




Homerr
Members
-
Joined
-
Last visited
-
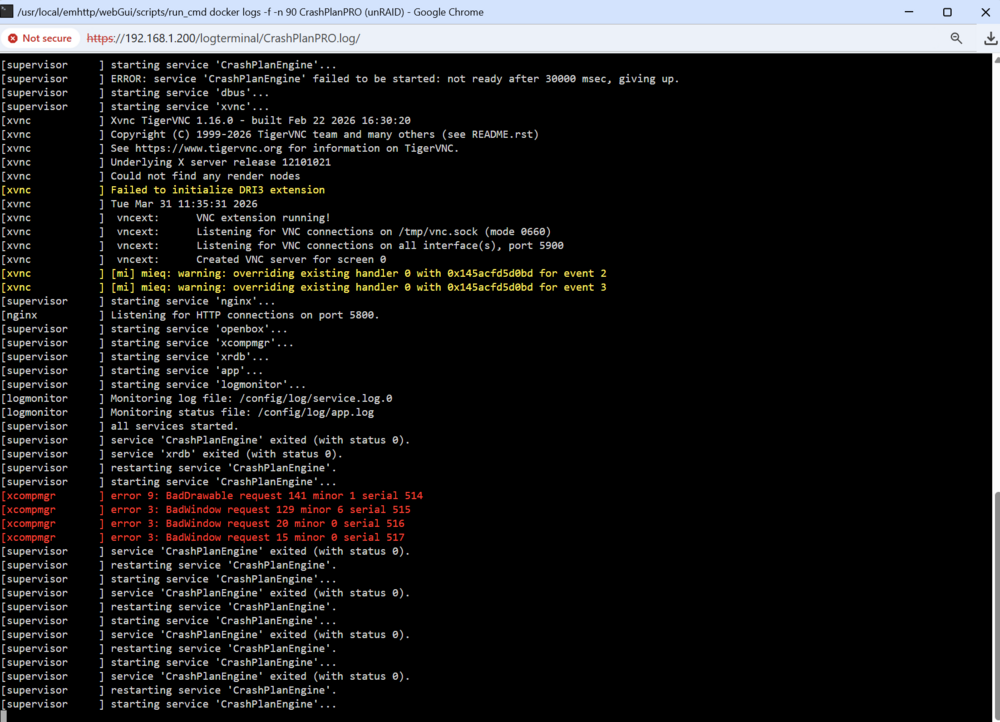
I have some new information. I did remove the previous instance, renamed the CrashplanPro folder in \appdata, and deleted the docker image to force a download of the newest v26.03.2 version. After install was done and only on the first startup of CrashplanPro did this red text show up. Does this help at all? The logs are also from this first startup, including the CrashPlanPro.log that the red text is in. I don't know if the red text has always been there on first startup or not since this has been happening. engine_error.log engine_output.log CrashPlanPro.log service.log.0
-
Those files are attached. service.log.0 engine_error.log engine_output.log
-
Yes. Still having this issue. text error warn system array l.txt
-
I tried a fresh install by: removing the docker image in Unraid deleted the appdata directory (renamed it to CrashPlanPro_bad) pulling a new image from Apps configuring with my account and system information (username, password, max memory) When the container starts and I look at the logs, I see this over and over again: [supervisor ] service 'CrashPlanEngine' exited (with status 0). [supervisor ] restarting service 'CrashPlanEngine'. [supervisor ] starting service 'CrashPlanEngine'... is there anything else that needs to be deleted/moved/renamed other than the CrashplanPro directory in the appdata folder? crashplan.txt
-
If I just delete the docker and then delete the docker image (hitting the X under the title name as if adding a new one), is there anything else that I should clear from the system in order to prepare for a clean download and install of the docker? I ask because I did try this when I was first having the issue, but it all seemed to install the docker and run with the same issue so it seems like there is something on my Unraid that is missing or corrupted that is causing the failure. And to verify - is there anything, beside the docker itself, that is needed for the CrashplanPro docker? (I saw one random post about an nvidia driver that is spurring this question.) I just want to try a fresh install again but eliminate any variables first.
