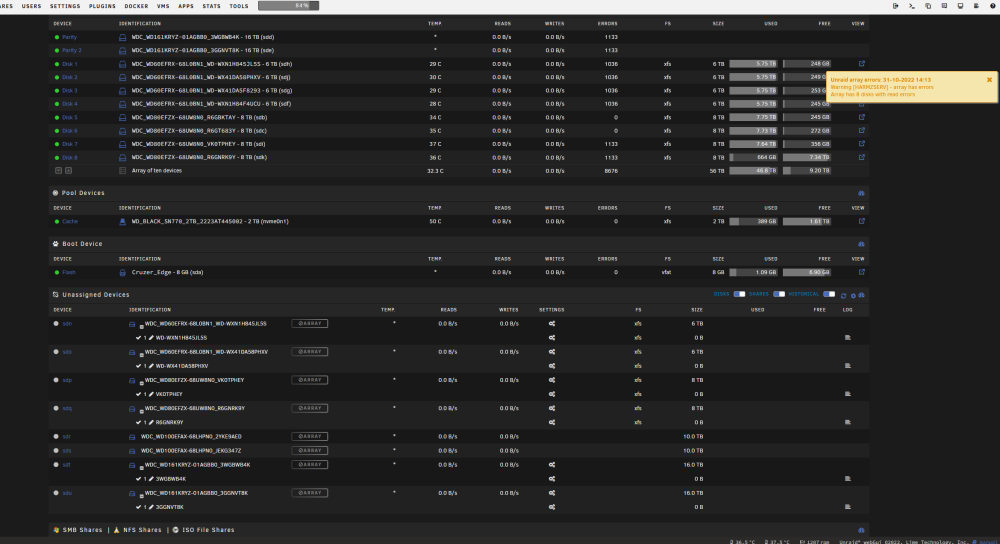
Hi, Never had read errors before, dont know what to do. Any help would be greatly appreciated. Unraid is reporting that 8 drives have suddenly encounted read errors. I find that somewhat hard to believe. Some remarks: Unassigned drives is suddenly showing all 8 of these drives with new sd[x] id's with some sort of failed array icon, while they appear to still be in the array. My genuine Unassigned drives arent even showing up any more (maybe a limit to how many the dashboard can display) Only 2 random 8TB drives didnt have any errors, every other array drive (inc. 2xParity) did. 6TB drives all have 1036 Errors, and 8TB+ have 1133, suggesting that these failed reads were across all drives at certain ways through the data. But i think it was fine this morning, so happened today at somepoint. I havent done a partiy check in over a month, so why would all drives be read at the same time? Some drives are connected via an HBA, some direct to motherboard controller. Parity is definitely on motherboard, 6TBs are definitely on HBA, so it doesnt appear to be a controller issue, because affected drives are spread between both. im running 6.10.3 Between 2pm-3pm today, I did attempt to start a years old VM accidently, that failed miserably erroring on all sorts of issues. It wasnt something i expected to work, it would have been attempting to pass through GPUs that didnt exist, and used a drive image (or potentially a physical disk) for the OS that were no longer present. I feel this might have been around the time the read errors happened, but i dont understand why launching a VM would affect the array's data drives. Please help. I want to ensure my data is safe, my offsite backup hasn't been working for about 2 months, have been meaning to sort it out. Tempted to restart the server if it just resolves a one-off issue, and sorts out the unassigned drives plugin, but dont want to lose any diagnostics data. Any assistance appreciated, thanks, harmzserv-diagnostics-20221031-1515.zip
-
Hi, I'm trying to mount a WD Gold 6TB Drive, that's 4KN. It mounts absolutely fine, formats fine with NTFS,XFS or exFAT, and if i share it, i can see the full 6TB is available and working. However, if I pass it through to a windows VM, it shows as 3 partitions, two of which are unallocated. if i try and create a new partition within windows DSKMGR it just errors. Tried with diskpart too, errors on any action. Is there a special way to do this for 4KN drives, or is this issue nothing to do with 4kn? Im running 6.6.6 with UD: 2019.01.22a I've attached screenshots here, showing details of config. I have another Seagate 2TB drive that mounts and passes through to windows fine. Thanks,
-
Please could we get this docker updated to qBittorrent v4.1.1, as some trackers have blacklisted all previous v4.x releases. Thanks,

