




egeis
Members
-
Joined
-
Last visited
Everything posted by egeis
-
I updated to the newest docker image yesterday and seeing the slowest indexing of my music collection ever. Now taking minutes for a single folder after being relatively quick through the first 200 folders. Anyone else seeing this behavior?
-
I inserted the SAS HBA and moved all 4 disks to the card. Everything is recognized, parity is being rebuilt. Speeds look good, disks look good.
-
Actually, I'm gonna buy a SAS HBA card and move all the disks to those ports I've already shifted around some SATA ports. Definitely worried that it's the mobo's native controllers causing issues
-
Things were running well for more than 2 weeks. Parity was disabled last night. Any last suggestions before I buy a new Mobo? unraidtower-diagnostics-20211201-2125.zip
-
In the process of trying to rebuild parity using a bigger drive..., it disabled the new parity disk about an hour in. This has now happened 2 times. I changed the connection and it happened again (third time). I think this is a mobo - controller problem. I'm attaching diagnostics in case anyone is interested... but I'm pretty sure I'm just gonna buy a new motherboard. The motherboard I built this with probably wasn't a good choice for Unraid (Asus - X99 TaiChi). I didn't really understand too much about the long-term consequences when I went down this road initially. It's been running since 2017, so I guess it gave me a good 4 years... but these disk problems definitely aren't worth it. unraidtower-diagnostics-20211123-1548.zip
-
It mounted! I may have lost a few things, but I'm super happy I made it through this nightmare. Thanks to you guys!
-
The original disk1 is not readable. I saved a ton of what I needed before I rebuilt the data. Running xfs_repair now.
-
Here's the output. Lots of xfs_repair_output.txt text! I'll rerun with a flag assuming "filesystem flush" is a good thing!
-
When I initially stated my problem, I mentioned that I attempted the first data rebuild on this disk for disk2. Then disk1 was showing failures during that rebuild; It was only done with 60GB (2.6%) 12 hours later. That's when I asked for help. The filesystem probably wasn't empty. I don't think a format would've been pointless.
-
So the format was set on "auto" so there was no "Check Filesystem" dialog. I changed from "auto" to "xfs". The check button appeared with a "-n" flag. I ran that process... there is a LOT of output. It finished with statements about "No modify flag set, skipping filesystem flush and exiting". I can't find anything in the manual/storage management page that makes sense except adding the flag "-L". But I'm not sure I'm looking to do a "filesystem flush"... Appreciative of any guidance.
-
I wasn't going to format it while it was assigned... So it's unmountable. What does this imply for the new disk1? I think I found some documentation suggesting xfs_repair
-
OK... so everything is saying it's done... but I did not format disk 1... cause I thought that would automatically be part of the process... It's currently saying that the new disk is unmountable. I saw this warning... probably should've asked the question before the process began... Not a big deal to lose another 3 hours overnight... assuming the right thing to do is to format and restart. unraidtower-diagnostics-20211115-2056.zip Here, I'm attaching a new diagnostics file. Should I restart the process?


-
I'll let you know. I just backed up a ton of data and I'm ready to start the rebuild. I'm also going to follow the rebuild by cloning the parity drive to a new and larger disk, then move the parity disk in to replace the suspicious disk2. I definitely haven't "knowingly" written new information to the files since the system acted up. If it was operating from an emulated disk for more than 2 months, then what you're saying makes sense. I'll be sure to integrate more monitoring protocols and email updates...
-
I'm on step 8. All disks mounted and there looks to be emulation. I'm copying over some super important stuff before I start the rebuild. So HUGE thanks for getting me this far. Note... maybe I'm a very unaware person, but a few basic text files I was using for keeping records don't look like they're "up-to-date"... last modified date is 3 months ago and I'm pretty sure I made updates to that file in October. Is it possible that modifications would get "missed" from missing a disk? Seems super weird. I'll rebuild the disk as soon as I get some stuff backed up.
-
So I rebooted and all four disks are now able to be allocated... though I still think disk2 is suspect given my previous post. Looking forward to your suggestions of whether I should continue given the previously mentioned errors.
-
Alright... so after running step 3, and looking back at the MAIN menu, disk2 disappeared from the array devices list. It's no longer assigned, and it's no longer in any of the dropdown menus... It is now under Unassigned devices and labeled "sdd", next to the replacement disk for disk1. I have no idea why it says that it is 4.14 GB. It's a 2TB Seagate. I'm afraid it might be the "Hybrid" SSD part of the disk that is the only thing being recognized. Here's a snippet from the disk log:

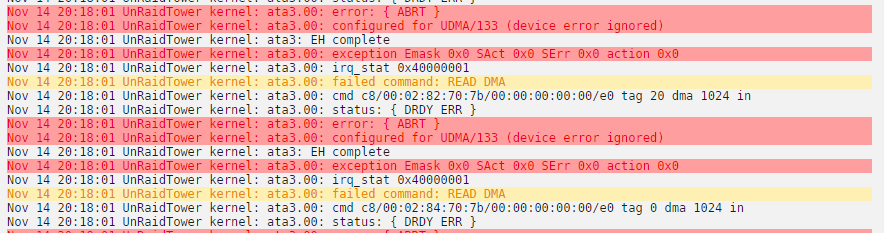
-
Huge Question: I'm on Step 3: "Tools -> New Config" and I'm reading the warning... it is a very scary warning... specifically: "DO NOT USE THIS UTILITY THINKING IT WILL REBUILD A FAILED DRIVE - it will have the opposite effect of making it impossible to rebuild an existing failed drive - you have been warned!" I'm open-minded, so I can absolutely get over the strong wording on that warning, but can you give me a little reassurance that there's a good reason that those words don't necessarily apply to this situation? There is a part of me that is thinking I should take all 4 disks to a data recovery shop before I do anything that could destroy the data on the drives. But I'm willing to give this a shot assuming that the Unraid OS will recognize that the 3/4 disks are already from a previous Parity configuration. By the way, just want to give huge thanks to all of you who support n00bs like us on these forums and work with this software, cause I can't imagine it's easy, and I can't imagine the level of complexity involved in understanding the nuances of running this kind of project. If any of you ever need some help with analytics projects, hit me up!
-
If the original disk 2 is truly out of commission (as I assume given the ❌ that was next to it when I replaced it), what other options exist here? just saw your reply. Reconnecting the original disk 2 now. The new diagnostics are uploaded here. It looks like Unraid is seeing the old disk 2 as a "new device" so I'm very fearful of spinning up the array and then Unraid begins to automate the formatting and syncing process... If this disk happens to still work and has retrievable data, how do I prevent Unraid from going forward with a process to rebuild data?? unraidtower-diagnostics-20211113-2326.zip
-
I have to order a molex-to-SATA power cable. To be continued in 3 days. I hope you’ll still be around!
-
I'll plug in disk 2 and reply again in 20 min.
-
Maybe it was thumbs down, but honestly didn't see it. I only saw it on disk 2. It's definitely yellow thumbs down on disk 1 right now. Definitely got lots of irreplaceable stuff. I was able to access the folder I cared most about and it's empty. This is really really really bad. I have gone over in my head how much of an a** I was to imagine that my backup solution was redundant and to not back things up again. This is literally, the worst possible case situation right now. I spent two months setting up this server to be my redundant backup solution... I saw methods for replacing motherboards, CPUs, etc. etc. Here's the new diagnostics file. unraidtower-diagnostics-20211113-1744.zip
-
Disk 1 had a green balloon and I was not getting any errors via notifications. Every error was referencing disk 2. Until 4 days ago, most everything I run was running just fine, plex, miniDLNA, deluge, couchpotato, nextcloud, etc. etc. When I started looking at data before I did the swap last night, the shares were running SLOW... 5-10 seconds just to display folders at the lowest level. Nothing has been written to the array since I made the swap last night. I can put it back in if necessary. I'm ready to try anything. I'm still in maintenance mode. Hoping to learn how to save whatever I can. This is the updated xfs_repair status Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... xfs_repair: read failed: Input/output error btree block 3/4093184 is suspect, error -117 bad magic # 0 in btcnt block 3/4093184 agf_freeblks 83999918, counted 1229868 in ag 3 agf_longest 68382104, counted 3995 in ag 3 agf_btreeblks 26, counted 25 in ag 3 sb_fdblocks 273855784, counted 191085733 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 xfs_repair: read failed: Input/output error cannot read inode 1098603328, disk block 1001618784, cnt 32
-
Diagnostics attached. Disk2 had an X, so I bought the same size 2TB disk and followed all the directions on https://wiki.unraid.net/Replacing_a_Data_Drive The process began last night and was only 2.6% done the next morning with read errors now occurring on Disk1. I paused the rebuild, shut everything down, I checked all cables, and restarted in maintenance mode. It first said no disks have read errors. I went to disk 1 and ran xfs_repair on disk1. During phase 2 it told me: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... xfs_repair: read failed: Input/output error btree block 3/4093184 is suspect, error -117 bad magic # 0 in btcnt block 3/4093184 agf_freeblks 83999918, counted 1229868 in ag 3 agf_longest 68382104, counted 3995 in ag 3 agf_btreeblks 26, counted 25 in ag 3 sb_fdblocks 273855784, counted 191085733 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 It's still running... Status is now saying "array has errors - Array has 1 disk with read errors" even though it says it passed SMART overall-health. It seems ridiculous that a second HD would fail immediately upon trying to rebuild the first failed one in 3 years. I'm petrified of starting the array and losing my data. And I don't want to kick off the rebuild a second time and cause more problems. Is there anything I can do to attempt to prevent loss of parity by having a second failed disk? unraidtower-diagnostics-20211113-1504.zip
-
Followup... My goal with this docker is to host a dashboard for myself. When I launch a shiny app, It's listening on the localhost. I can use the arguments: > shiny::runApp('FirstApp',port = 3838,launch.browser = FALSE) Listening on http://127.0.0.1:3838 So, I configured the ports as above. When I go to my IP, "http://[IP]:3838", the page won't load... which tells me something else needs to happen. Any ideas what that might be? Alright, so I kept tweeking. When running the app, I need to add the host argument to be the IP address assigned by docker. For example: > shiny::runApp('FirstApp',port = 3838,host = '172.17.0.6',launch.browser = FALSE) Listening on http://172.17.0.6:3838 Then... I go to the address http://[MyUnraidIP]:3838 ... and there's shiny!!
-
Tried to do everything above with the geospatial version. Getting the following error: [1m[31mERROR[39m: You must set a unique PASSWORD (not 'rstudio') first! e.g. run with: docker run -e PASSWORD=[92m<YOUR_PASS>[39m -p 8787:8787 rocker/rstudio (B[m Tried again with tidyverse... same error. I'm gonna add extra parameters to create a password... It worked! Didn't expect to have to use the extra parameters. Anyone doing this, Add under extra parameters: -e PASSWORD='<YourPassword>'