-
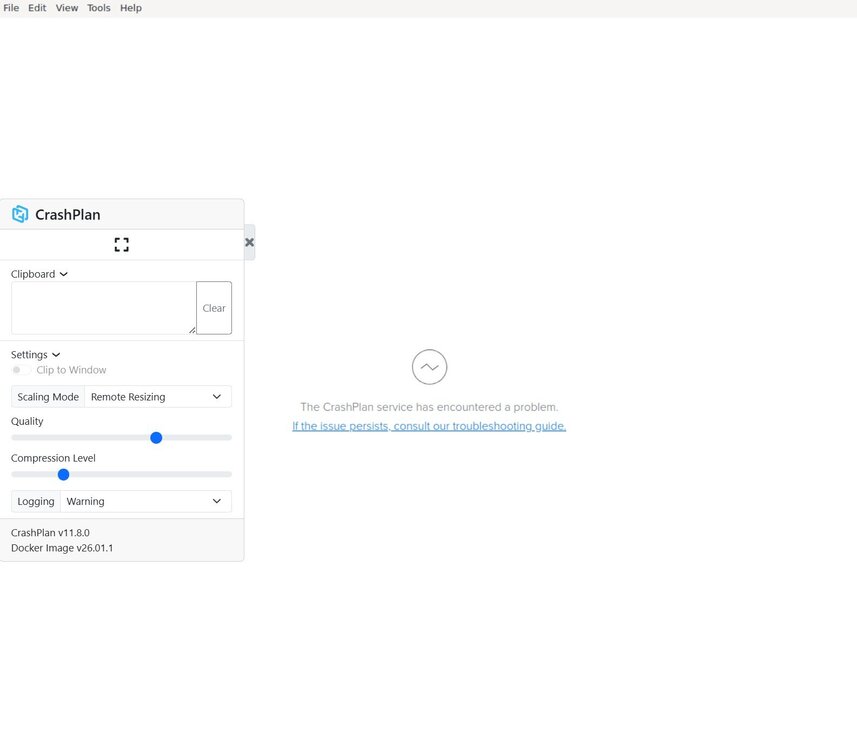
Yes, there have been several reboots while trying to solve this issue. I also did verify that my Crashplan Pro account is in good standing. I normally use Chrome, but have also tried to open this in Firefox with no luck either. Attached is a pic of what I get, including the copy/paste sidebar.
-
A container that had worked in the past for several years.
-
CrashplanPro container starts and runs but the container logs just show the crashplan engine starting and restarting over and over again. I opened a shell in the container to look at /config/log/service.log.0 and it shows this error: [01.01.26 19:22:59.801 ERROR main com.backup42.service.CPService] Error starting up, org.bouncycastle.crypto.fips.FipsOperationError: proportionate test failed STACKTRACE:: org.bouncycastle.crypto.fips.FipsOperationError: proportionate test failed at org.bouncycastle.crypto.fips.FipsStatus.moveToErrorStatus(Unknown Source) at org.bouncycastle.crypto.fips.ContinuousTestingEntropySource.getEntropy(Unknown Source) at org.bouncycastle.crypto.fips.HashSP800DRBG.getEntropy(Unknown Source) at org.bouncycastle.crypto.fips.HashSP800DRBG.init(Unknown Source) at org.bouncycastle.crypto.fips.HashSP800DRBG.<init>(Unknown Source) at org.bouncycastle.crypto.fips.FipsDRBG$HashDRBGProvider.get(Unknown Source) at org.bouncycastle.crypto.fips.DRBGPseudoRandom.lazyInitDRBG(Unknown Source) at org.bouncycastle.crypto.fips.DRBGPseudoRandom.getSecurityStrength(Unknown Source) at org.bouncycastle.crypto.fips.FipsSecureRandom.getSecurityStrength(FipsSecureRandom.java:102) at org.bouncycastle.jcajce.provider.BouncyCastleFipsProvider.getDefaultSecureRandom(Unknown Source) at org.bouncycastle.jcajce.provider.BaseSignature.engineInitSign(Unknown Source) at java.base/java.security.Signature$Delegate.engineInitSign(Unknown Source) at java.base/java.security.Signature.initSign(Unknown Source) at org.bouncycastle.operator.jcajce.JcaContentSignerBuilder.build(Unknown Source) at com.code42.crypto.declarative.C42CryptoCertificateApi.generateCertificate(C42CryptoCertificateApi.kt:91) at com.code42.crypto.declarative.C42CryptoCertificateApi.certBuilder$lambda$0(C42CryptoCertificateApi.kt:46) at com.code42.crypto.declarative.C42CertificateBuilder.generateCertificate(C42CertificateBuilder.kt:60) at com.backup42.service.CPService.createNetworkLayerConfig(CPService.java:832) at com.backup42.service.CPService.constructPeerControllers(CPService.java:782) at com.backup42.service.CPService.start(CPService.java:456) at com.backup42.service.CPService.main(CPService.java:1417) Complete service.log.0 is attached for this startup. Anyone seen this before and have any ideas how to resolve? Application: CrashPlan Application Version: 11.8.0 Docker Image Version: 25.12.4 Docker Image Platform: linux/amd64 CrashPlanPRO_service.log.0.txt
