




UnspokenDrop7
Members
-
Joined
-
Last visited
-
I just added this container to my Unraid server and got this same message when I surf to the WebUI. Using IP address or FQDN does not matter. (http://10.0.99.114:5678 or http://n8n.home.local:5678). I did followed the instructions on how to set up the container. Does the container answer on any other port using HTTPS? If that would help. Or is the only option to actually disable secure cookie?
-
I "solved" my issue with the WebUI. After reading some of the latest posts regarding the memory leak issues I decided to install a fresh container. After shutting down my old container I renamed the appdata folder. Then I changed the container repository from linuxserver/unifi-controller:LTS to linuxserver/unifi-controller:5.11.50-ls40 (as proposed) and installed my new container. Now I could reach the WebUI! I then restored a backup from a year ago (2019-05), yes a year ago. And first everything was good, I signed in with my usual user/pass, started looking around (no changes made!) and suddenly I lost connection to the WebUI. I could not get it back. I fail to see the logic here. A new fresh container and a backup from a year ago, well before my issues started. First working, then not. Anyway, I removed the appdata folder and started from a clean install again. This time I did all, or at least all necessary, config manually to get my wifi back online. Now it has been working for at least 24h. Hopefully this helps you other guys having this issue... maybe you are more lucky with your backup, if you have any.
-
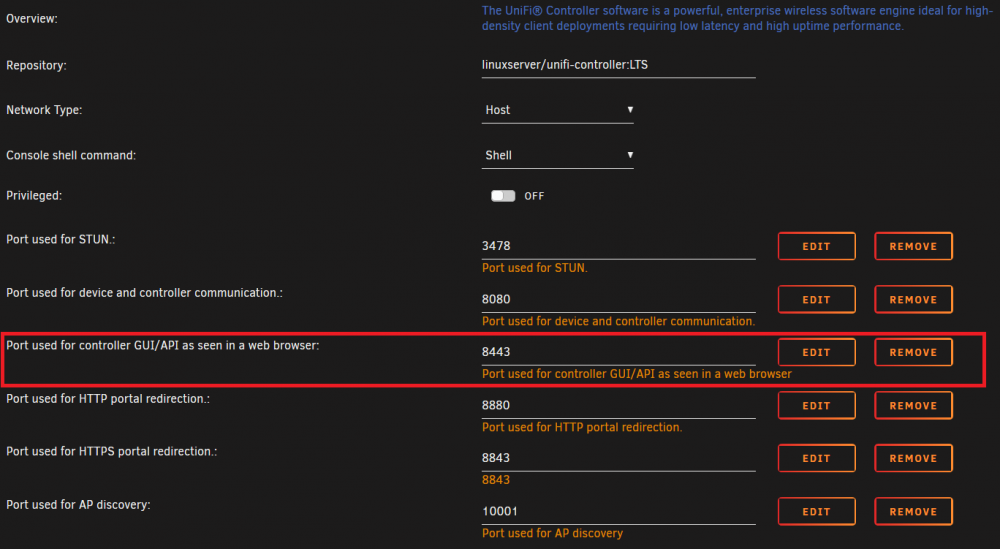
Aha, I think I understand you now! You mean the container seems to be fixed or hardcoded to use TCP 8080? That should be no problem for me. I have no other docker container using port 8080. Or any other service running on my Unraid host using this port. I never have. On the other hand, I have never used 8080 to access the WebUI. The "instructions" (see attached image) says I should use 8443. So I have always used 8443. Anyway, just to make sure. If I switch to bridged mode and maps host port 8082 to container port 8080 I get another issue. My browser gives me SSL_ERROR_RX_RECORD_TOO_LONG. Command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='unifi-controller' --net='bridge' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e 'PUID'='99' -e 'PGID'='100' -p '3478:3478/udp' -p '8082:8080/tcp' -p '8443:8443/tcp' -p '8880:8880/tcp' -p '8843:8843/tcp' -p '10001:10001/udp' -v '/mnt/user/appdata/unifi-controller':'/config':'rw' 'linuxserver/unifi-controller:LTS' 7b17630e25bbc111b6c73049741287990777930e4ab791bdac1890762a9cbda3 The command finished successfully! Again, if I look at the "instructions" it says port 8080 is used for "device and controller communications". So to my understanding 8080 should not be used for the WebUI. Or am I missing something here?
-
I have used this docker container for years and I have always reached the WebUI via TCP 8443. I'm 100% sure of this as have a bookmark in my browser pointing towards https://v.x.y.z:8443/ Anyway, I tried to access the WebUI using 8080. But there is no answer on this port either. I wish I could have a look at the web server configuration of the docker container. But I'm not sure even where to start looking... or if I'm able to read the configuration once I find it. Maybe I at least would be able to verify what port it is listening on.
-
Hi all, I just noticed the web UI is not working anymore, browsing is timed out. I have not made any changes. Not sure if there have been any updates of the container recently. But otherwise the container seems to work, I can access the CLI. I need some help on how to proceed the troubleshooting. Command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='unifi-controller' --net='host' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e 'UDP_PORT_3478'='3478' -e 'TCP_PORT_8080'='8080' -e 'TCP_PORT_8443'='8443' -e 'TCP_PORT_8880'='8880' -e 'TCP_PORT_8843'='8843' -e 'UDP_PORT_10001'='10001' -e 'PUID'='99' -e 'PGID'='100' -v '/mnt/user/appdata/unifi-controller':'/config':'rw' 'linuxserver/unifi-controller:LTS' b0695b8cfaeea76cb8ea11d7829e008d96e482a8ec1f925cc602c54a9f46f560 The command finished successfully! [s6-finish] sending all processes the KILL signal and exiting. [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 10-adduser: executing... [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 10-adduser: executing... usermod: no changes ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] 30-keygen: executing... [cont-init.d] 30-keygen: exited 0. [cont-init.d] 99-custom-scripts: executing... [custom-init] no custom files found exiting... [cont-init.d] 99-custom-scripts: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done.
-
Wonderful, that's the solution! Thank you very much binhex!
-
I have the same issue, the default plugins of Extractor and Label does not stick as activated after a restart of the container. The above workaround did not work for me. But I'm unsure I actually got it right. @PieQuest, do you really mean the data folder, not the config folder? Anyway, did someone found any solution to this? I moved from linuxserver's deluge to this one as I had other problems with that one... WebGUI was not working if not sticking to version 1.3.15 (I think it was). docker-install.txt docker-log.txt