-
As an update I got a "Genuine LSI 9207-8e SAS HBA 6Gbps PCI-E 3.0 P20 IT mode for ZFS FreeNAS unRAID" from ArtofServer. The upgraded fans are also great, this has all been running for a few months now without issue.
-
Update - So, I guess I was just looking for a JBOD case. It took a bit more looking at what was out there and from browsing Supermicro manuals it looked possible to do what I wanted. I ended up getting a "SuperMicro CSE-826 12x LFF 2U Barebone W/ Trays 2X PWS-920P-SQ" off of ebay. It came with a SAS826A backplane, and per the video above on Supermicro backplanes I also got a BPN-SAS2-826EL1 and that is now in the server instead. It took a couple of weeks to get the CSE-PTJBOD-CB2 power board. The case came with a couple of SFF-8087 cables, those go to a "CableDeconn Dual Mini SAS SFF-8088 to SAS36P SFF-8087 Adapter in PCI Bracket" (Amazon) and then a 2m long SAS SFF-8088 to SFF-8088 Cable. I also got a Supermicro MCP-290-00053-0N rail kit for my rack. I have fired up the case and the 3 case fans absolutely HOWL. The power supply is actually very quiet, as advertised. I have ordered a FAN-0104L4 replacement fan that seems to be the go-to replacement. If I like it I'll order 2 more to quiet it down. So, I built a JBOD case. I had an Adaptec card that I had hoped to use that just errors and won't boot to it's BIOS when in the ASRock X370M Pro4 in the Norco. It was in the x16(4x electrical) slot that is highlighted in the picture below, I removed the ASUS video card in that pic. What I could still use help on (from my last post) is picking out the HBA card - 3. The HBA itself, with at least one SFF-8088 external connector. Sounds like it needs to be at least PCIe2.0, SAS 2008. (Could this be a newer PCI33.0 spec x8 card instead? Would it just run at the slower 16gbit/s speed? Thinking a couple years down the road if I replace the motherboard/cpu.) Any suggestions for a card? I do like the Art of Server and would buy something from him on ebay, but am open to other sources. I just would like to have an opinion or two on what to get. CSE-826 case: CSE-826 on top of my Norco RPC-4020 (excuse the dust, I cleaned it later) Inside the Norco case, Asus video card removed. This is the x16(x4) slot.



-
Based on what you all have said I did some revised searching and think I've found more what I'm looking for - Supermicro 826 chassis (12 bays) with a BPN-SAS2-826EL1 or BPN-SAS3-826EL1 backplane. There may be other chassis, but this seems fairly common and parts are available and are on ebay for around $250-300. Art of Server has done a nice explainer on this. Using this second video above it seems a single 8087 cable would be enough using his 2-5-9 rule with 3.5" SATA drives. With a SAS2 backplane, 12 x 2gbit = 24gbit. (At 15 min mark in 2nd video.) Getting to a PCIe HBA to my motherboard - My motherboard has a 1 x PCI Express 2.0 x16 Slot (PCIE3: x4 mode) slot available, so x4 electrical. (I'm using the primary PCI Express 3.0 x16 Slot (PCIE2: x16 mode) for my LSI-9201-16i card for the array in the Norco RPC-4020 chassis. Motherboard is a Asrock X370M Pro4 with a Ryzen 5 3600 (Pinnacle Peak) cpu.) Continuing with his math (15:45 in video), PCIe2.0 = 500mb/s per lane x 4 lanes = 2,000mb/s or x8 to get gigabits = 16 gbit/s total bandwidth. This is a bottleneck, but I'll also never have 12 drives going at max other than parity checks. So for Plex this seems like it should be fine. Does this sound okay? So, to not make this too hacky it seems I would need, in order, starting from the backplane - 1. SFF-8087 cable to a ?? (unknown) rear panel PCI slot connector. (Is this cable directional?) 2. The ?? PCI slot connector cable to the HBA in the unraid server. (Would prefer this inermediate bit so I can unplug the SM 826 case for maintenance instead just a long 8087 cable fron the backplane to HBA.) 3. The HBA itself, with at least one external connector. Sounds like it needs to be at least PCIe2.0, SAS 2008. (Could this be a newer PCI33.0 spec x8 card instead? Would it just run at the slower 16gbit/s speed? Thinking a couple years down the road if I replace the motherboard/cpu.) If this all looks correct so far can anyone help me with part numbers/links for the 3 parts listed above?
-
I searched a bit here and the web and don't quite see if this is a thing - SAS Expander case with a backplane. Maybe I'm using the wrong terminology for my searches. I'm looking to expand my server with more bays - 20 of 20 are full now. I have a old Norco RPC-4020 which is in a rack and I'm happy with it in general. I have a x16 slot open (x4 electrical) and am wondering if there is a setup with an expander card, cable to a second case (rackmount if possible) with 8? +/- drive bays (hot swap/front accessible a plus). A sub question would be can x4 electrical on the PCI-e slot support 4 or 8 drives? Plex is the main use, 98% one user connected. I have a mix of 10/12/16tb drives with 2x16tb parity drives, but would like more storage space without ditching the 10tb drives. Does this exist and can it be done for hundreds $ instead of thousands $$$ ?
-
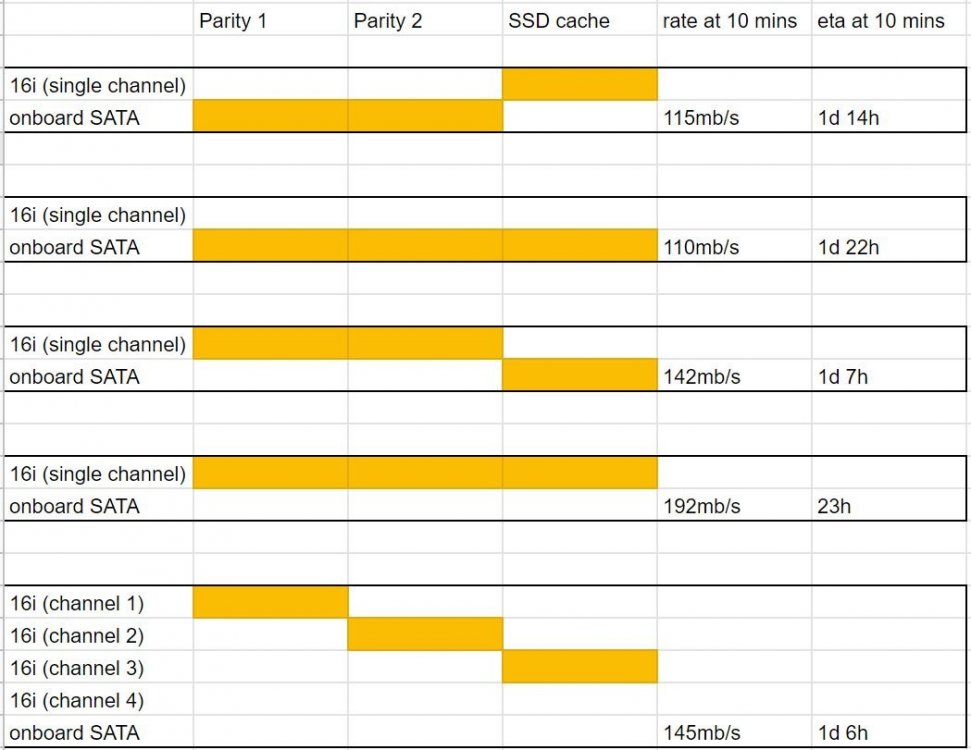
I just upgraded my two parity drives to Toshiba MG08's and did some testing. I previously had the parity and cache on the onboard SATA ports. I tried other combos and now have everything on a single cable (channel) on the 9201. I was surprised that the staggered arrangement wasn't the quickest. I took the rates at 10 minutes in since it seemed like the system had settled into a steady state more or less by then. Motherboard is an ASRock X370M Pro4 and cpu is a Ryzen 5 3600.
-
Thenks Squid! I ran it, no errors and restarted in normal array mode and everything looks to be as it should.
-
Disk is XFS, I restarted in Maintenance mode and ran the check on the disk, result below. I'm at step 2 of Repairing a File System - "Add any additional parameters to the Options field required that are suggested from the check phase. If not sure then ask in the forum. The Help build into the GUI can provide guidance on what options might be applicable." Is it recommended to add any parameters? (Doing this via GUI, btw.) Step 4 notes a -L option. Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... block (7,74328029-74353290) multiply claimed by cnt space tree, state - 2 block (7,74169449-74170249) multiply claimed by cnt space tree, state - 2 block (7,74169449-74170249) multiply claimed by cnt space tree, state - 2 invalid start block 0 in record 51 of cnt btree block 7/2 invalid start block 0 in record 52 of cnt btree block 7/2 invalid start block 0 in record 53 of cnt btree block 7/2 invalid start block 0 in record 54 of cnt btree block 7/2 invalid start block 0 in record 55 of cnt btree block 7/2 invalid start block 0 in record 56 of cnt btree block 7/2 invalid start block 0 in record 57 of cnt btree block 7/2 invalid start block 0 in record 58 of cnt btree block 7/2 invalid start block 0 in record 59 of cnt btree block 7/2 agf_freeblks 207015525, counted 194421230 in ag 7 agi unlinked bucket 39 is 130200423 in ag 7 (inode=15162585959) sb_ifree 8809, counted 8862 sb_fdblocks 576670704, counted 604659013 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 data fork in ino 15040730579 claims free block 1953203817 data fork in ino 15162585949 claims free block 1953077194 - agno = 8 - agno = 9 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 3 - agno = 6 - agno = 1 - agno = 7 - agno = 5 - agno = 4 - agno = 8 - agno = 9 - agno = 2 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... disconnected inode 15162585959, would move to lost+found Phase 7 - verify link counts... would have reset inode 15162585959 nlinks from 0 to 1 No modify flag set, skipping filesystem flush and exiting.






